
Model-Free Control
기존 Markov Dicison Process에서는 Environment에 대한 정보가 전부 있었기에, Policy evaluation와 Policy Improvement를 반복하며, 각 state에 대한 value를 바탕으로 최적의 policy를 구하였다.
하지만 model free 상황에서는 어떻게 policy를 결정지을 것인가?
우리는 앞에 RL(4)에서 Monte Carlo Prediction과 temporal Difference를 구하여 Mondel-free의 방식으로 prediction을 진행했었다.
Model Free Control에서도 MDP와 유사하게 Policy evaluation와 Policy Improvement를 반복하며, 최적의 Policy를 찾을 수 있다. 다만 Policy를 모르기에 Q-function을 사용한다.
Q-function (action-value function)의 정의는 다음과 같다.
Q(s,a)는 state에서 특정한 action을 취했을때 얻는 value function이다. 즉 state value function와 유사하지만, action인자가 추가된 것이라 이해하면 된다. 식은 기존에 Monte Carlo Prediction에서 사용했던 Value function에서 Value function을 Value-action Function(Q-function)으로 대체하여 사용한다.
SARSA
해당 Alogrithm에서는 를 사용하므로 SARSA라고도 불린다.
SARSA 알고리즘은 -greedy policy를 사용한다.
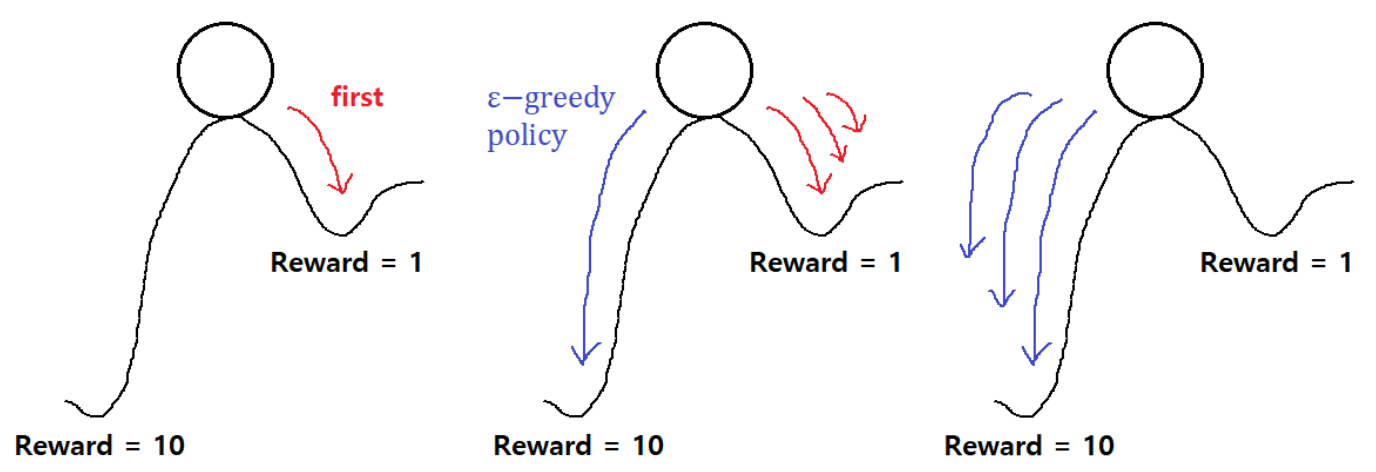
-greedy policy를 사용하는 이유에 대해서 알아야 하는데, environment에 대한 모든 정보를 가지고 있지 않기에, Explore을 진행해야 한다. 따라서 일정한 확률인 확률로 maximum값을 가지지 않는 위치를 탐색한다.
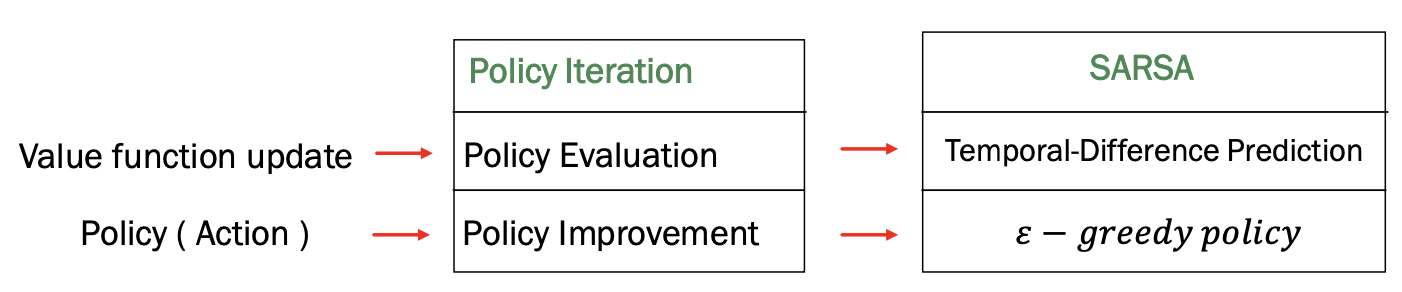
따라서 기존 Policy Iteration와 비교해보면, Valuefunction은 Policy Evaluation을 이용하여 진행하고, Policy 를 update하는것은 Policy Improvement방식을 사용했다면, SARSA에서는 Value function을 구하기 위해서는 Tempral-Difference Prediction을 이용하고, policy를 update하는 과정에서는 -greedy policy를 사용한다.
