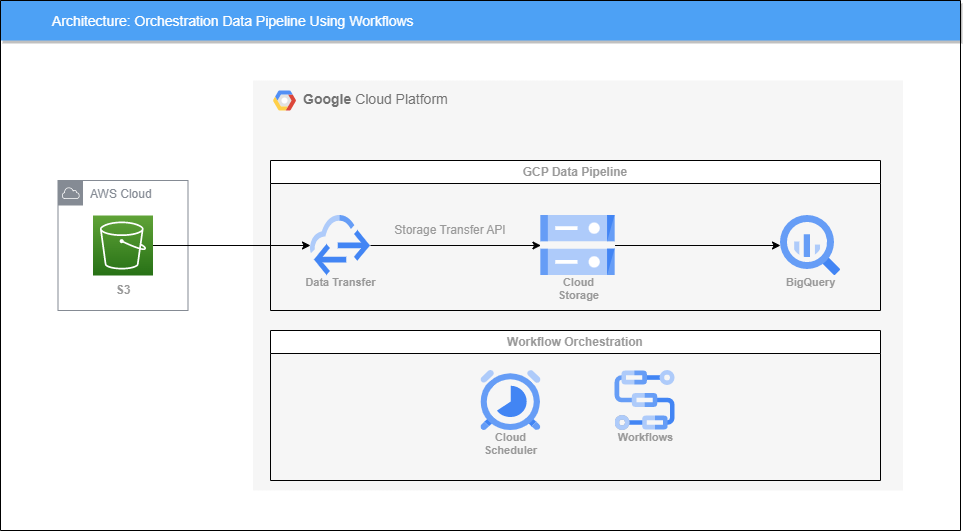
아키텍처
Workflows
GCP의 대표적인 Workflow Orchestration 툴이라고 하면 Cloud Composer(Apache Airflow)를 말할 수 있지만 더욱 저렴한 Workflows라는 서비스가 있다.
Workflows는 짧은 레이턴시의 event-driven 방식을 통해 애플리케이션, 데이터 및 MLOps 파이프라인을 빌드하고 자동화할 수 있는 서비스이다.
왜 비용 효율적일까?
Cloud Composer는 Airflow가 동작하기 위한 GKE 클러스터를 프로비저닝하기 때문에 상당한 비용이 소요되는 서비스이다.
하지만 Workflows는 완전 관리형으로 동작하는 데에 인프라가 필요없고, 유휴 시간에 대해서는 비용을 지불하지 않고 작업을 실행할 때만 비용을 지불한다.
또한 Workflows는 Data Engineer가 아니더라도 Github Action, GitLab Runner와 같은 CI/CD 툴을 사용해본 사람이라면 원리가 비슷해 쉽게 사용할 수 있다.
하지만 아직 서비스 자체가 GA되지 않았고 2023.02.14 기준 서울 리전 지원도 안된다..
미리 Cloud Storage 버킷, BigQuery 데이터 세트를 생성해놓자
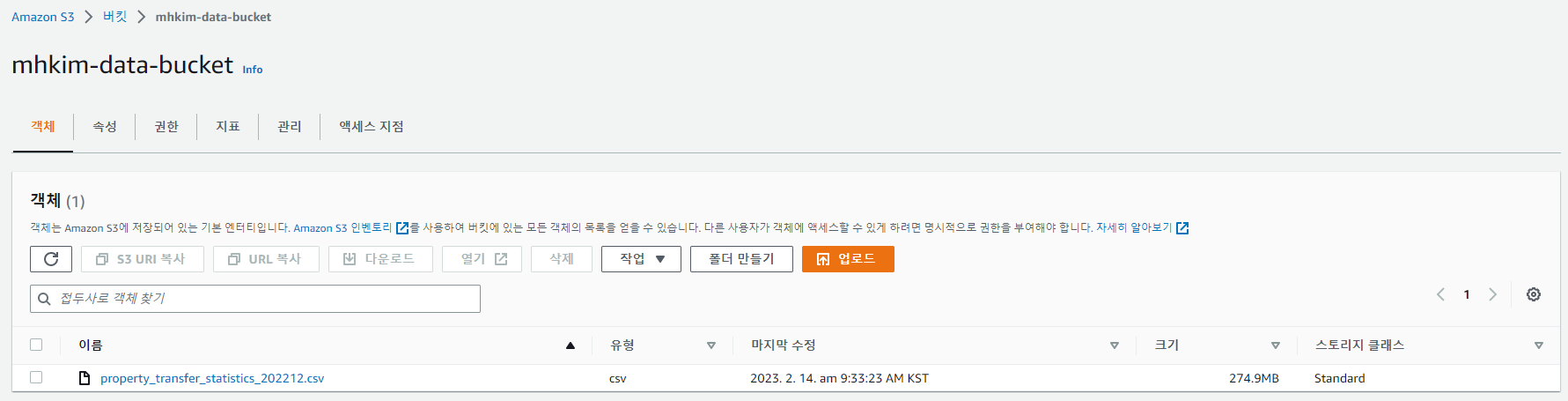
사용할 데이터는 여기서 받아왔다.
