offset, limit 페이징 쿼리 최적화 (첫 페이지 72s -> 마지막 페이지 응답시간 1s)

팀피셜 프로젝트를 개발하며, offset limit 방식의 페이징 기능이 필요했다. offset limit paging은 데이터를 전부 읽은 후 offset만큼 잘라서 제공하기 때문에 데이터가 많아질 수록 상당한 속도 저하를 유발한다.
그래서 그때 썼던 코드를 리팩토링 해보기로 했다!
recruiting_post에 데이터는 300만건정도 넣고 시작했다.
사실은 앞에 repository랑 service로직을 분리해서 리팩토링하기 좋게 만든 부분이 있는데 그건 다른 글로 써볼거것이다 !!
✔️처음 쿼리문
SELECT DISTINCT
rp.recruiting_post_id,
rp.profile_id,
p.user_name,
p.profile_image,
rp.progress_way,
rp.contact_way,
rp.start_date,
rp.period,
rp.deadline,
rp.status,
rp.content,
rp.title,
rp.created_at
FROM recruiting_post rp
LEFT JOIN recruiting_detail rd
ON rp.recruiting_post_id = rd.recruiting_post_id
INNER JOIN profile p
ON p.profile_id = rp.profile_id
ORDER BY rp.created_at DESC
LIMIT 0, 9;MySQL에서 첫페이지를 조회하는 쿼리를 돌렸는데 안돌아갔다.
너무 무식한 쿼리라 workbench가 거부하는거란다.......ㅠㅠㅠ

실제 테스트 코드 (첫 페이지 조회)

거의 72초가 나왔다. 첫 페이지 조회에 72초면 진짜 말도 안되는 속도다 잘못 짠게 틀림없다.
본격적으로 시작해보자!!
1. 불필요한 Join 제거
rerruiting detail과 join하고 난 데이터가 전혀 select 되지않으므로
recruiting detail left join를 제거했다.

2. paging에서 distinct 제거

distinct 제거하니까 확 줄어들었다 왜그럴까??
나의 이전 코드는
.leftJoin(post.recruitingDetails, postDetail)
.distinct()
이 구조를 살펴보면, 현재 RecruitingPost 300만건, RecrutingPostDetail이 900만건 (글 하나당 직무 정보 3개라 가정)
저 위의 코드는 300만 x 900만을 모두 조합한 다음, 중복을 제거하는 아주 무서운 코드였던것
따라서, limit 코드가 의미가 없어지게됨.
그래서 첫 페이지 조회에 70초라는 엄청난 시간이 들었던 것이다.
이어서 본격적으로 쿼리 튜닝을 해보자
List<RecruitingPostPagingDto.RecruitingPostFlatDto> flatPosts = queryFactory
.select(Projections.constructor(
RecruitingPostPagingDto.RecruitingPostFlatDto.class,
post.id,
post.profile.isDeleted,
post.profile.user.id,
post.profile.id,
post.profile.userName,
post.profile.profileImage,
post.progressWay,
post.contactWay,
post.startDate,
post.period,
post.deadline,
post.status,
post.content,
post.title,
post.createdAt
))
.from(post)
.where(builder)
.orderBy(post.createdAt.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();현재 쿼리를 보면,
post 테이블에서 profile 테이블과 조인을 한 모든 결과를 정렬하고 자른다.
300만 x profile(10만개라 가정)한다면 그 개수의 데이터들을 모두 정렬한 후, 9개만 잘라 리턴하는 소스코드인 것이다.
그렇다면 우리는 순서를 바꿔서 딱 size만큼만 post로 부터 가져와서 Join 후, 정렬하면 되지않을까 ?
먼저 조건에 해당하는 recruitingPost를 size 만큼 가져온 후, profile.post.id와 조인하면 되는것.
그리고 MySQL InnoDB는 자체적으로 FK 인덱스를 생성하지 않기 때문에, profile 테이블에서FK인덱스를 만들면 대용량 데이터에도 문제가 없다고 생각했다.
List<Long> pagedPostIds;
if (position == null) {
pagedPostIds = queryFactory
.select(post.id)
.from(post)
.where(builder)
.orderBy(post.createdAt.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
} else {
pagedPostIds = queryFactory
.select(post.id)
.from(post)
.join(post.recruitingDetails, postDetail)
.where(
builder.and(postDetail.position.eq(position))
)
.orderBy(post.createdAt.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
}
if (pagedPostIds.isEmpty()) {
return new PageImpl<>(Collections.emptyList(), pageable, 0);
}
List<RecruitingPostPagingDto.RecruitingPostFlatDto> flatPosts =
queryFactory
.select(Projections.constructor(
RecruitingPostPagingDto.RecruitingPostFlatDto.class,
post.id,
post.profile.isDeleted,
post.profile.user.id,
post.profile.id,
post.profile.userName,
post.profile.profileImage,
post.progressWay,
post.contactWay,
post.startDate,
post.period,
post.deadline,
post.status,
post.content,
post.title,
post.createdAt
))
.from(post)
.join(post.profile, profile)
.join(profile.user, user)
.where(post.id.in(pagedPostIds))
.orderBy(post.createdAt.desc())
.fetch();
Long total;
if (position == null) {
total = queryFactory
.select(post.id.count())
.from(post)
.where(builder)
.fetchOne();
} else {
total = queryFactory
.select(post.id.countDistinct())
.from(post)
.join(post.recruitingDetails, postDetail)
.where(builder.and(postDetail.position.eq(position)))
.fetchOne();
}
return new PageImpl<>(flatPosts, pageable, total == null ? 0 : total);그렇게 해서 만든 쿼리는 이렇다.
position으로 분기처리 한 부분이 보일텐데,
position은 무조건 recruiting_post_detail과 Join을 해야했기 때문에, position 필터링 조건이 들어왔을때는 join을 하는 로직으로 추가했다.
그리고,
.leftjoin(post.profile, profile)
.leftjoin(profile.user, user)었던 부분을, 아래 처럼 Inner Join으로 교체했다.
왜냐하면, 우리 비즈니스 로직상, RecruitingPost는 무조건 Profile이 있어야했고, profile도 User가 무조건 있어야 했기에 LeftJoin으로 null일 경우를 고려할 필요는 없었기 때문이다.
실제로 LeftJoin의 row수가 InnerJoin보다 훨씬 많이 만들어지기 때문에, 타당했다고 생각한다.
.join(post.profile, profile)
.join(profile.user, user)그리고, profile자체에 user_id필드를 하나 만들어서 Join을 두번 하지않고, 하는 방법도 있다. (shadow FK 라는걸 둬서 조인하지않고 바로 참조 함) 검색해보니 주로 영어로 된 포스팅이 있었다.
나는 정규화를 포기하고 싶지 않았고, 우리는 거의 모든 비즈니스 로직에 profile entity가 사용되었기 때문에 코드 수정 공수가 너무 많이 들어서 포기했다.
이렇게 쿼리를 개선하고 테스트 코드를 돌려보면?

