
Reinforcement Learning 정의
사람은 주변의 환경을 통해 상호작용하면서 올바른 답의 방향성을 가지고 나아간다. 이것을 동일하게 적용한 방법이 강화학습이다. 강화학습은 목표 지향(Goal-direction learning)에 초점을 두고 계속 앞으로 나아가며, 해당 목표를 쟁취한다.
이를 정리하면, 순차적인 상황에서 최대한의 보상을 이끌어 내기 위해 방법을 찾는 학습법이다.
Machine Learning의 종류
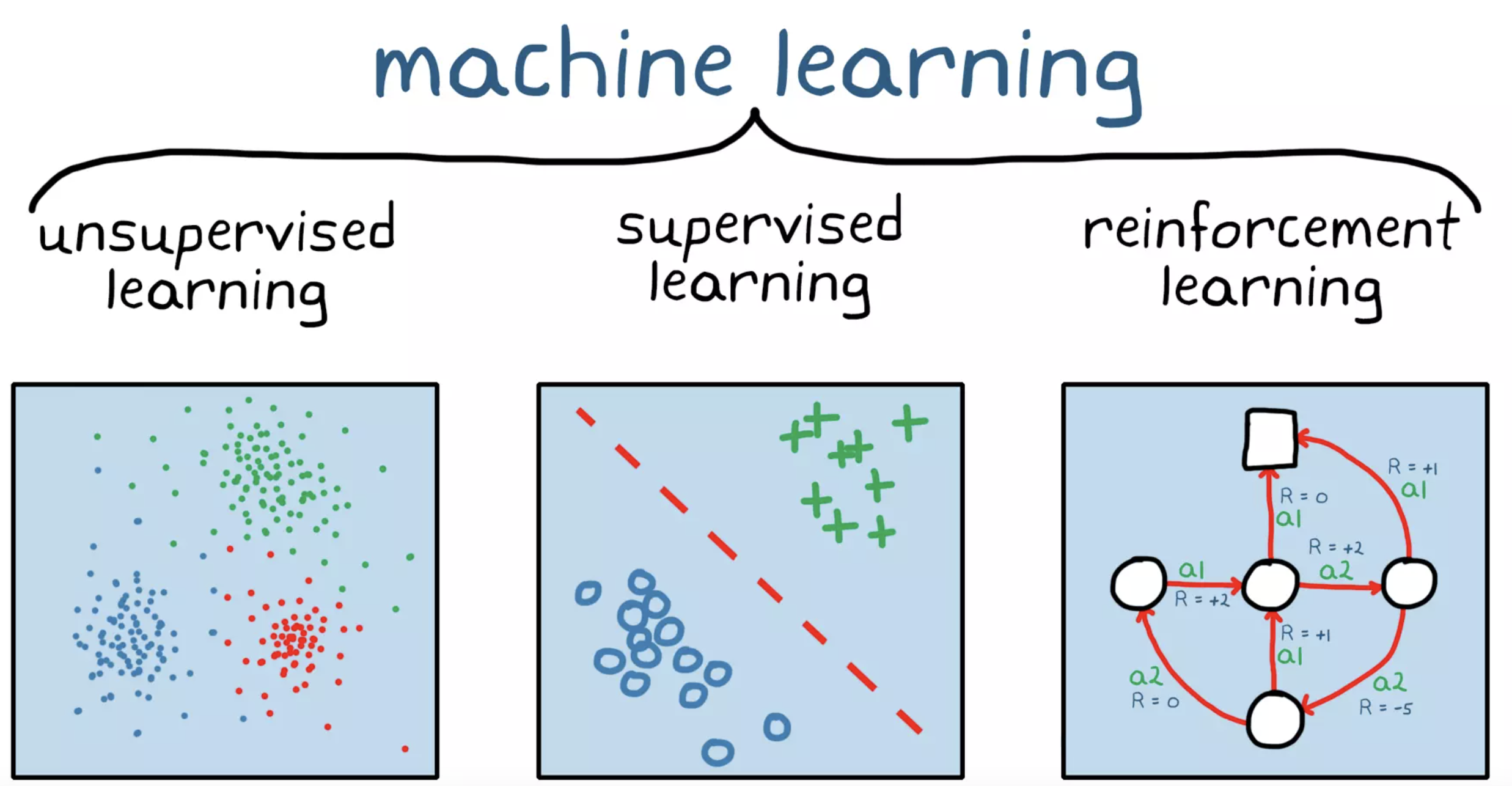
머신러닝은 학습시키는 방법에 따라서 supervised learning, unsupervised learning, reinforcement learning으로 나눌 수 있다.
