1. 매번 Thread를 생성하는 방식의 문제점
요청마다 Thread를 생성하고 사용한 뒤 삭제하는 방식으로 구현해본 적 있는가?
이 방식은 생각보다 치명적인 문제들을 가지고 있다.
-
성능 문제
Thread 생성은 꽤 무거운 작업이다. OS 레벨에서 스택 메모리를 할당하고,
컨텍스트를 설정하는 등의 오버헤드가 발생한다. -
자원 고갈
수천 개의 동시 요청이 들어오면
그만큼의 Thread가 생성되고, 메모리는 빠르게 고갈되어
시스템이 응답 불능 상태에 빠진다.
Thread Pool로 해결이 가능하다.
2. Thread Pool
Thread Pool은 이런 문제를 깔끔하게 해결한다.
핵심 아이디어는 간단하다:
- Thread를 미리 만들어서 대기시켜 놓는다.
- 요청이 들어오면 놀고 있는 Thread에게 일을 맡긴다.
- 작업이 끝나도 Thread를 재활용한다.
장점
1. 성능 향상: Thread 생성 오버헤드 제거
2. 자원 제어: Pool 크기로 동시 실행 Thread 수 제한
3. 안정성: 트래픽 폭증해도 Thread 개수는 제한됨
레스토랑으로 치면, 손님 올 때마다 요리사 고용하는게 아니라
요리사 N명을 고정으로 두고 주문을 배분하는 방식이라고 보면 된다.
설계
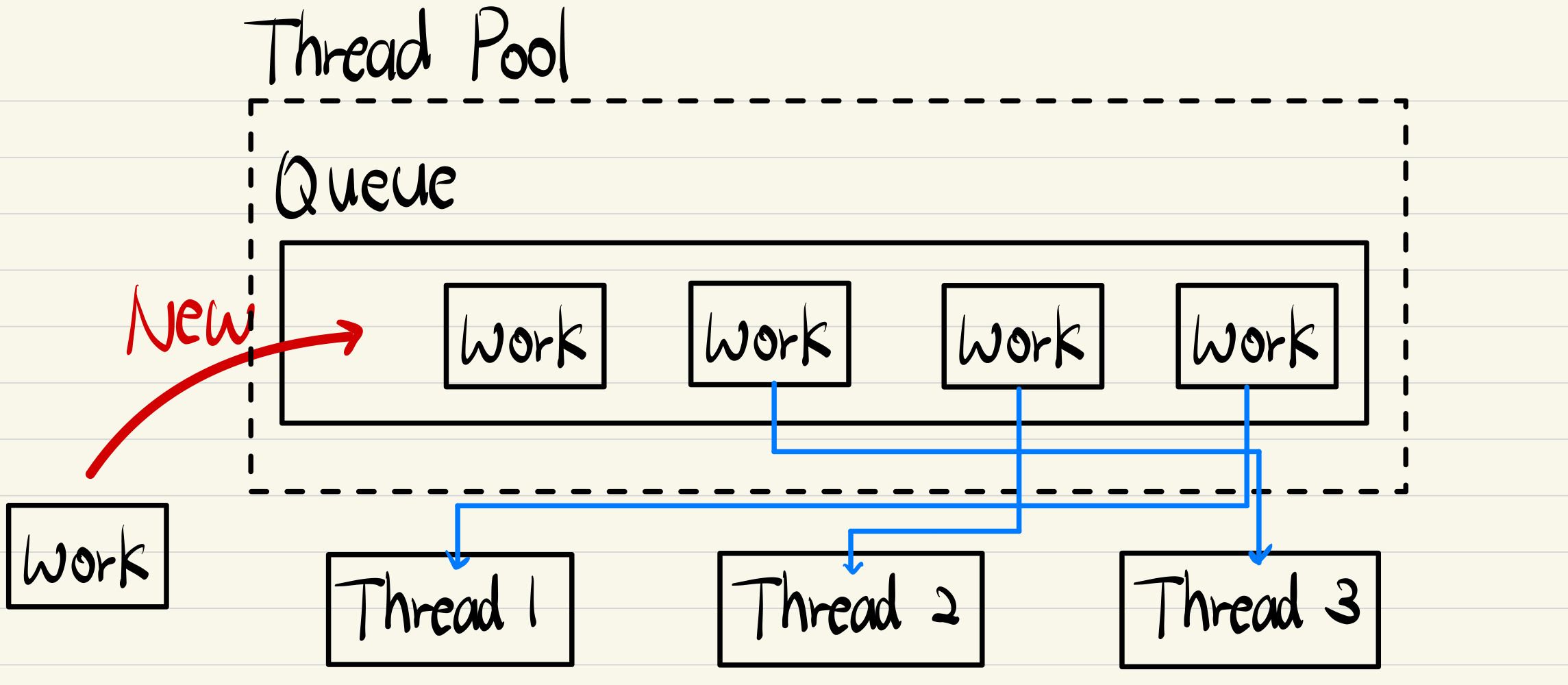
Thread Pool은 크게 3가지 컴포넌트로 구성된다:
1. Worker Threads
- 미리 생성해둔 N개의 Thread
- 계속 살아있으면서 작업을 기다림
2. Task Queue
- 처리할 작업들이 대기하는 큐
- Thread-safe해야 함 (여러 Thread가 접근)
3. 작업 분배 로직
- 놀고 있는 Thread가 Queue에서 작업을 가져감
- 작업 완료 후 다시 Queue 확인 (루프)
3. 코드 예시
Thread Pool 사용
// Thread Pool 생성
size_t num_threads = std::thread::hardware_concurrency(); // CPU 코어 수
ThreadPool pool(num_threads);
// 작업을 queue에 insert
for (int i = 0; i < 1000; i++) {
pool.enqueue([i]() {
processRequest(requests[i]);
});
}
// Pool은 내부적으로 N개 Thread만 유지하며 1000개 작업 처리Thread Pool 기본 구조
class ThreadPool {
public:
ThreadPool(size_t threads);
~ThreadPool();
// 작업 큐에 추가
template<class F>
void enqueue(F&& f);
private:
std::vector<std::thread> workers; // Worker threads
std::queue<std::function<void()>> tasks; // Task queue
std::mutex queue_mutex; // Queue 보호
std::condition_variable condition; // Thread 대기/깨우기
bool stop;
};
시스템 개발 공부 중