물론 쿼리는 3번이나 필요하지만, 첫 페이지에서 3초라는 시간이 걸린다.
아직 끝나지 않았다.
조인 컬럼과, 로직에따라 인덱스를 추가해 줄 것이다.
현재 쿼리들의 실행계획을 보면 다음과 같다.
아무 조건이 없는 전체 조회 쿼리를 가정하고 진행한다.
인덱스 추가
1. 필터링 조건이 없을 때 RecruitingPost의 Id값 추출
EXPLAIN
SELECT rp.recruiting_post_id
FROM recruiting_post rp
ORDER BY rp.created_at DESC
LIMIT 0, 20;
이건 100% 테이블 풀 스캔이 일어남을 알 수 있다.
MySQL 데이터들 내부적으로 정렬이 되어있지 않으므로, 270만건의 데이터를 모두 정렬한 후, 20개씩 자른다.
따라서, created_at으로 미리 정렬된 인덱스가 필요함을 알 수 있다.
그리고 필터링 조건에 해당하는 status, progress_way필드도 함께 추가하여
CREATE INDEX idx_post_created_at
ON recruiting_post(created_at DESC);
해당 인덱스를 추가했다.
이렇게 된다면 MySQL은 OrderBy 정렬작업을 하지않고 정렬된 인덱스를 그대로 읽기만 하면 되므로 상당한 성능 상 이점이 있을 것이다.

위의 결과처럼 딱 20건만 조회하는 것을 볼 수 있다.
🚨주의)
처음에 인덱스를 만들때는, 모든 정렬 조건이 포함된
CREATE INDEX idx_post_status_progress_created ON recruiting_post(status, progress_way, created_at DESC);
다음과 같은 인덱스를 만들었다. 하지만 결론적으로 해당 인덱스는 정말 쓸모없는 인덱스이다.
MySQL은 인덱스를 해석할때 left-most전략을 취한다. status -> progress_way -> created_at 순으로 정렬 순서를 취한다.
하지만 status나 progress 둘중 하나라도 null이 들어온다면 MySQL은 인덱스를 전혀 사용하지않기 때문이다.
그래서 전체 조회같은 필수적인 것만 인덱스를 만들어 놓고, 부하테스트를 통해 많이 사용되는 필터에 인덱스를 만드는 식으로 하는게 BEST이다 !!
2. 추출된 postId로 profile, user관련 데이터 매핑
EXPLAIN
SELECT
rp.recruiting_post_id,
p.is_deleted,
u.user_id,
p.profile_id,
p.user_name,
p.profile_image,
rp.progress_way,
rp.contact_way,
rp.start_date,
rp.period,
rp.deadline,
rp.status,
rp.content,
rp.title,
rp.created_at
FROM recruiting_post rp
JOIN profile p ON p.profile_id = rp.profile_id
JOIN user u ON u.user_id = p.user_id
WHERE rp.recruiting_post_id IN (
101,102,103,104,105,106,107,108,109,110,
111,112,113,114,115,116,117,118,119,120
)
ORDER BY rp.created_at DESC;
해당 쿼리는 1번에서 추출된 recruitingPostId를 서브쿼리를 where조건에 넣고, 거기서 나온 postId에 해당하는 row와 profile, user와 이중 join을 하는 쿼리이다. 실행 계획은 다음과 같다.

