
1.Abstract

✔ a fixed small set of learned object queries 주어지면 object와 context의 관계를 추론하고 병렬적으로 final set of predictions를 output으로 출력한다.
2.Introduction
✔ "To simplify theses pipelines, we propose a direct set prediction approach to bypass the surrogate tasks."
→ object detection의 목표는 bbox와 label을 예측하는 것
→ modern detectors의 성능은 후처리 과정(NMS), anchor set 디자인, 휴리스틱하게 target box를 anchor에 할당하는데 크게 의존
→ DETR은 이러한 과정을 간소화하고 heuristic한 방법의 제거를 제안
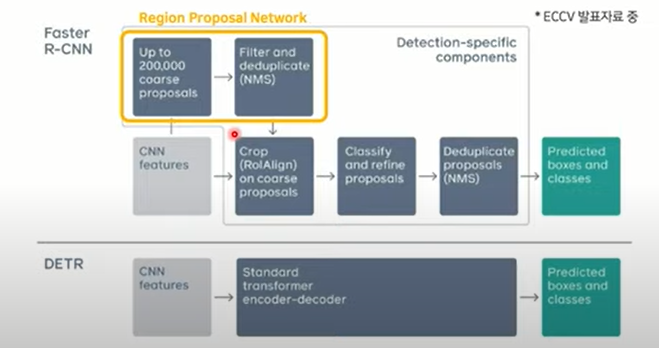
📌 NMS:중복된 박스들 중 Confidence threshold 이하의 bounding box를 제거해 하나의 box만 남김

✔ "This paper aims to bridge this gap."
→ end-to-end philosophy는 아직 object detection에 사용되고 있지 않음, 이는 이전의 연구들이 prior knowledge를 추가하지 않으려는 경향 때문
→ 따라서 object detection 분야에도 end-to-end 방식을 도입
✔ "We adopt an encoder-decoder architecture based on transformers,"
→ 중복된 predictions 제거하는데 적합
✔ "predicts all objects at once"
→ 학습시 predicted objects와 ground truth objects 간의 bipartite matching을 수행하는 a set loss fuction를 사용
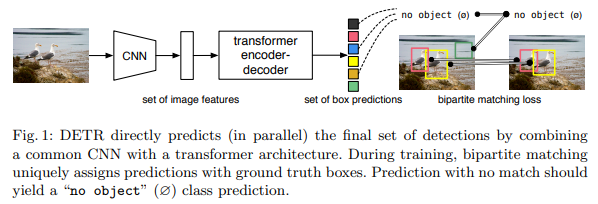
📌 bipartite matching(이분매칭): direct set prediction problem, 원래 의미는 A집단이 B집단을 선택할때 효과적으로 매칭시켜준다는 점에서 ‘최대 매칭(Max Matching)’ 을 의미, detr에서는 ground truth의 어떤 object를 검출하고 있는지 1대1로 매칭하는 과정 필요, 이분매칭이 필요한 이유는 병렬적으로 bbox가 출력되므로 N개의 bbox가 어떤 ground-truth를 검출하고 있는지 알 수 없음(permutation invariant)
→이분매칭의 또 다른 설명은 hungarian loss를 걸어주기 전에 output과 gt를 서로 matching해서 pair 집합을 만들어 주는 과정 필요
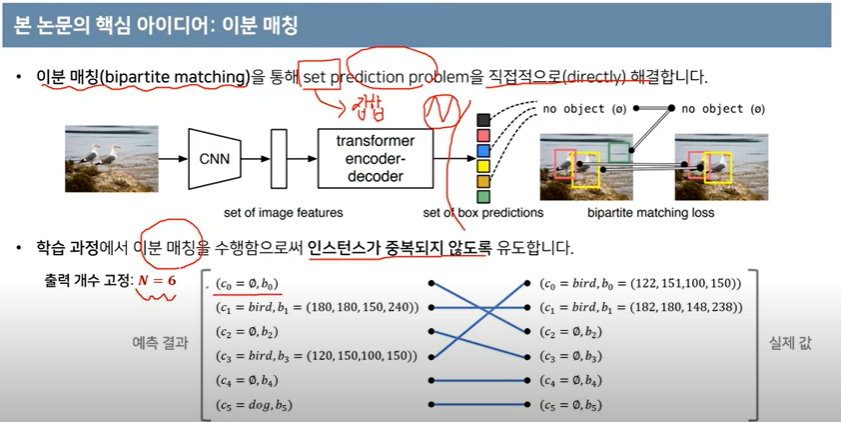
✔ "the main features of DETR are the conjunction of the bipartite matching loss and transformers with (non-autoregressive) parallel decoding"
→ 이전 모델과 비교했을 때 DETR의 주요 특징은 bipartite matching loss와 transformer with parallel decoding의 결합
→ DETR이 non-autoregressive하다는 건 loss function이 prediction을 ground truth에 unique하게 할당하여 예측한 object의 순열이 변하지 않아 병렬적으로 내보낼 수 있기 때문이다.?