Sample CSV file
S3에 데이터 업로드
Data Transfer의 STS(Storage Transfer Service)를 통해 S3 데이터를 가져와서 S3와 Cloud Storage와 S3를 동기화 시킬 것이다.
API 활성화
Transfer Job 만들기

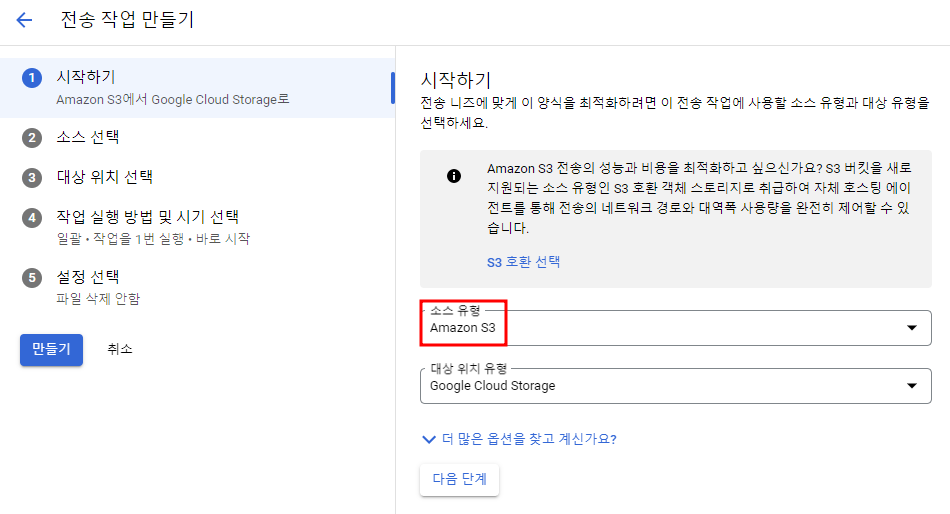
필요한 권한(ex) S3FullAccess)만 부여해준 IAM User를 하나 생성해놓았었다.
해당 User의 access key와 secret access key 입력.
또한 prefix 설정으로 해당 prefix를 가진 파일들을 모두 가져올 수도 있다.