그럼 SARSA는 문제점이 없을까? 라는 물음에 대답은 "아니요"이다. 그래서 나온 알고리즘이 SARS(Q-learning)이다.
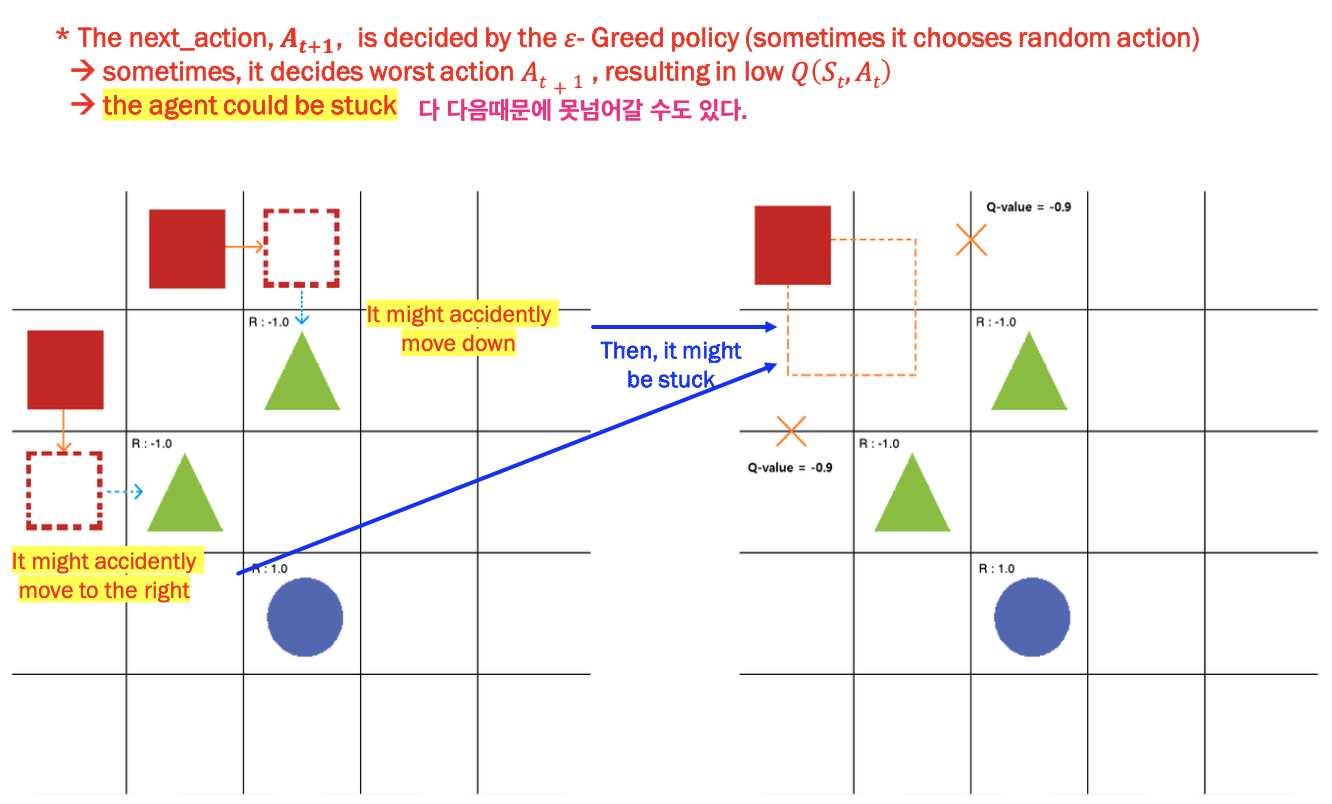
다음과 같은 상황을 보자. 다음 state에 대해서 을 취하면 초록색 삼각형으로 빠질 수도 있다. 이를 방지하고자, 다음 state의 value는 최댓값만을 적용하자는 것이 SARS(Q-learning) Algorithm이다.