id가 같으면 동시다발적으로 실행된거라 보면되고,
첫째줄부터 보면, type이 range이다, 이는 실제 인덱스가 사용된것이다. 정확하게는 Index Range Scan이 사용된것이다. MySQL에서는 PK에 대한 기본적인 인덱스 (클러스터링 인덱스)가 만들어져 있으므로 그 인덱스를 사용했다.
두번째는 ALL Type이므로 테이블 풀스캔이 일어났다. Join후 테이블 풀 스캔이 일어난 것이다. 현재 Profile의 row개수는 많이 저장되어있지 않으므로 성능상 문제는 없지만, profile이 굉장히 많아진다면 상당한 시간이 소요될것이다.
세번째는 역시 PK이므로 Index를 사용해서 쿼리가 실행되었다는 것을 알 수 있다.
여기서는, 두번째의 실행계획만 테이블 풀스캔이 일어나므로 profile이랑 조인을 할때 필요한 FK인덱스를 만들어주는게 좋다고 생각했다.
따라서,
CREATE INDEX idx_post_profile_id
ON recruiting_post(profile_id);
로 인덱스를 만들어주었다.

결과는 다음과 같다,
비록 2번째줄에서 테이블 풀 스캔이 일어나지만, 첫번째 줄에 우리의 인덱스가 possible_keys에 들어간 것을 볼 수 있다.
하지만 사용하지 않은 이유는, profile 데이터가 굉장히 적어서 (10건 이하) MySQL 옵티마이저가 풀스캔이 더 효과적이라고 생각한 것이다.
3. Count 쿼리
EXPLAIN
SELECT COUNT(rp.recruiting_post_id)
FROM recruiting_post rp;MySQL은 각 테이블에 대한 메타데이터를 가지고 있으므로, 매번 계산하지는 않는다. type = index 는 참고로 인덱스 풀스캔이다.

4. recruiting_detail 매핑 조회
EXPLAIN
SELECT
rd.recruiting_post_id,
rd.position,
rd.count
FROM recruiting_detail rd
WHERE rd.recruiting_post_id IN (
101,102,103,104,105,106,107,108,109,110,
111,112,113,114,115,116,117,118,119,120
);
현재 table full scan이 일어난 것을 볼 수 있는데, 현재는 recruiting_detail의 수가 적기때문에 성능상 문제가 없다,
하지만 우리 프로젝트의 요구사항은 post하나당 detail이 2~3개정도 들어가하므로, post가 300만개면 detail은 900만개 정도가 들어가야하는것이다. 이를 full scan한다는 것은 정말 오버헤드가 크다.
따라서 recruiting_detail에 recruiting_post_id (FK)에 해당하는 인덱스를 만들어 Join 성능을 최적화하면 된다.
CREATE INDEX idx_detail_post_id
ON recruiting_detail(recruiting_post_id);위와 같은 인덱스를 만들어준다.

index range scan이 발생한 것을 확인할 수 있다.
인덱스 추가가 모두 끝났다, 다시 테스트 코드를 돌려보면
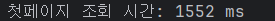
첫페이지 조회가 1.5초로 줄었다.
처음 쿼리 72초 -> 1.5초로 개선할 수 있었다.
그럼 마지막 페이지는 얼마나 걸릴까?
사실 첫 쿼리는 첫 페이지에 72초가 걸려서 굳이 안돌려봤었다.
하지만 지금은 ?

마지막 페이지도 무려 1.4초만에 조회가 가능하다.
어떻게 이게 가능했을까?
보통 전통적인 limit, offset 페이징은 limit 만큼 데이터를 전부 읽은 후 offset만큼 잘라서 제공하기 때문에, 300만건의 마지막 페이지에서는 (2999990, 10)이면 299만건의 데이터를 다 읽은 후 10건을 읽어야 하고 이는 상당한 속도 저하를 유발한다.
하지만 나의 코드는 처음에 RecruitingPostId를 size 만큼 읽어온다, 이는 cursor paging이랑 비슷한 효과를 발생시킨다.
모두 읽을 필요 없이 해당 Id에 해당하는 데이터만 Join하고 출력하면 되기 때문에 상당한 성능 이점이 있는것이다.
마무리
한 요청에 쿼리가 4번정도 간다는 것은 무리가 있을 수 있지만, 쿼리를 쪼개 random I/O를 줄였고 , 응답시간을 상당히 단축시켰다는것에 의미가 있다고 생각한다 !!
다음에는 쿼리횟수를 줄일 수 있는 방법을 생각해봐야겠다.
