
지난번 친구의 엔씨소프트 주식 나락사건에 이어서 친구가 정신을 못차리고 주식을 추천해달라고 했다. 그래도 나는 내 친구가 잘 되었으면 좋겠어서 요즘 배우고 있는 딥러닝을 사용해서 내가 추천할 주식이 나락을 갈지 떡상을 할지 예측을 해 보았다!!
주식 선정 📌
친구에게 추천할 주식은 편차가 크지 않고 많은 사람들이 투자하고 있는 종목 삼성전자로 선택했고 본격적으로 주가 예측을 시작 하겠다.
딥러닝 모델 선정
예측을 하기 위한 딥러닝 CNN, RNN, GAN, RL등.. RNN의 모델중 예측하는데에 가장 적합하고 편리한 LSTM을 사용해 보았다
주가 예측 전 기본 지식🤔
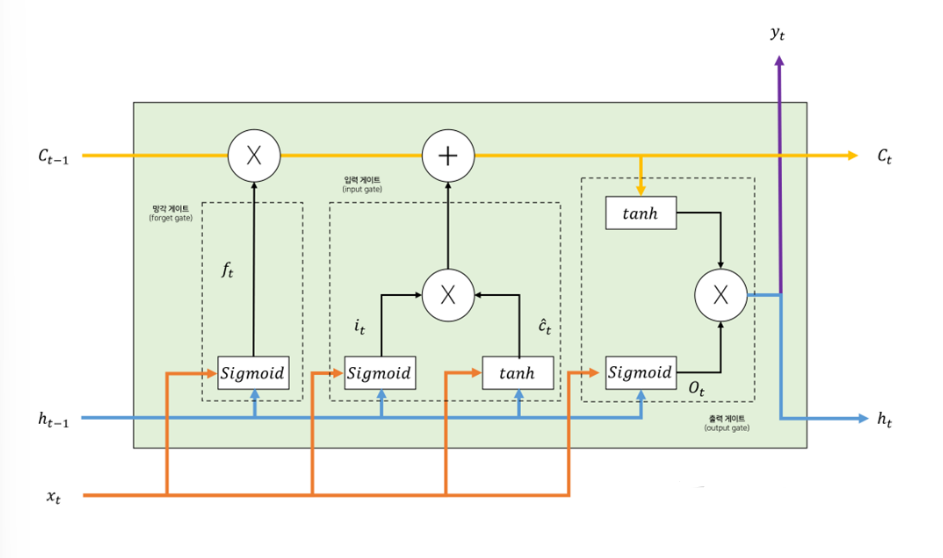
LSTM이란?
LSTM은 RNN(Recurrent Neural Network)의 그래디언트 소실 문제를 해결하기 위해 고안된 모델이다. LSTM은 이전 정보를 오랫동안 기억 할수 있는 메모리 셀을 가지고 있고, 이를 통해 긴 시퀸스 데이터를 처리할 수 있다
LSTM의 기본 구조
LSTM의 메모리 셀은 입력값과 이전 상태에 따라 값을 업테이트 하고, 새로운 상태를 출력한다. 그러나 차이점은 셀의 값을 얼마나 기억할지 결정하는 것이 가능한 게이트를 가지고 있어서 필요한 정보만 기억하도록 제어할 수 있다.