supervised learning(지도 학습), unsupervised learning(비지도 학습)의 경우 조금 쉽게 이해할 수 있을 것이지만, 이에 반해 reinforcement learning의 경우 이름만 듣고는 쉽게 유추하지 못할 수 있다.
Supervised Learning
지도학습의 경우 데이터에 대한 답(Label)을 준 상태에서 모델을 학습시키는 것이다. 모델은 주어진 답을 바탕으로 가장 동일한 답을 유추할 수 있도록 훈련한다.
대표적인 문제로는 Classification 문제와, Regression 문제가 존재한다.
Unsupervised Learning
비지도학습의 경우 데이터에 대한 답을 주지 않고, 컴퓨터가 스스로 학습을 통하여 답을 낼 수 있도록 한다. 따라서 답을 내는 것이 아닌, 컴퓨터가 스스로 답을 내리는 문제에 주로 사용된다. 특징을 추출하거나, 그룹핑을 하는데 주로 많이 사용된다.
Reinforcement Learning
강화학습은 행동에 대한 보상을 받으면서 어떤 환경 안에서 선택가능한 행동들 중 보상을 최대화 하는 행동 또는 행동 순서를 선택한다.
Reinforcement Element
1. Agent
강화학습에서 학습을 진행하는 주체이다. 환경과 상호작용하며, 행동을 결정하고 그에 따른 보상을 받는다. Agent는 현재의 상태에 대한 선택하는 행동의 기준인 Policy를 가지고 있다.
2. Environment
Agent가 학습하는 환경이다.
3. State
Agent가 환경과 상호작용할때 어떠한 상황에 놓여있는지를 나타낸다.
4. Action
Agent가 다음 state을 선택하는 행동을 의미한다.
첫 State에서는 random action을 취한다.
5. Reward
Agent가 특정한 행동을 했을때 받는 신호이다. Agent는 reward의 누적값이 가장 큰 방향으로 학습을 진행한다.
Reward는 delay될 수 있다. ( 한 게임이 다 끝나야 결과를 알 수도 있기 때문이다.)
t시점의 Reward인 는 scalar feedback이다.
6. History
여태까지 관측한 Observation(O), Actions(A), Rewards(R)를 전부 저장한다. 이를 바탕으로 현지 가 결정된다.
RL의 Major Component
1. Policy
Agent의 행동 패턴에 대한 함수이다. state에서 특정한 action을 취하는지에 대한 정보이다.
Policy는 크게 Deterministic 와 Stochastic Policy로 나눌 수 있다.
Deterministic policy : 해당 state에서의 action을 나타낸다.
Stochastic policy : 해당 state에서 특정한 action에 대한 확률을 제시한다.
2. Value
현재 State의 좋음 / 안좋음의 정도를 제시한다. 즉 현재 State가 어느정도의 reward를 받을 수 있는 상황인지를 의미한다.
여기서 는 discount factor(0,1)로 차후에 받을 보상의 값어치에 대한 가중치를 조절한다.
금리를 생각하면 현재 100만원의 가치가 10년 이후의 100만원의 가치보다 높다고 싱객하면 편하다.
추가적으로 Inf값을 피할 수 있다.
