MNIST
MNIST(Mixed National Institute of Standards and Technology)는 손으로 쓴 숫자(0-9)의 이미지로 구성된 대규모 데이터 셋 이다. 이 데이터 셋은 기계 학습 알고리즘과 패턴 인식 시스템을 훈련하고 평가하는 데 널리 사용된다.
그냥 0부터 9까지 의 손 글씨 데이터 셋이라고 보면 될 것 같다.

CIFAR-100
CIFAR-100 데이터 세트는 100개의 클래스로 분류된 60,000개의 32x32 컬러 이미지로 구성된 대규모 컬렉션이다.
복잡한 머신 러닝 및 컴퓨터 비전 작업을 위한 더 까다로운 데이터 세트를 제공한다.

Train/Vaildation/Test set
Train set
- 모델을 학습하기 위한 dataset이다.
Validation set
- 학습이 이미 완료된 모델을 검증하기 위한 dataset이다.
Test set
- 학습과 검증이 완료된 모델의 성능을 평가하기 위한 dataset이다.
Computer Vision
컴퓨터가 디지털 이미지나 비디오에서 유용한 정보를 자동으로 추출하고 분석하며 이해하는 것을 목표로 하는 학문 분야이다. 컴퓨터 비전은 인공지능(AI)과 딥러닝 기술의 발전으로 많은 주목을 받고 있으며, 다양한 응용 분야에서 활용되고 있다.
대표적인 예 (광학 문자 인식, 이미지 인식, 패턴 인식, 얼굴 인식, 객체 감지 및 분류 등)
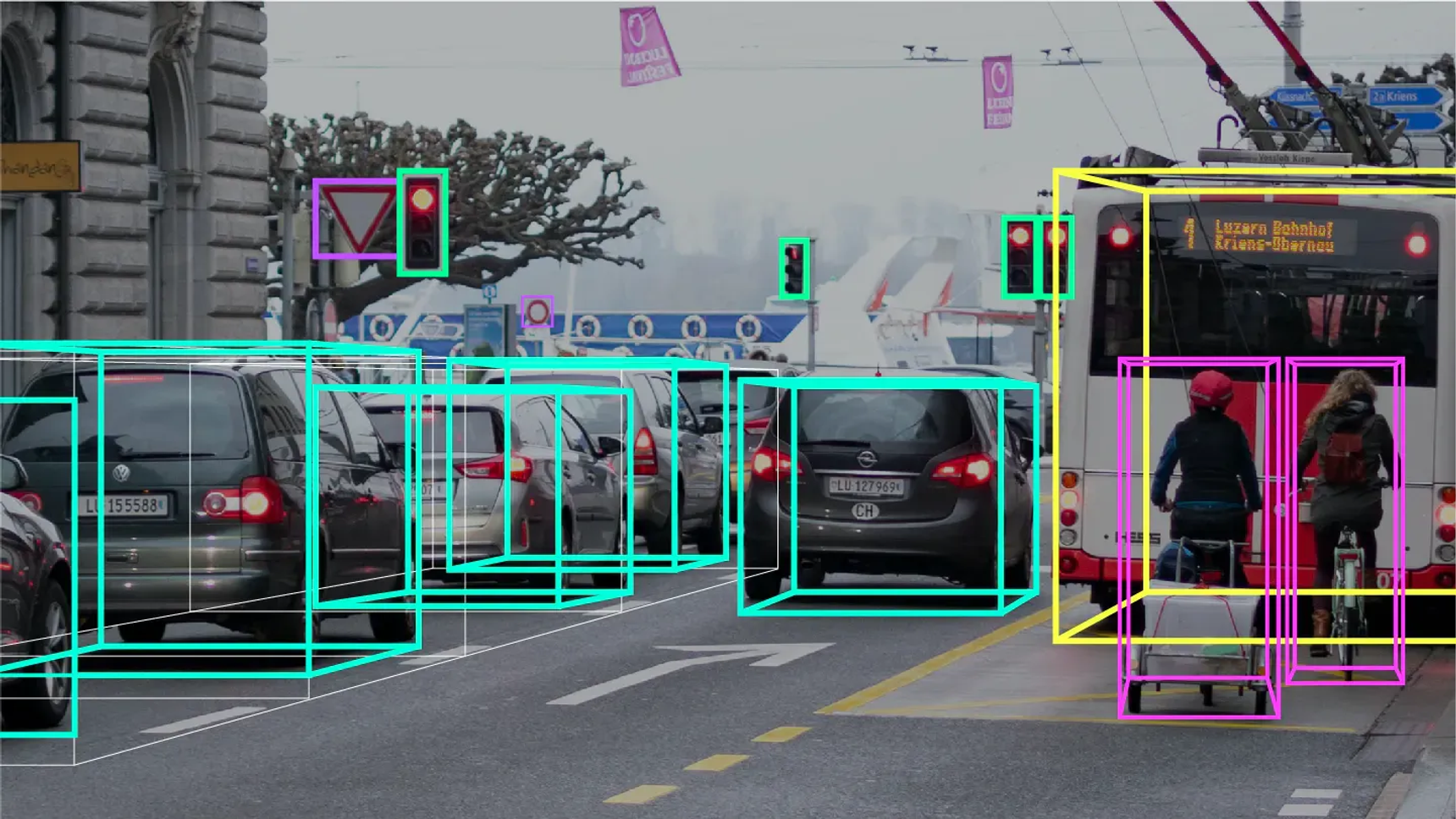
Image Procssing
디지털 이미지를 분석하고 조작하여 원하는 결과를 얻기 위한 기술과 방법을 총칭한다. 이미지 처리는 다양한 응용 분야에서 사용된다.

Computer Graphics
컴퓨터를 사용하여 이미지를 생성, 조작, 저장 및 표시하는 기술과 방법을 연구하는 학문 분야이다. 컴퓨터 그래픽스는 예술, 엔터테인먼트, 과학, 공학 등 다양한 분야에서 널리 활용된다.