[JPA] Fetch Join과 Pagination을 사용할 때 주의할 점은 ?

문제 설명
큐시즘 팀피셜 프로젝트를 진행하면서 전체 게시글 + 3개의 기준에 대한 필터링 + 페이징처리를 해야할 요구사항이 생겨 QueryDSL과 Pageable 인터페이스를 이용하여 구현했다.
페이징 방식은 페이지 번호가 있었기에 offset 방식으로 구현해야했고, 그에따라 offset과 limit을 이용해서 구현했다.
이때 발생했던 문제와 해결방식을 공유해보고자 한다.
우리는 전체 게시글에서
1. 모집중인 글
2. 모집 분야
3. 진행방식
에 대한 필터링을 거쳐야 했고, 그에따라 동적 쿼리를 다룰 수 있는 QueryDSL을 이용해
@Override
public Page<RecruitingPost> findByFilters(
RecruitingStatus status,
Position position,
ProgressWay progressWay,
Pageable pageable) {
QRecruitingPost post = QRecruitingPost.recruitingPost;
QRecruitingDetail postDetail = QRecruitingDetail.recruitingDetail;
BooleanBuilder builder = new BooleanBuilder();
if (status != null) builder.and(post.status.eq(status));
if (progressWay != null) builder.and(post.progressWay.eq(progressWay));
if (position != null) builder.and(postDetail.position.eq(position));
List<RecruitingPost> content = queryFactory
.selectFrom(post)
.leftJoin(post.profile).fetchJoin()
.leftJoin(post.recruitingDetails, postDetail).fetchJoin()
.where(builder)
.orderBy(post.createdAt.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
long total = queryFactory
.select(Wildcard.count)
.from(post)
.where(builder)
.fetchOne();
return new PageImpl<>(content, pageable, total);
}이런식으로 구현했다.
RecruitingPost라는 엔티티를 불러올 때, 관련된 Profile과 RecruitingDetail 엔티티는 모두 지연로딩으로 연관관계가 맺어져 있어서
첨부터 fetch join으로 가져와 JPA N+1문제를 해결하려 했다.
하지만, 실제 JPA 쿼리 로그는 Profile에 대한 정보는 쿼리가 딱 한번만 발생했지만 RecruitingDetail 엔티티에 대한 쿼리는 추가적인 N번이 더 나가 N+1문제가 해결되지 못했다.
계속 entity -> DTO를 매핑하는 함수 즉, 서비스 로직
public Page<RecruitingPostDTO.RecruitingPostResponseDTO> getRecruitingPosts(
RecruitingStatus status,
Position position,
ProgressWay progressWay,
Pageable pageable) {
Page<RecruitingPost> posts =
recruitingPostRepository.findByFilters(status, position, progressWay, pageable);
return posts.map(RecruitingPostDTO.RecruitingPostResponseDTO::from);
}의 DTO를 매핑하는 함수 from에서 N+1문제가 발생했다.
그래서 repository에서 반환된 posts객체의 클래스 정보를 찍어보기로 했다.
Page<RecruitingPost> posts =
recruitingPostRepository.findByFilters(status, position, progressWay, pageable);
// 🔍 Repository에서 막 조회된 직후 상태 확인
System.out.println("=== [DEBUG 1] Repository 조회 직후 ===");
posts.getContent().forEach(post -> {
System.out.println("post class: " + post.getClass().getName());
System.out.println("profile class: " + post.getProfile().getClass().getName());
System.out.println("isInitialized(profile): " +
org.hibernate.Hibernate.isInitialized(post.getProfile()));
});
=== [DEBUG 1] Repository 조회 직후 ===
post class:teamficial.teamficial_be.domain.recruitingPost.entity.RecruitingPost profile class: teamficial.teamficial_be.domain.profile.entity.Profile isInitialized(profile): true
로그는 이런식으로 나왔다! 프록시 객체가 아닌 실제 Profile 객체가 들어간게 맞았고, isInitialized도 true이므로 이미 fetch join으로 Profile이 완전히 초기화되어 들어왔고,
Hibernate가 Proxy(Profile$HibernateProxy) 대신 실제 Profile 인스턴스를 넣은 상태입였다.
그래서 그 다음 단계인 DTO변환 과정 함수 from에서의 profile객체를 디버깅 해 보았다.
public static RecruitingPostsResponseDTO from(RecruitingPost post, long dDay) {
System.out.println("=== [DEBUG 2] from(post, dDay) 내부 진입 ===");
System.out.println("RecruitingPost class: " + post.getClass().getName());
// 이 호출이 N+1 쿼리 발생 구간인지 확인
return from(post, post.getRecruitingDetails(), dDay);
}이 곳에서도 여전히 RecruitingPost 객체는 실제 객체로 떴다. 하지만, get.RecruitingDetail을 할때마다 Hibernate가 쿼리를 계속 보내는 것이다. 실객체에서 왜 쿼리를 날리지?
그래서 오류 로그를 처음부터 제대로 확인하며 다음과 같은 오류를 발견했다.