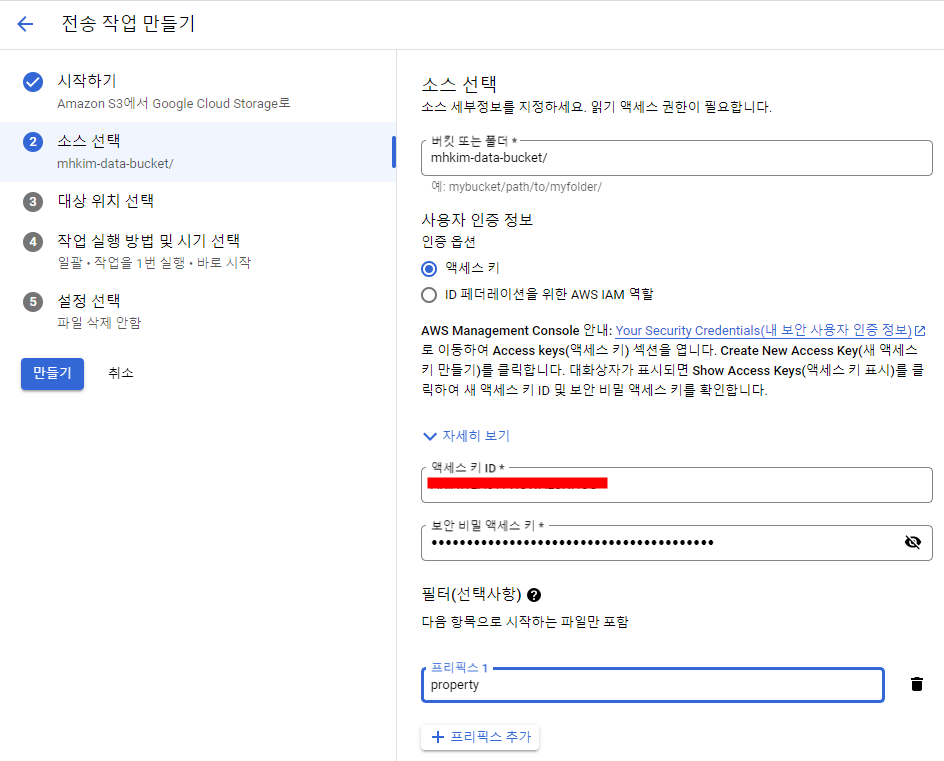
뒤의 설정들은 default로 놔뒀다.
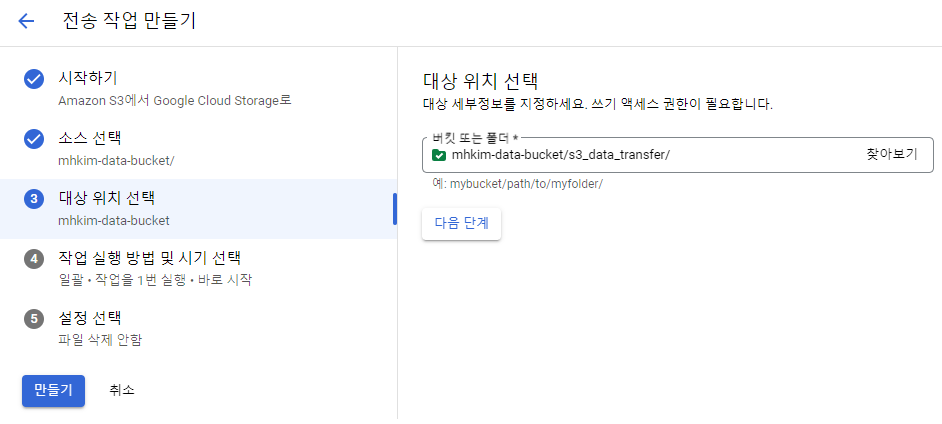
아래와 같은 에러가 날 수도 있다.
(에러가 발생하지 않았다면 Workflows 만들기로 넘어가면 된다.)
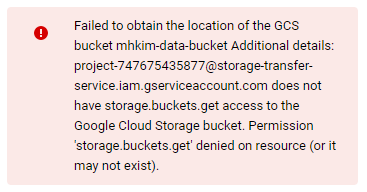
Data Transfer ERROR 트러블 슈팅 참고
내 계정이 Owner, Editor인 거와 상관없이 Storage Transfer Service는 자체적으로 internal service account를 사용하여 S3에 접근한다.
때문에 Storage Transfer Service가 사용하는 service account를 IAM에 따로 등록시켜주고 그에 맞는 권한을 부여해줘야 한다는 것.
googleServiceAccounts.get에서 내 프로젝트 ID를 입력하면 알 수 있다.