3. Model
다음 Environment(상황(State)와 보상(Reward)) 어떨지 Agent의 예상이다.
다음 state를 예측하는 모델인 Transition model와 다음 reward를 예측하는 모델인 Reward model이 존재한다.
Transition model :
Reward model :
Markov Decision Process, MDP
Markov Decision Process, MDP는 RL을 이루는 가장 핵심적인 요소이다.
Markov Process
마코브 프로세스의 랜덤 상태 들의 sequence이다. sequence는 유한개로 정의된다.
로 표현된다.
현재 상태는 과거의 모든 정보들을 통해 나온 결과물이므로, 미래를 예측하기에 현재 상태가 충분히 많은 정보를 포함하고 있다.
그래서 미래를 예측할때는 현재 상태만을 이용하여 미래를 예측하고, 미래는 과거와 독립적이라고 얘기를 한다.
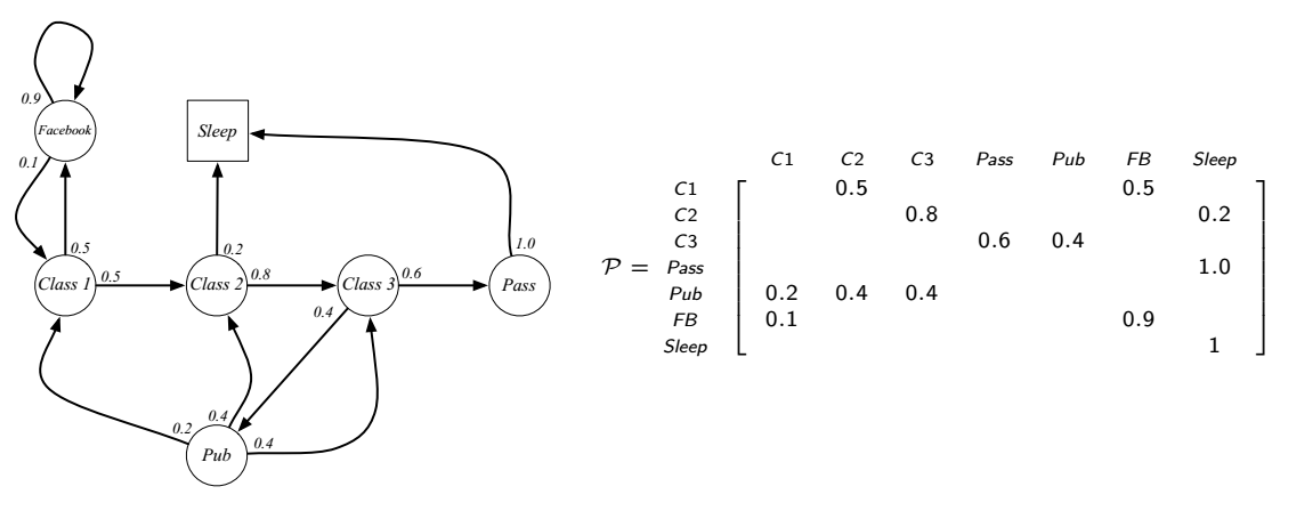
우리는 현재 State s에서 미래 State인 s' 을 행렬로 나타낼 수 있다.
다음 그림을 보면 과거에 무엇을 했는지는 중요하지 않고, 기억도 하지 않는다. 단지 현재 상태만을 보고, State를 랜덤하게 선택한다.
Markov Reward Process
앞에서 본 Markov Process에 values(가치)라는 개념을 추가하여 생각한 것이 Markov Reward Process이다.
이의 가치를 판단히 위해 두가지 개념이 추가되는데, 하나가 Reward(보상)이고, 다른 하나가 discount factor(할인율)이다.

각각의 State에 대한 Reward값을 작성한 것을 확인할 수 있으며, Pass를 했을때 Reward가 +10으로 가장 높은 것을 확인할 수 있다. 그런데 할인율을 곱해주는 이유는 위에서 설명한것과 마찬가지로, 미래 가치를 현재 가치로 환산하는 것이라고 생각하면 된다.