✔ "We evaluate DETR on one of the most popular object detection datasets, COCO, against a very competitive Faster R-CNN baseline."
→ large object에 대한 성능이 좋음
→ small object에 대한 성능은 그리 좋지 않았음
✔ "Training settings for DETR differ from standard object detectors in multiple ways."
→ 긴 학습 스케줄이 필요
→ transformer에서 auxiliary decoding loss도 필요
2. Related work
2.1 Set Prediction(예측값들을 병렬적으로 한번에 출력)
2.2 Transformers and Parallel Decoding
2.3 Object detection
Set-based loss
Recurrent detectors
3. The DETR Model
"Two ingredients are essential for direct set predictions in detection"
3.1 Object detection set prediction loss
"DETR infers a fixed-size set of N predictions, in a single pass through the decoder, where N is set to be significantly larger than the typical number of objects in an image."
💨 DETR은 a fixed-size set of N predictions를 추론, N은 이미지의 object 보다 더 큰 숫자로 설정
💨 bipartite matching loss
✔ prediction과 ground truth 간의 match loss를 최소화하는 σ를 찾는 것
✔ y: ground truth, a set of size N padded with ∅ (no object)
→ np object는 ∅로 패딩
✔ y_hat:set of N prediction
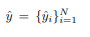
✔ σ:permutation of N elements(예측한 N개 prediction 요소들의 순서)
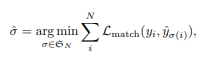
✔ a pair-wise matching cost → 1:1 matching cost, class prediction, bbox, Hungarian algorithm

hungarian algorithm
✔ yi = (c_i, b_i) → c_i는 class label이고 순열 , bi ∈ [0, 1]4 is a vector(ground truth box center coordinates, height, width) & 0~1 normalization
✔ match cost:ˆpσ(i)(c_i)는 class probability이고 순열 σ의 i 번째 요소가 해당하는 GT의 클래스를 예측한 확률, ˆbσ(i)는 predicted bbox, 예측한 class가 no object가 아닐 때 그러니까 실제로 사물이 있을 때 적용
→class probability에 음수를 곱하는 이유: 확률이 높을수록 loss가 낮아야 하기때문
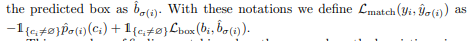
✔ 위의 두 식으로 best match를 찾아 1:1 매칭하므로 중복된 box가 출력되지 않아 NMS, region proposal, threshold 설정 같은 heuristic 방법 필요 없음
✔ Hungarian loss: cost가 가장 적은 ^σ을 찾았은 후 계산
"a linear combination of a negative log-likelihood for class prediction and a box loss defined later"
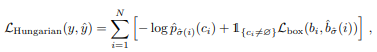
✔"In practice, we down-weight the log-probability term when ci = ∅ by a factor 10 to account for class imbalance."