2025-11-02T10:53:45.766 WARN ... HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
이 부분은 페이징(offset, limit)과 컬렉션 fetch join을 같이 사용했기 때문에 Hibernate가 in-memory 페이징을 수행하면서, 각 엔티티의 컬렉션을 "부분 초기화된 상태(partially initialized)"로 처리했고, 이후 접근 시마다 재조회가 발생한 것을 뜻한다.
풀어서 설명하면,
현재 RecruitingPost와 RecruitmentDetail은 OneToMany관계이다.
RecruitingPost를 하나 불러오면 그에 대한 RecruitmentDetail Collection을 전부 가져와야 한다는 소리이다.
하지만, 우리는 페이징 처리를 해서 post객체로 받는다.
이 과정에서 hibernate는
- RecruitingPost와 관련된 모든 RecruitmentDetail을 쿼리로 가져온다 (fetch join)
- Hibernate는 페이지 경계를 자르기 위해 일부 row를 버린다.
그 과정에서 recruitingDetails 컬렉션은 "완전한 데이터"가 아니라 “부분 데이터”로 남는것이다.
정말일까??
그래서 난 디버깅 코드를 넣어서 확인해 보았다.
현재 DB에 저장된 RecruitmentPost데이터는 100개이다.
Page<RecruitingPost> posts =
recruitingPostRepository.findByFilters(status, position, progressWay, pageable);
System.out.println("=== [DEBUG] 페이지네이션 결과 확인 ===");
System.out.println("page number : " + posts.getNumber());
System.out.println("page size : " + posts.getSize());
System.out.println("total elements: " + posts.getTotalElements());
System.out.println("total pages : " + posts.getTotalPages());
System.out.println("content count : " + posts.getContent().size());
System.out.println("==============================");
return posts.map(recruitingPost -> {
long dDay = checkDDay(recruitingPost);
return RecruitingPostDTO.RecruitingPostsResponseDTO.from(recruitingPost, dDay);
});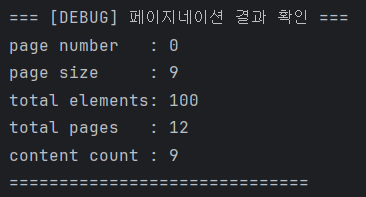
코드를 보면 알겠지만 posts.size()는 9가 나온다, 딱 한 페이지의 개수만큼만 저장되는 것을 볼 수 있다.
그러면 왜 hibernate는 부분데이터로 저장하는 것일까?
우리의 QueryDSL 코드를 다시 보자.
@Override
public Page<RecruitingPost> findByFilters(
RecruitingStatus status,
Position position,
ProgressWay progressWay,
Pageable pageable) {
QRecruitingPost post = QRecruitingPost.recruitingPost;
QRecruitingDetail postDetail = QRecruitingDetail.recruitingDetail;
BooleanBuilder builder = new BooleanBuilder();
if (status != null) builder.and(post.status.eq(status));
if (progressWay != null) builder.and(post.progressWay.eq(progressWay));
if (position != null) builder.and(postDetail.position.eq(position));
List<RecruitingPost> content = queryFactory
.selectFrom(post)
.leftJoin(post.profile).fetchJoin()
.leftJoin(post.recruitingDetails, postDetail).fetchJoin()
.where(builder)
.orderBy(post.createdAt.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
long total = queryFactory
.select(Wildcard.count)
.from(post)
.where(builder)
.fetchOne();
return new PageImpl<>(content, pageable, total);
}이부분에서 우리는 요청값에 해당하는 개수만을 가져오기위해
limit절을 사용해 개수만큼을 자르기로 했다.
따라서 우리는 이런 느낌의 조인 쿼리를 예상할 것이다.
SELECT *
FROM RecruitingPost
INNER JOIN RecruitingDetail ON RecruitingPost.id = RecruitingDetail.RecruitingPost.id
WHERE RecruitingPost.id = ?
LIMIT 5
하지만 실제 Warning과 들어간 쿼리를 보면?
2025-11-02T10:53:45.766 WARN ... HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
Hibernate:
select
rp1_0.recruiting_post_id,
rp1_0.contact_way,
rp1_0.content,
rp1_0.created_at,
rp1_0.deadline,
rp1_0.deleted_at,
rp1_0.period,
rp1_0.profile_id,
p1_0.profile_id,
p1_0.contact_way,
p1_0.created_at,
p1_0.deleted_at,
p1_0.position,
p1_0.profile_image,
p1_0.profile_name,
p1_0.updated_at,
p1_0.user_id,
p1_0.user_name,
p1_0.working_time,
rp1_0.progress_way,
rd1_0.recruiting_post_id,
rd1_0.recruiting_detail_id,
rd1_0.count,
rd1_0.created_at,
rd1_0.deleted_at,
rd1_0.position,
rd1_0.updated_at,
rp1_0.start_date,
rp1_0.status,
rp1_0.title,
rp1_0.updated_at,
rp1_0.user_id
from
recruiting_post rp1_0
left join
profile p1_0
on p1_0.profile_id=rp1_0.profile_id
left join
recruiting_detail rd1_0
on rp1_0.recruiting_post_id=rd1_0.recruiting_post_id
order by
rp1_0.created_at desc그 어디에도 limit과 관련된 쿼리는 나오지 않는데,
오류 내용을 해석해보면, 쿼리 결과를 전부 메모리에 적재한 뒤 Pagination 작업을 어플리케이션 레벨에서 하기 때문에 위험하다는 로그이다.
