이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.
Optimization
이 글에서는 최적화Optimization에 관련된 용어들의 주요 concept을 알아보도록 하자.
Generalization
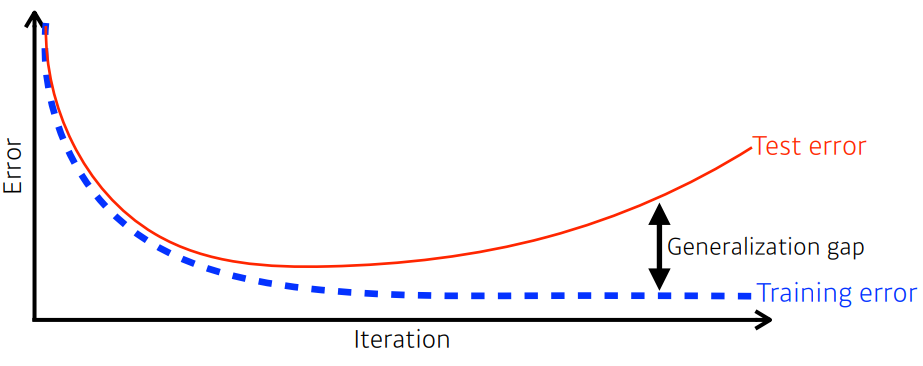
모델이 test data에도 얼마나 잘 적용되는지 보여주는
일반화 성능으로 그래프의
Generalization gap이 일반화성능의 척도가 된다.
단 Generalization이 잘됐다고 항상 좋은 것은 아니다.(train 성능이 않 좋은 경우)
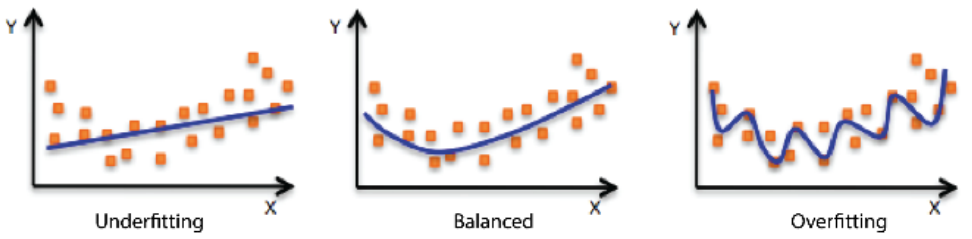
Underfitting vs Overfitting
Underfitting: 그냥 학습이 안된 상태(train->bad/test->bad)
Overfitting: train은 학습이 잘되었으나, test에 적용이 잘안되는 상태
(train->good/test->bad)
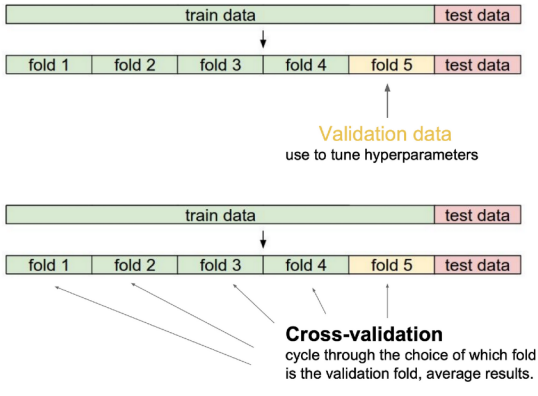
Cross-validation(= K-fold validation)
학습데이터에서 일정 비율을 나누어 학습에서 쓰이는 test로 사용하는 방법으로 n개의 partition이 있을 때, n-1번의 학습을 하게 된다.
단,test data는 학습에 절대 활용하지 않는다.
일반적으로 최적의하이퍼 파라미터set을 찾기위해 사용 후,전체 학습데이터를 사용하여파라미터를 학습한다.
