
이번에 큐시즘X직행 기업 프로젝트를 진행하면서 Naver Cloud Platform에서 크레딧을 지원받아 각종 서비스들을 이용해 프로젝트를 수행한 경험을 공유해보고자 합니다.
프로젝트 소개
우리는 채용 플랫폼인 직행에서 기업 프로젝트를 진행했는데 기존 채용 플랫폼의 딱딱함과 지루함, 정보과잉 속에서 발생하는 피로감을 해결하며 조금 더 신뢰성있는 데이터를 기반으로 차별화된 채용 플랫폼을 만들기 위한 기능을 개발하고자 했다!
기존의 회원가입과 채용공고를 찾기 전 부터 엄청난 정보를 입력해야한다는 것에 사용자들은 부담을 느낀다는 점을 PM님과 면담을 통해 파악하였고,
우리는 "가벼움", "신뢰성"을 함께 주는 기능인 "이스터에그 기반 회원가입"기능을 개발했다.
6문항 정도의 사용자의 성향테스트를 만들고, 그에따라 사용자가 중요시하는 기업이나, 복지와 관련된 정보를 얻는다. 이후 회원가입, 간단한 온보딩(선호 직군, 직무, 학력, 경력, 출퇴근 방법)등의 정보만 얻어 이를 바탕으로 채용 공고를 추천해주는 기능이다.
깃허브 : https://github.com/kusitms32th-zighang-2
활용한 서비스
naver cloud platform에서는 굉장히 많은 서비스를 활용했는데, 이는 다음과 같다
🖥️ 컴퓨팅 (Compute)
- Server (VPC)
🗄️ 스토리지 (Storage)
- Storage
- Object Storage
🛢️ 데이터베이스 (Database)
- Cloud DB for MySQL
🌐 네트워크 (Network)
- VPC (Virtual Private Cloud)
- Global DNS
🔍 분석 / 검색 (Analytics & Search)
- Search Engine Service (VPC)
📦 컨테이너 (Container)
- Container Registry
🤖 AI / 클로바 (AI & CLOVA)
- CLOVA Studio
처음 사용해보는 것이 많았지만, 네이버 문서가 참고하기에 정말 좋아서 공식문서를 정말 많이 활용했던 것 같다.
이중에 단연 가장 많이 사용했던것은 추천 알고리즘을 개발하기 위해 사용했던 Search Engine Service (VPC)와 CLOVA Studio인데, 이를 중심으로 프로젝트에 어떻게 적용했는지 설명해보겠다.
우선, 구성했던 아키텍처를 공유하며 설명을 시작해보겠다.
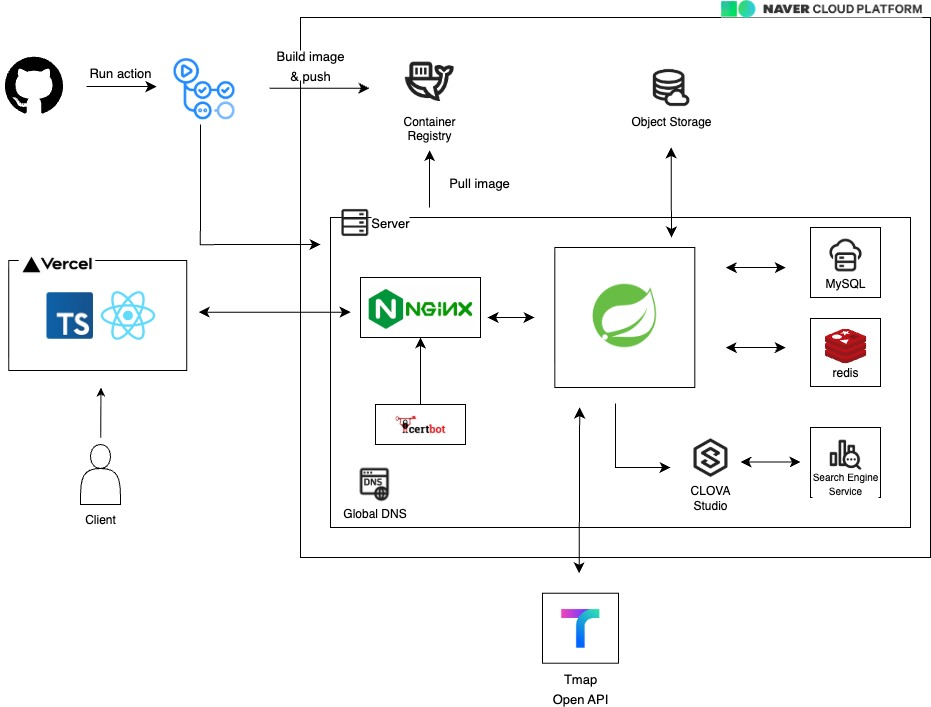
우선 우리는 CI/CD를 기본적으로 구성하기 위해 SERVER, Container Registry등을 사용했는데 AWS에서 할 때는 Docker hub에 올려서 구현을 했었는데 네이버에서는 docker Image를 관리할 수 있는 Container Registry를 사용할 수 있어 편하게 사용할 수 있다는 장점이 있다!
NCP를 이용해 CI/CD 구성하는 방법은 아래 링크를 참조하면 좋을 것 같다.
그리고 대망의 데이터 파이프 라인.