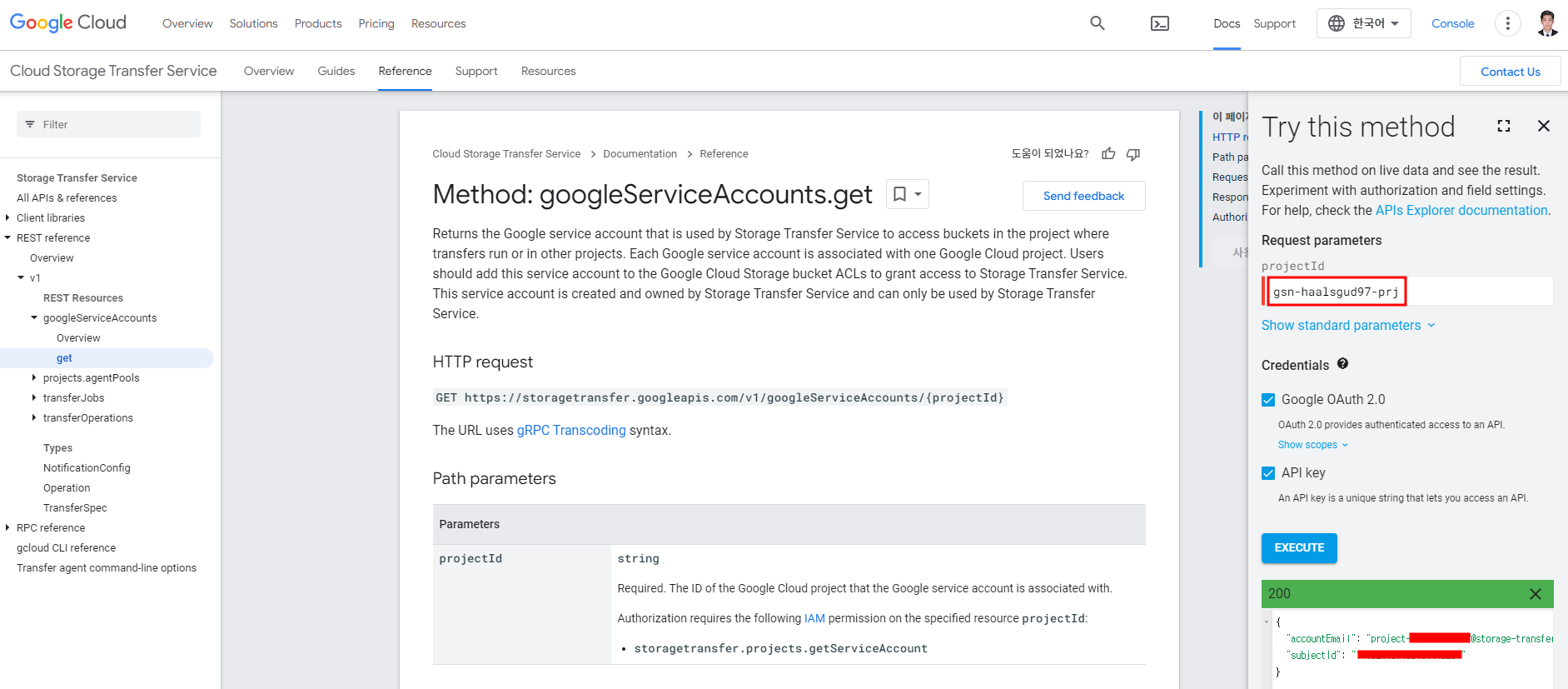
IAM으로 이동해서 위에서 나온 accountEmail에 저장소 전송 사용자 권한을 추가해주면 이제 에러가 나지 않을 것이다.