밑 그림을 보면 이해하기 편하다
코드 🪄
1. 현재 폴더 경로 확인
import os
os.getcwd()2. 필수 모델 임포트
import math
import matplotlib.pyplot as plt
import keras
import pandas as pd
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
from keras.layers import *
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
from keras.callbacks import EarlyStopping3. 에측할 주식 선정
df=pd.read_csv("sample_data/SAMSUNG.csv")
print('Number of rows and columns:', df.shape)
df.head(5)4. 데이터셋 가공
training_set = df.iloc[:1000, 1:2].values
test_set = df.iloc[1000:, 1:2].valuessc = MinMaxScaler(feature_range = (0, 1))
training_set_scaled = sc.fit_transform(training_set)
X_train = []
y_train = []
for i in range(60, 1000):
X_train.append(training_set_scaled[i-60:i, 0])
y_train.append(training_set_scaled[i, 0])
X_train, y_train = np.array(X_train), np.array(y_train)
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))5. 학습 시키기
model = Sequential()
model.add(LSTM(units = 50, return_sequences = True, input_shape = (X_train.shape[1], 1)))
model.add(Dropout(0.2))
model.add(LSTM(units = 50, return_sequences = True))
model.add(Dropout(0.2))
model.add(LSTM(units = 50, return_sequences = True))
model.add(Dropout(0.2))
model.add(LSTM(units = 50))
model.add(Dropout(0.2))
model.add(Dense(units = 1))
model.compile(optimizer = 'adam', loss = 'mean_squared_error')
model.fit(X_train, y_train, epochs = 100, batch_size = 32)6. 데이트 세트를 이용하여 예측
predicted_stock_price = model.predict(X_test)
predicted_stock_price = sc.inverse_transform(predicted_stock_price)7. 데이터 시각화
plt.plot(df.loc[1000:, 'Date'],dataset_test.values, color = 'red', label = 'Real Samsung Stock Price')
plt.plot(df.loc[1000:, 'Date'],predicted_stock_price, color = 'blue', label = 'Predicted Samsung Stock Price')
plt.xticks(np.arange(0,231,50))
plt.title('Samsung Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Samsung Stock Price')
plt.legend()
plt.show()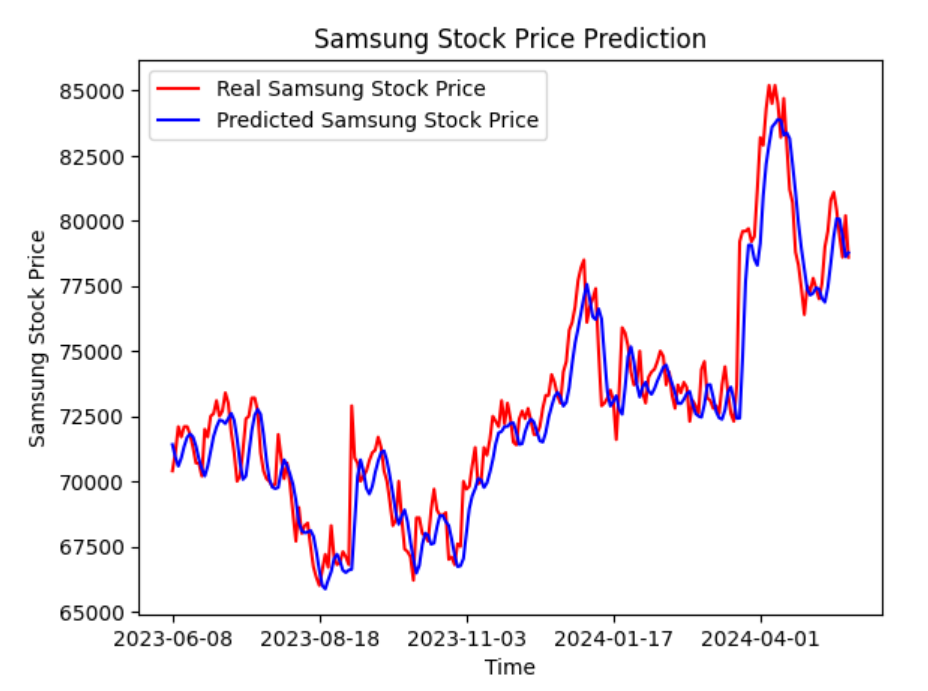
마무리 😀
지금 까지 배운것들로 주가를 예측해보면서 조금 더 다듬고 연습 하면 실제로도 활용해볼수 있어서 신기하고 또 기분이 좋았고 예측한 삼성전자 뿐 아니라 애플, 넷플릭스 등... 많은 주식을 예측해 보면서 좋은 종목을 골라 나도 투자를 한번 해봐야 겠다고 생각 했다.
지금 당장 친구에게 이 그래프를 보여주며 "삼성전자에 한번 투자 해봐"라고 말해줘야 겠다.
