이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.
딥러닝의 Key Component
-
Data: 학습할data -
Model:data를 어떻게 변형(transform)할 것인가 -
Loss Function:model의 error를 정량화 하는 함수 -
Algorithm:loss를 어떻게 줄일지에 대한 방법
논문을 읽거나 모델을 분석할 때 이 4가지를 유의하면 좋다.Neural Network란?
function approximators이다.
즉 임의의 함수에 근접하게 표현하기 위해 입력을 선형변환(가중치) + 비선형변환(활성화함수)로 변환시켜주는 함수이다.
신경망이 잘되는 이유 레퍼토리
옛날에는 "신경망은 사람의 뇌를 닮아서 잘된다" 라는 말이 있었지만 딱히 맞는 말은 아니다.
- 사람의 뇌에서는 역전파를 사용하지 않는다.
- 하늘을 날기위해 새를 모방한다 하지만 제트기와 새는 전혀 닮지 않은 것과 같은 의미이다.또다른 레퍼토리!
1개의 신경망 만으로도 대부분의 continous한 fucntion을 표현할 수 있다.
(단,그런 신경망은 어딘가에는 있다... 찾아봐라...)
-> 신경망의 표현력이 그만큼 좋다는 의미로 받아들이자.Linear Neural Networks
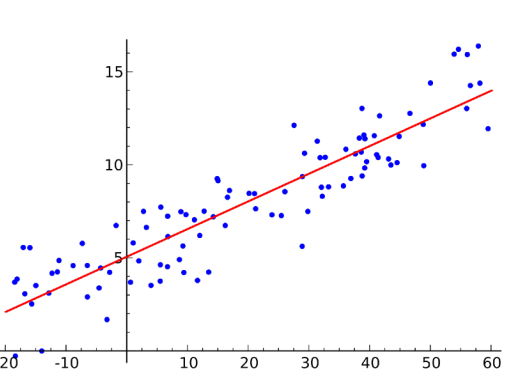
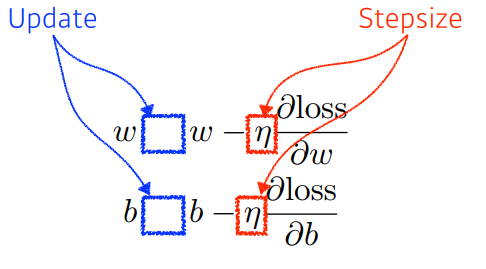
간단한 선형 모델예제를 보자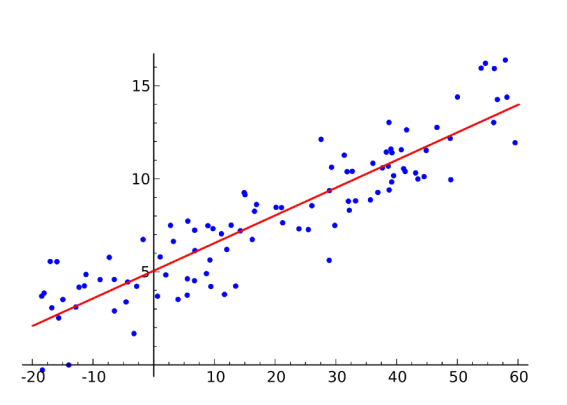
위 그래프를 앞선 4가지 DL key component 관점으로 보면 다음과 같다.
Data:Model:Loss: 로 줄이는게 목적Algoritm: Gradient Descent로 그림의 수식과 같다.
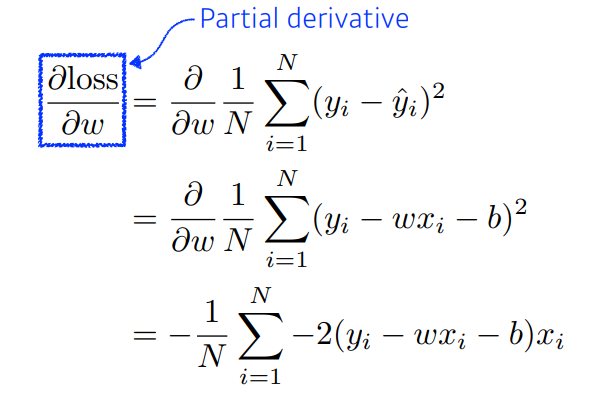
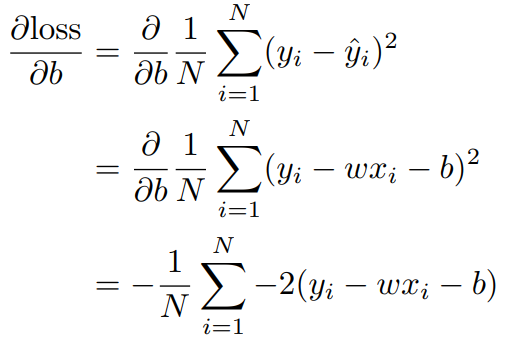
물론 다차원에서도 가능하다.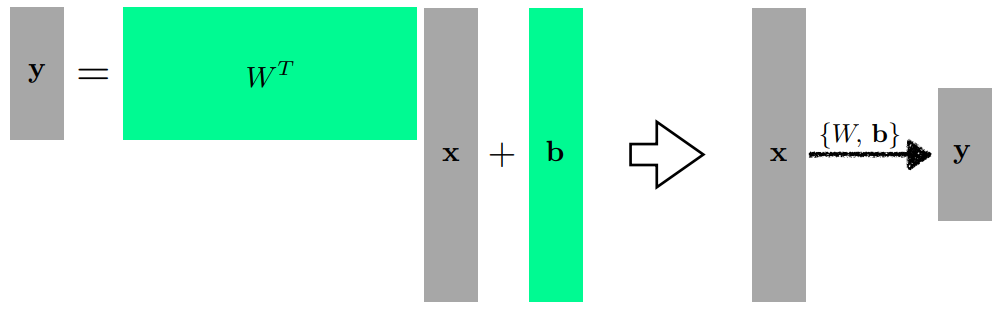
이때 (행렬곱)은 두개의 vector space 사이의 선형변환으로 해석하면 좋다.