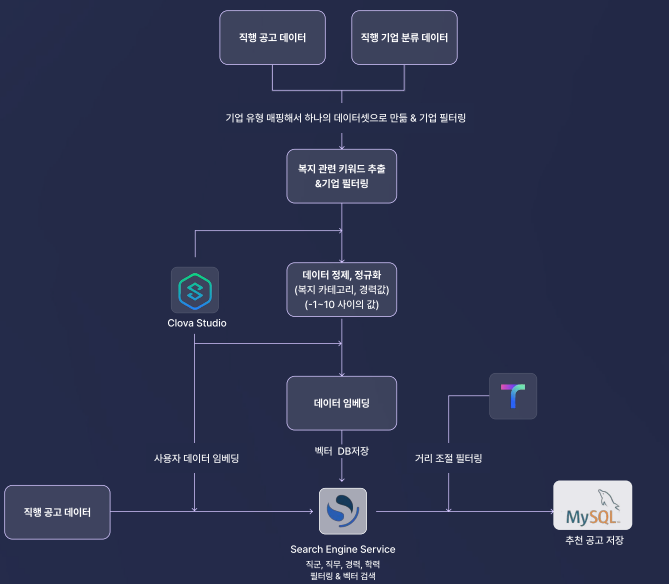
우리는 채용공고 데이터와 기업 분류 데이터를 활용해 하나의 데이터셋을 만들어 이용했다.
이때 유효한 복지데이터가 없는 채용공고와, 기업분류가 제대로 되지않은 기업들을 걸러내는 작업을 진행했다. 정규표현식과 파이썬 코드를 이용해서 구현했는데, 이 과정에서 상당수의 데이터가 줄었다.
실제로 기업 분류 데이터가 완성이 되지 않은 상태라 매핑 된 기업이 많이 없었다.
이 작업은 꼭 필요했는데, 복지와 관련된 내용들을 Naver Clova X를 이용하여 전처리하려고 했고 그 과정에서 복지 데이터가 없거나, 기업 규모 매핑이 되지 않은 데이터를 걸러내어 최소한의 비용으로 이용하려고 했기 때문이다.
이후에는 데이터 임베딩을 진행했는데, 이렇게 전처리된 복지 텍스트를 Naver Clova X를 이용하여 임베딩 했고 하나의 컬럼으로 저장했다. 이때 벡터 DB는 Search Engine Service를 이용했다. opensearch 기반의 서비스 여서 openSearch API가 모두 지원되었고, knn벡터 검색도 쉽게 활용 할 수 있었다 !
이렇게 데이터를 전부 벡터 DB에 저장한 후,
이전에 성향 테스트에서 받은 복지 관련 데이터들을 임베딩하여 사용자 쿼리를 만든다. 이때 사용자가 원하는 직군, 직무, 학력, 경력등을 필터링 조건으로 넣어 쿼리를 구성하고, openSearch API를 이용하여 유사도 검색을 진행한다.
이후 가져온 후보 채용 공고들을 Tmap API를 이용하여 출근 수단, 출근 시간에 맞는 데이터만 걸러 DB에 저장한다 (이 과정에서 비동기 처리를 하기도 했다)
** Tmap API 필터링의 자세한 과정은 다음과 같다.
- 보군 내 회사 주소 확인
- Tmap API 호출 → 출퇴근 시간 계산
- 대중교통: (월요일 오전 9시, 사용자가 설정한 출발시간) 기준으로 계산
- 승용차: (월요일 오전 9시 도착 기준)으로 계산
- 사용자가 설정한 출퇴근 시간 이내 공고만
Ncloud 사용에 대한 소감
이번에 내가 AI쪽을 담당해서 RAG를 구현했는데, 솔직히 정말 막막했다. 베이스가 1도없고 벡터DB, 임베딩, 뭐 프롬프트 엔지니어링 등등 처음부터 공부하느라 정말 힘들었다. 근데 이번에 Clova X 사용하면서 내부에 있던 설명들 (특히 단어에 대한 설명들), AI를 활용하기 위한 소스코드 예시, 프롬프트를 어떻게 짜야하는지에 대한 예시, RAG를 구현하기 위한 자세한 글 등 처음 사용하는 사람들에게 정말 친절한 플랫폼이라는 생각이 들었다.
참고로 RAG 알고 싶은 분들은 아래 글 참조하면 도움이 될것이다.
✔️(1부)RAG란 무엇인가 : https://www.ncloud-forums.com/topic/277/
✔️(2부)RAG 구현 방식 알아보기 : https://www.ncloud-forums.com/topic/283/
✔️(3부)CLOVA Studio를 이용해 RAG 구현하기 : https://www.ncloud-forums.com/topic/307/
naver에서 공식적으로 RAG에 대한 설명을 적은 것 인데, 이후 3편 까지 난 아주 많은 도움을 받았다. 감사합니다 !!!!
아쉬웠던 점은 딱히 없었지만,,
비용이 좀 비싸다? Search Engine Service 같은 경우에는 하루에 몇만원씩 지출되는 것 같았다. 혼자 개발한다면 상당히 부담이 될 수 있는 금액이라고 생각했다. (내가 못쓰는 것일 수도 있어요..)
Clova X는 데이터 전처리, 프롬프트 커스텀등 비용을 줄일 수 있는 방법이 많기 때문에 문제가 되진 않을 것 같다!!
마지막으로, Green Developers 프로그램을 큐시즘을 통해 참여하면서, 프롬프트 엔지니어링, RAG등 AI와 관련된 기술을 공부했던점이 너무너무 좋았다. 백엔드를 공부하면서 이것만 하면 살아남지 못할 것이라는 생각을 자주 했는데, 데이터 파이프라인을 직접 구성하고 공부해보면서, 데이터 엔지니어링에도 관심을 갖게 된 좋은 계기가 되었다.
RAG를 구현하고 싶은 분들 모두 NCP를 사용해서 쉽게 공부하고 구현하길 바란다.
마무리
좋은 사람들과 좋은 결과물을 내서 너무 행복한 프로젝트를 했다.
감사합니다 NCP, 감사합니다 큐시즘 !!!! ❤️
Team Express2.


제 초상권은요??