Bias and Variance
Bias: 비슷한 입력을 받았을 때 출력의 평균이 한쪽으로 편향됨을 의미
Varience: 비슷한 입력을 받았을 때 출력이 얼마나 퍼졌는가를 의미
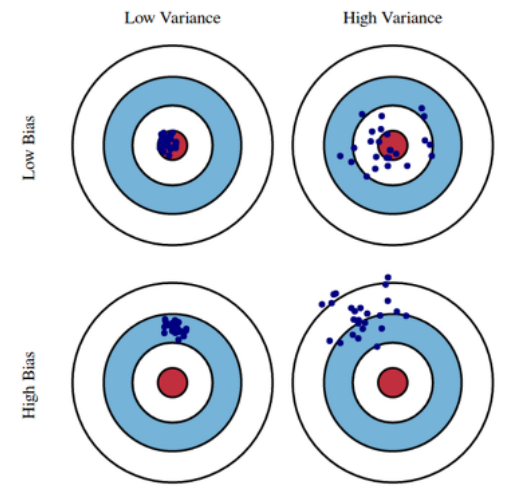
재미있는 것은
Bias와Varience사이에Tradeoff가 있다는 점이다.
cost function은Bias,Varience,Noise3개의 항으로 나누어질 수 있는데(Noise는 있다고 가정시)
식을 보면Noise를 제외하면cost function에 대해서Bias,Varience는trade off관계인 것 을 볼 수 있다.
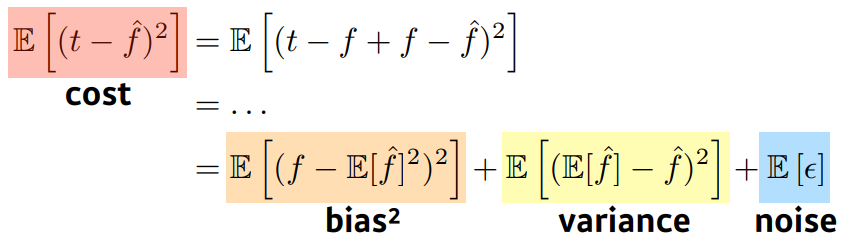
Bootstrapping
신발끈을 들어서 하늘을 날자!
Bootstrapping은 고정된 학습 데이터를sub sampling을 통해여러개의 샘플을 통해
여러개의 모델을 만들어 뭔가 해보겠다 라는 의미이다.
Bagging과Boosting의 기초 개념이다.
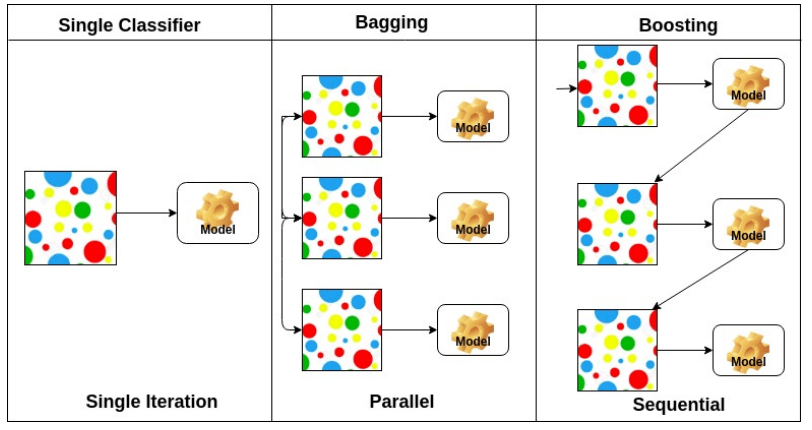
Bagging vs Boosting
Bagging (Bootstrapping aggregating)
단어에서 알 수 있듯이
Bootstrapping으로 나온 모델들을aggregating하는 것이다.
이 때aggregating은 모델들의 결과를voting이나averaging하여 최종 결과를 낸다.
앙상블기법이기도 하다.
Boosting
Boosting은 처음에간단한 모델(weak learners)을 만들어 예측한 결과에서 틀린 것들에 가중치를 두어(혹은 틀린것에 대해서만) 모델을 만들고, 여기서 또 틀린 것들에 가중치를 두어 모델을 만들고, . . . . 하는 것 이다.
즉Sequential하게weak learners들을 결합하여strong mdel을 만드는 과정이다.
Bagging vs Boosting