더 쌓으면 어떻게 될까?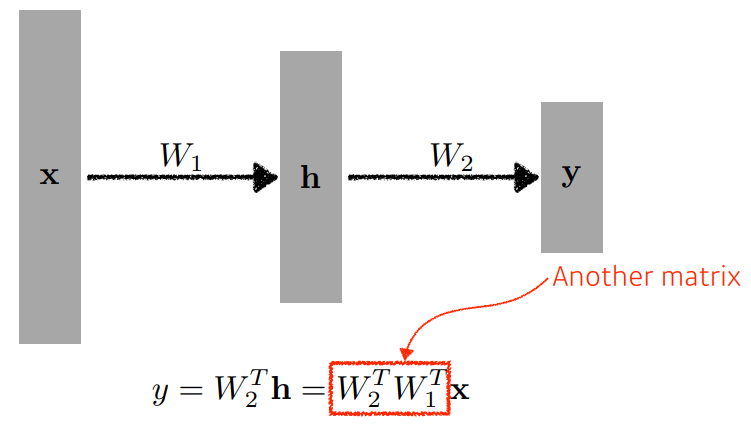
라는 Layer를 쌓아 라는 가중치를 추가하면 그림과 같다.
이때 결과값 를 구하기 위해 입력에 곱해진 는 2번 행렬곱을 했지만,
선형변환에 지나지 않아 1층짜리 NN 과 다를 바 없다.
따라서 네트워크의 표현력을 최대화 하기 위해서는 단순힌 선형결합을 n번 하는 것이 아닌
Activation Function등의비선형 변환을 해야한다.
즉
비선형 변환을 해야 네트워크를 깊게 쌓는 의미가 있다.
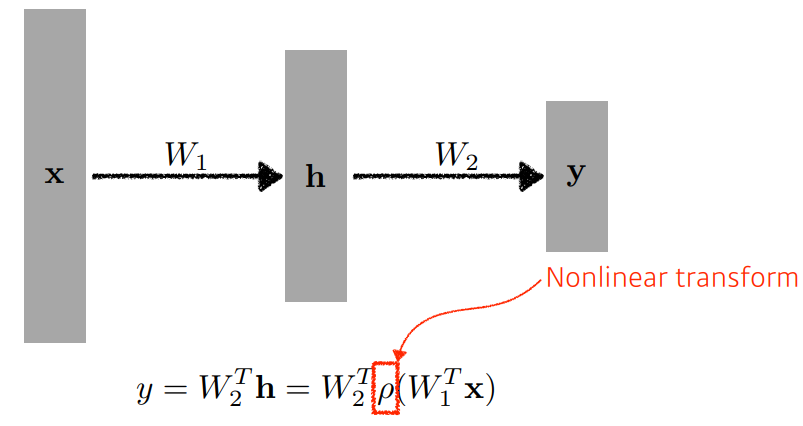
Multi-Layer Perceptron
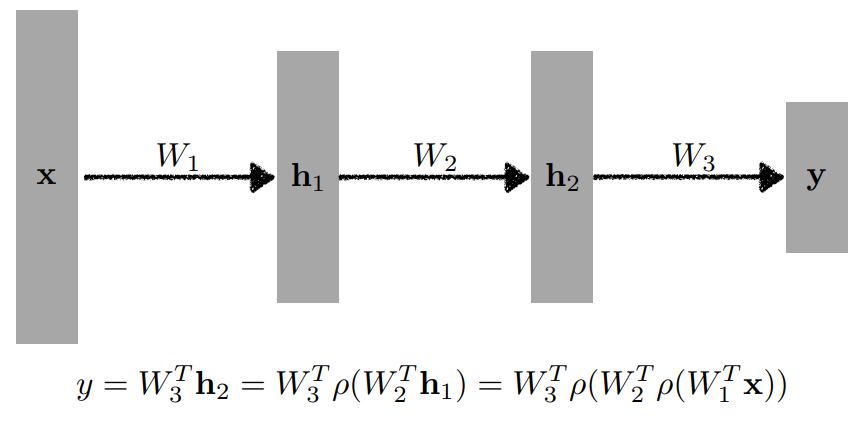
이처럼 선형변환과 비선형변환의 층을 계속하게 쌓게되면 다층 퍼셉트론(Multi-Layer Perceptron)이 된다.

옹오옹오오오옹ㅇㅇ