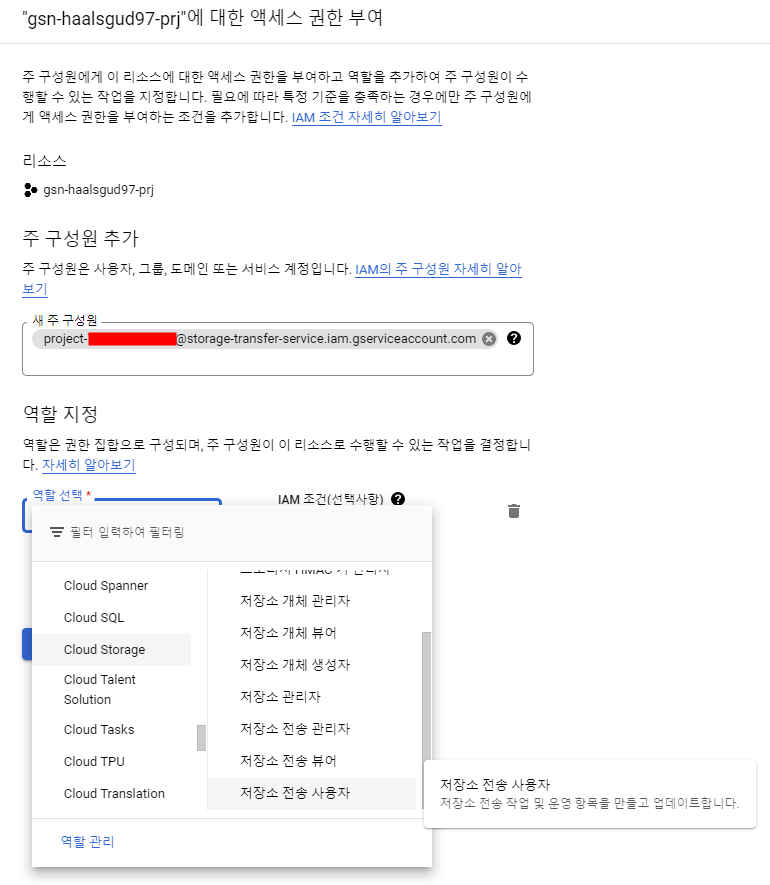
Workflows 만들기
앞서 언급한 대로 서울 리전이 지원되지 않는다.. 도쿄에서 실행
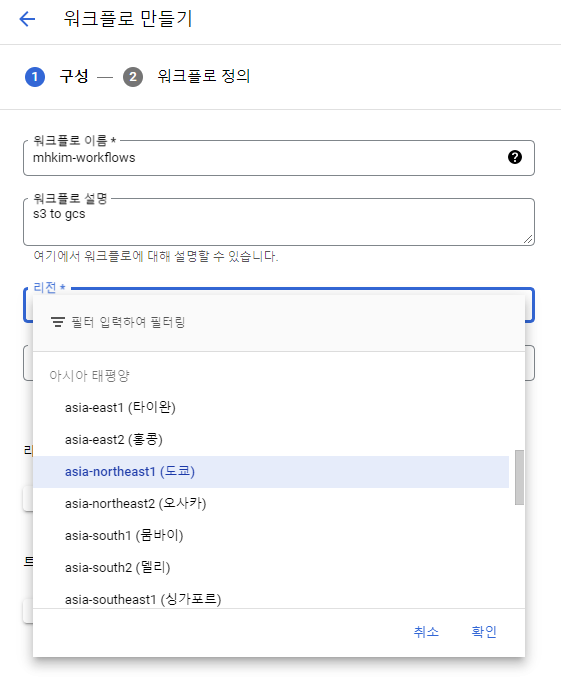
Cloud Scheduler를 트리거 걸어서 원하는 시간에 실행시킬 수 있도록 트리거를 걸 수도 있다.