→no object일 때 loss를 1/10로 줄여주는 이유는 class imbalance 때문
→N=100이라 했을 때 100개의 예측 박스 중 평균 7개 class가 있다면 나머지 93개는 class가 no object라서 class imbalance 발생
✔Bounding box loss

각 lambda들은 두 loss의 비중을 조절하는 scaler 역할, 즉, L1 loss는 단순히 좌표의 차이 만을 가지고 계산하기 때문에 IOU가 비슷해도 크기가 큰 박스가 작은 박스에 비해 loss 값이 크게 나옴 그래서 GIOU 함께 사용
✔ L1 loss

✔ GIOU
Reference
3.2 DETR architecture
💨 CNN + Transfer encoder-decoder + FFN
💨 "positional encodings passed at every attention layer"
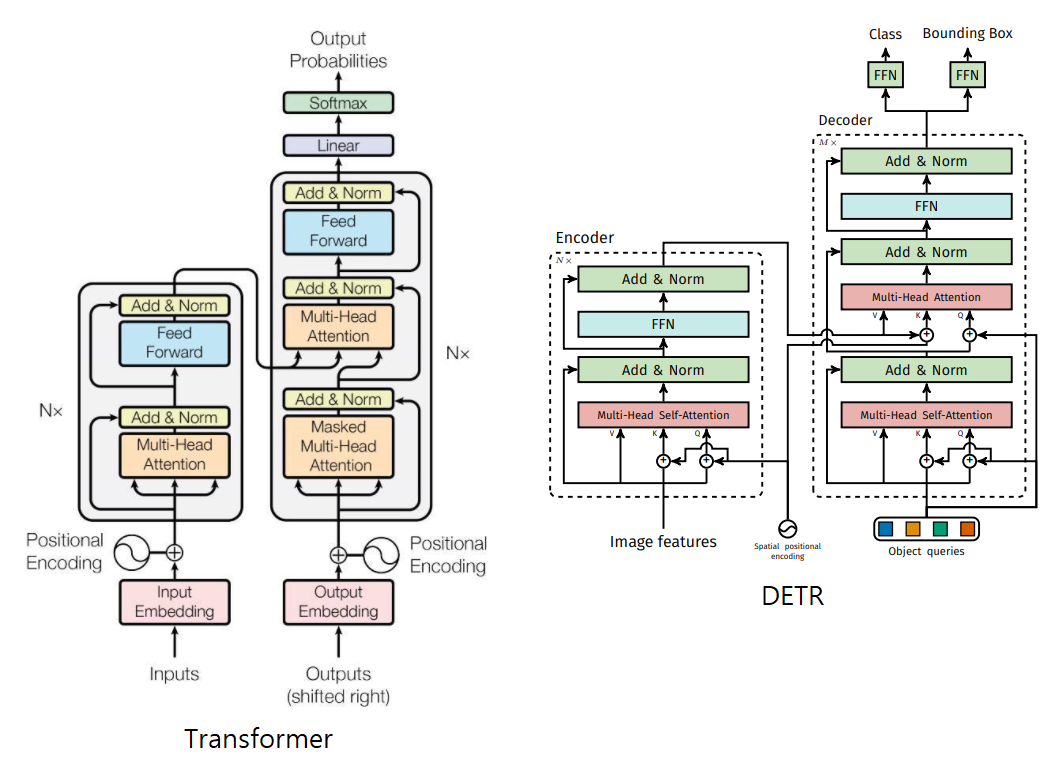
Backbone
✔input image 크기 3 x H_0 x W_0
✔CNN을 통과한 feature map 크기 c=2048, H=H_0/32, W=W_0/32
transformer encoder
✔1x1 convolution 적용 dxHxW로 변환(C>>d)
✔encoder의 input은 2차원을 받으므로 dxHxW의 3차원에서 dxHW의 2차원으로 바꿈(HxW 길이를 가진 sequence로 변환)
✔dxHW sequence를 multi-head self attention에 통과
✔transformer encoder는 permutation-invariant(치환불변) 즉, 순서에 대한 정보 없이 input이 들어가기 때문에 fixed positional encoding을 추가한다.
✔encoder의 최종 출력은 N개
transformer decoder
✔"the decoder receives queries (initially set to zero), output positional encoding (object queries), and encoder memory"
✔Input으로 object queries N개가 병렬적으로 한번에 들어감, object queries 값은 처음에 랜덤한 값을 넣어주고 그 뒤 encoder의 key, value 값을 보고 학습하면서 값이 바뀐다.
✔object queries은 positional encodings가 학습된 embeddings이기도 함
✔N개의 값들이 병렬적으로 한방에 출력됨(prediction set)=>N개의 값 계속 누적
✔self-attentiona과 encoder-decoder attention이 이미지 전체를 추론(global)할 수 있게 해준다.
Prediction feed-forward networks(FFNs)
✔FFN을 거치면 박스좌표와 클래스가 출력됨, 이때 bi-partite matching을 통해 각 bounding box가 겹치지 않도록 한다.
✔3-layer perceptron with ReLU activation function
Auxiliary decoding losses
✔decoder 뒤에 auxiliary loss(prediction FFN, Hungarian loss)를 추가해 duplicate bounding box가 쳐지지 않도록 돕는다.
✔FFN 간에 weights 공유
✔각 class에 해당하는 object의 정확한 갯수 출력하는데 도움이 되었다.
📌 auxiliary loss
"GoogLeNet paper, reduce the vanishing gradient problem for earlier layers, stabilizes the training and is used as regularization. It's only used for training and not for inference"
📌 Transformer vs DETR
1. Positional Encoding 위치 다름
2. Autoregression vs Parallel output 출력

4.Experiments
Dataset
✔COCO 2017, panoptic segmentation datasets
✔"There are 7 instances per image on average, up to 63 instances in a single image in training set"
Technical details.