추가적으로 너무 먼 미래의 보상의 경우 0의 값에 수렴하기에, 너무 먼 미래의 보상은 반영하지 않는 것이라 생각할 수 있다. 즉 유한개의 보상에 대해서만 생각한다.

Value function은 두가지 파트로 분리될 수 있는데, 이때 사용되는 것이 Bellman Equation이다.
우리는 해당 Bellman Equation을 통하여 현재 시점의 Value는 현재 보상과 다음 시점의 value로 표현할 수 있다는 것을 알게 되었다.
이를 이용하여 우리는 dynamic program처럼 분석할 수 있다.
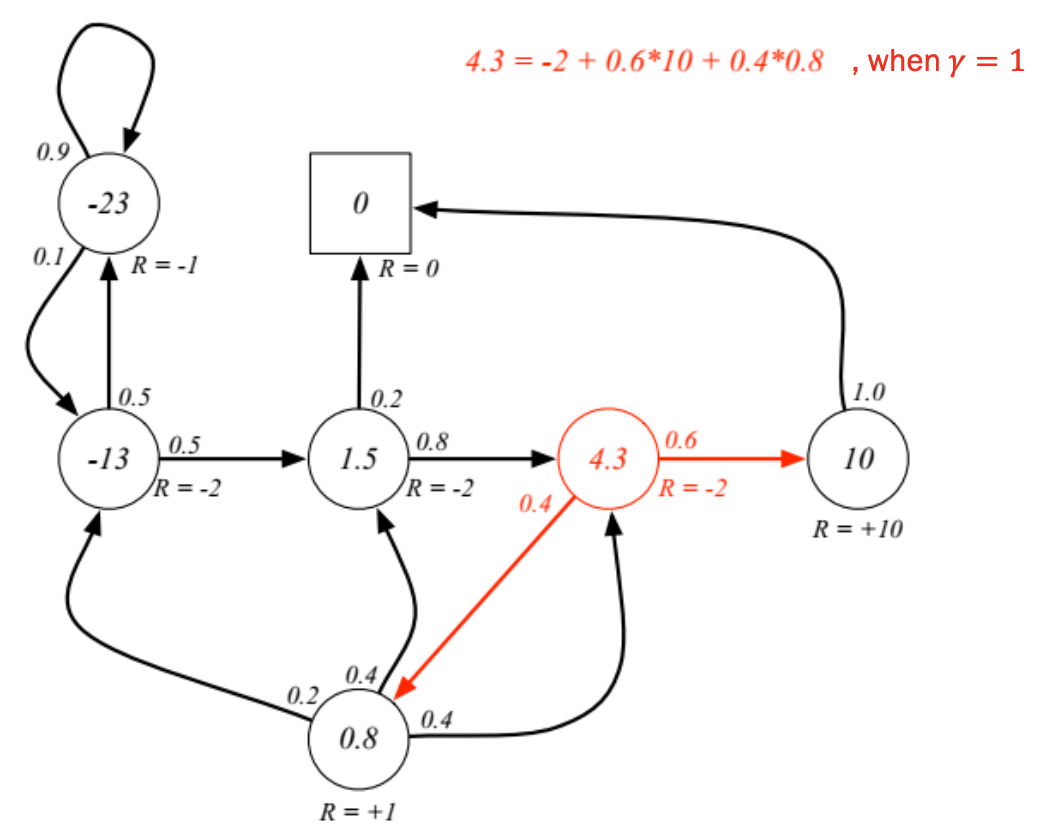
이전 그림의 에서의 값을 구해보면 다음과 같다. 값인 -2가 가장 먼저 더해지고, 이후 에 해당하는 , 에 해당하는 값인 이 더해진다.
이 값이 의 Value값이다.
Reference