Workflows 템플릿 작성
main:
params: [input]
steps:
- init:
assign:
- dest_project_id: "<프로젝트 ID>"
- dest_dataset_id: "<데이터 세트 이름>"
- dest_table_id: "<테이블 이름>"
- source_uri: "<소스 파일 URI>"
- transfer_job_name: "<transferJob 이름>"
- run_s3_to_gcs_transfer:
try:
call: googleapis.storagetransfer.v1.transferJobs.run
args:
jobName: ${transfer_job_name}
body:
projectId: ${dest_project_id}
result: transfer_result
except:
as: error
steps:
- log_transfer_job_error:
call: sys.log
args:
severity: "ERROR"
json:
workflow_execution_id: ${sys.get_env("GOOGLE_CLOUD_WORKFLOW_EXECUTION_ID")}
source_uri: ${source_uri}
transfer_job_name: ${transfer_job_name}
target_destination:
projectId: ${dest_project_id}
datasetId: ${dest_dataset_id}
tableId: ${dest_table_id}
sync_status: "FAILED"
error_message: ${error}
- raise_error_to_halt_execution1:
raise: ${error}
- load_data_into_bq_table:
try:
call: googleapis.bigquery.v2.jobs.insert
args:
projectId: ${dest_project_id}
body:
configuration:
# 스키가 있는 테이블을 생성해놨으면 autodetect 주석처리, skipLeadingRows 활성화
load:
createDisposition: CREATE_IF_NEEDED
writeDisposition: WRITE_TRUNCATE
autodetect: True
sourceUris: ${source_uri}
destinationTable:
projectId: ${dest_project_id}