우리는 limit을 명시하여서 제한된 쿼리결과(=이미 Pagination된 결과)를 가져올 것을 예상했지만 실제로는 그렇지 않다는 것이다..
그 이유는 fetch Join을 하게된다면, limit을 내부 함수의 파라미터로 전달해도, default로 null을 저장하고 있기 때문에, limit을 반영하지 않는것이다.
따라서, fetch Join을 했을때 데이터 100개는 load되지만, 어플리케이션 레벨에서 hibernate가 9개(페이지 수 만큼)만 잘라서 저장하는것이다.
실제 hibernate 공식문서.
Fetch should be used together with setMaxResults() or setFirstResult(), as these operations are based on the result rows which usually contain duplicates for eager collection fetching, hence, the number of rows is not what you would expect.
hibernate는 이를 불완전한 컬렉션으로 인식하고 모든 객체에 대한 연관관계에 대해 쿼리를 날리므로 N+1문제가 해결되지 않는것이다.
그렇다면 우리는 어떻게 해야할까?
해결
1. Entity -> Dto 변환 로직자체를 하지 않는다 (DTO Projection)
대부분 N+1문제는 entity에서 다른 연관관계의 entity의 정보를 가져올 때 발생하고, 이는 entity에서 DTO에 필요한 정보를 뽑아낼 때 가장 많이일어난다 따라서,
List<RecruitingPostDTO.RecruitingPostsResponseDTO> content = queryFactory
.select(new QRecruitingPostDTO_RecruitingPostsResponseDTO(
post.id,
post.profile.userName,
post.profile.profileImage,
post.progressWay,
post.contactWay,
post.startDate,
post.period,
post.deadline,
post.status,
post.content,
post.title,
post.createdAt
))
.from(post)
.distinct()
.leftJoin(post.recruitingDetails, postDetail)
.where(builder)
.orderBy(post.createdAt.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();실제 필요한 정보만 Entity를 거치지 않고 바로 메소드자체에서 DTO를 반환하여 N+1문제를 해결한다
이렇게 변환하고 나서 쿼리를보면
Hibernate:
select
distinct rp1_0.recruiting_post_id,
p1_0.user_name,
p1_0.profile_image,
rp1_0.progress_way,
rp1_0.contact_way,
rp1_0.start_date,
rp1_0.period,
rp1_0.deadline,
rp1_0.status,
rp1_0.content,
rp1_0.title,
rp1_0.created_at
from
recruiting_post rp1_0
left join
recruiting_detail rd1_0
on rp1_0.recruiting_post_id=rd1_0.recruiting_post_id
join
profile p1_0
on p1_0.profile_id=rp1_0.profile_id
order by
rp1_0.created_at desc
limit
?, ?
Hibernate:
select
count(*)
from
recruiting_post rp1_0딱 두개의 쿼리만 나간다. (QueryDSL 관련 쿼리) 이는 N+1여개의 쿼리가 나가는 것에 비해 상당한 성능 향상을 이루었다고 말할 수 있다!
2. @BatchSize를 사용한다.
이는 지연로딩시 한번에 가져올 연관관계 객체의 크기를 결정하는 어노테이션인데,
예를들어 현재 데이터가 100개일때,
@Entity
public class RecruitingPost {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@OneToMany(mappedBy = "recruitingPost", fetch = FetchType.LAZY)
@BatchSize(size = 50) // 👈
private List<RecruitingDetail> recruitingDetails = new ArrayList<>();
}
@BatchSize(size = 50) 어노테이션을 붙여 한 번에 최대 50개의 부모(Post)에 대한 자식(Detail)을 IN 쿼리로 묶어서 가져올 수 있다.
즉, 즉, 쿼리 횟수가 1 + ⌈N / batchSize⌉ 정도로 줄어드는 것이다..
이는 N+1을 완전히 해결한다고 볼 수는 없지만, 아주 쉽게 성능을 향상 시킬 수 있는 방법이다.
내가 1번 방법을 선택했던 이유는 ,
리스트는 다수 사용자가 빈번하게 조회하지만, 수정 빈도는 낮은편이고, 조회 성능이 가장 중요한 구간이었다. 따라서 BatchSize 기반 Lazy 로딩보다 불필요한 엔티티 초기화를 완전히 배제할 수 있는 DTO Projection 방식이 필요하다고 생각했다. Projection을 통해 필요한 컬럼만 select하여 네트워크 I/O와 메모리 사용량을 최소화하는 효과를 기대했다.
이후에는 offset paging 방식 관련해서 DB 최적화 하는 글을 써보겠습니다.
참고한 글
https://tecoble.techcourse.co.kr/post/2020-10-21-jpa-fetch-join-paging/