datasetId: ${dest_dataset_id}
tableId: ${dest_table_id}
# skipLeadingRows: 1
result: load_result
except:
as: error
steps:
- log_bq_load_error:
call: sys.log
args:
severity: "ERROR"
json:
workflow_execution_id: ${sys.get_env("GOOGLE_CLOUD_WORKFLOW_EXECUTION_ID")}
source_uri: ${source_uri}
target_destination:
projectId: ${dest_project_id}
datasetId: ${dest_dataset_id}
tableId: ${dest_table_id}
sync_status: "FAILED"
error_message: ${error}
- raise_error_to_halt_execution2:
raise: ${error}
- log_success:
call: sys.log
args:
severity: "INFO"
json:
workflow_execution_id: ${sys.get_env("GOOGLE_CLOUD_WORKFLOW_EXECUTION_ID")}
source_uri: ${source_uri}
target_destination:
projectId: ${dest_project_id}
datasetId: ${dest_dataset_id}
tableId: ${dest_table_id}
sync_status: "SUCCEEDED"
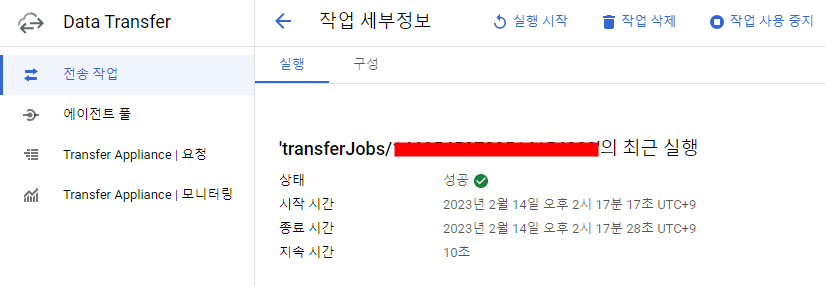
result: ${load_result}transfer_job_name은 아래와 같이 콘솔에서 확인하거나 transferJobs.list에서 프로젝트 ID를 입력해서 확인할 수 있다.
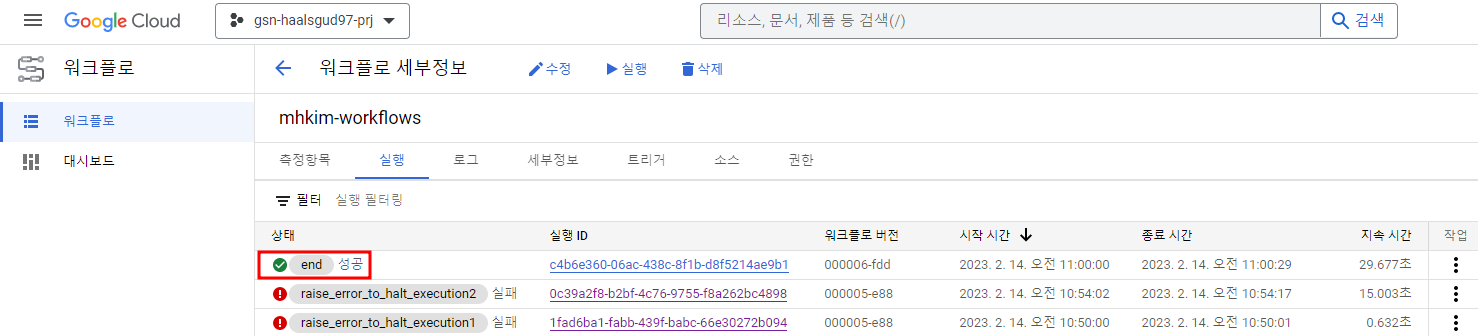
배포
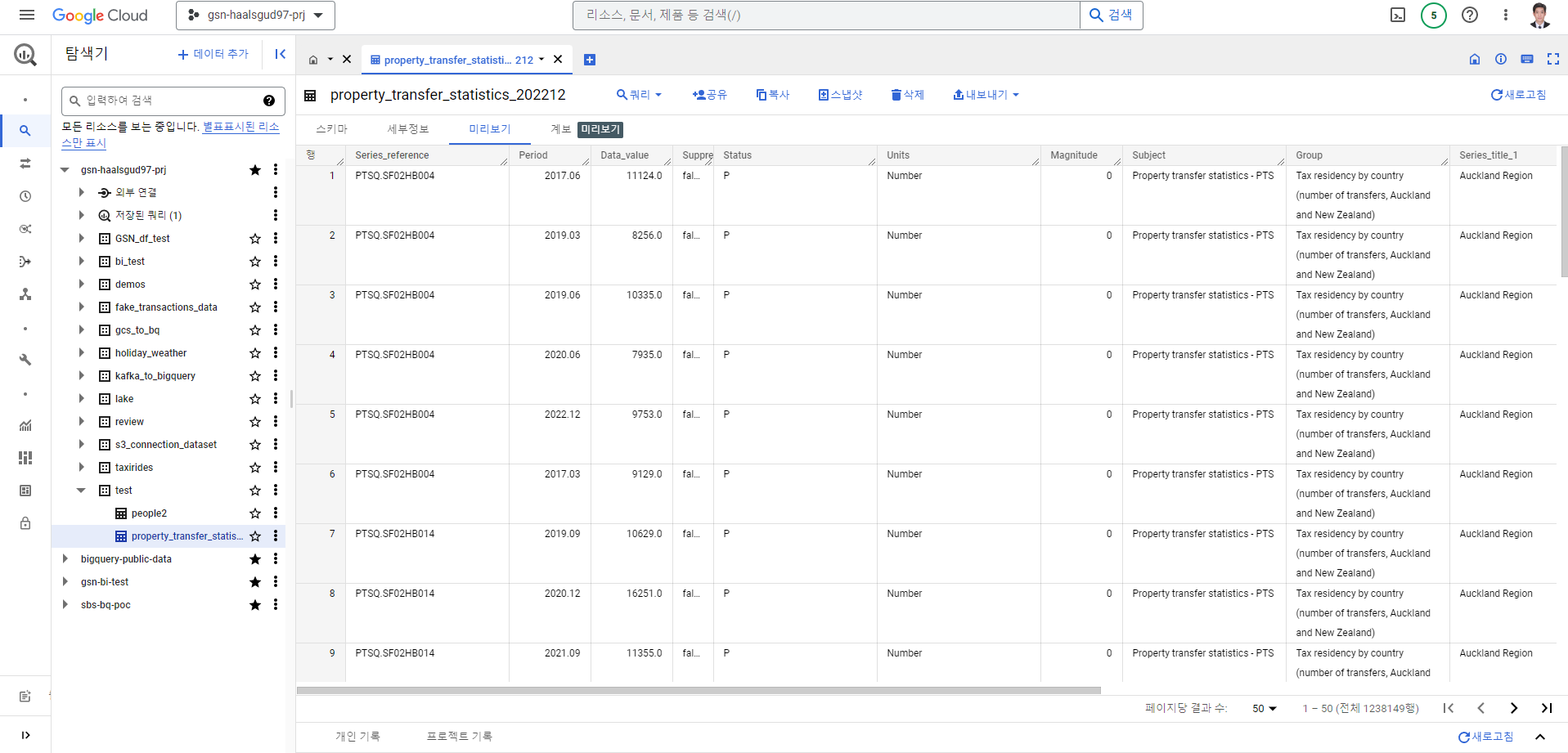
지정한 빅쿼리 데이터 세트에 적재된 것 확인
[Workflows를 사용한 파이프라인 Orchestration 참고]
https://communitytechalliance.medium.com/loading-data-to-bigquery-using-google-workflows-561a44d8852e