✔Optimizer : AdamW
✔Backbone : ResNet50(pre-train ImageNet), ResNet101(pre-train ImageNet)
✔dilated convolution added backbone:DETR-DC5 and DETR-DC5-R101
→ small object에 대하여 성능 좋게하기 위해 해상도 높임
✔scale augmentation, random crop augmentations
✔16 V100 GPU
✔DETR 300epochs Faster R-CNN 500epochs
✔3days
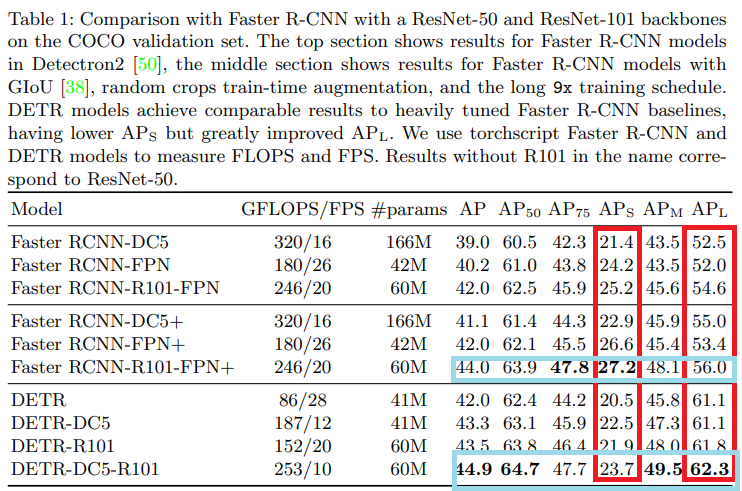
✔ +는 학습시간 길게한 것(9x training schedule)
✔ large object 성능 굿, small object 성능 떨어짐
=>논문에서 small object 성능이 낮은 이유는 밝히고 있지 않지만 faster R-CNN에 FPN이 도입되었듯이 추가 연구로 성능이 더 좋아질 것이라 언급
4.1 Comparison with Faster R-CNN
"we attempt to make a Faster R-CNN baseline stronger. To align it
with DETR, we add generalized IoU to the box loss, the same random
crop augmentation and long training known to improve results"
"we can conclude that DETR can be competitive with Faster R-CNN
with the same number of parameters,"
4.2 Ablations
💨 "we explore how other components of our architecture and loss influence the final performance."
✔ResNet-50-based DETR model with 6 encoder, 6 decoder layers and width 256.
✔41.3M parameters
✔40.6 and 42.0 AP on short and long schedules respectively
✔runs at 28 FPS
Number of encoder layers.
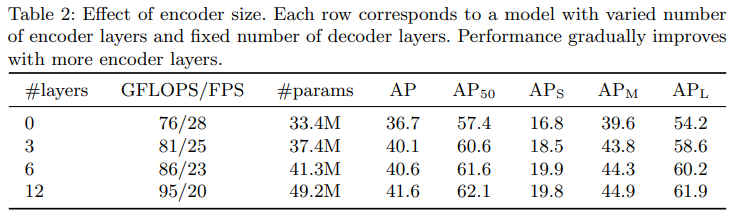
✔"We evaluate the importance of global image level self-attention by changing the number of encoder layers"
→ encoder layers 증가할수록 AP 증가
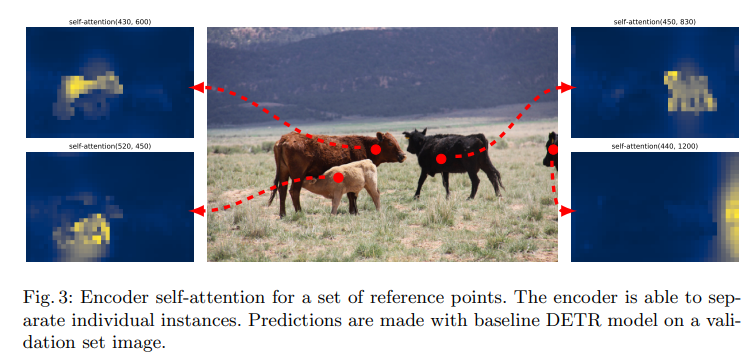
✔4개의 pixel이 어디를 attentiona하고 있는지 시각화 한 것
✔"We hypothesize that, by using global scene reasoning, the encoder is important for disentangling objects."
→ encoder가 물체를 구분하는데 중요한 역할을 할 것이라 가정
✔"The encoder seems to separate instances already, which likely simplifies object extraction and localization for the decoder."
→ encoder 수준에서 이미 instance를 분리, 간단한 object extraction and localization을 했음을 확인
Number of decoder layers
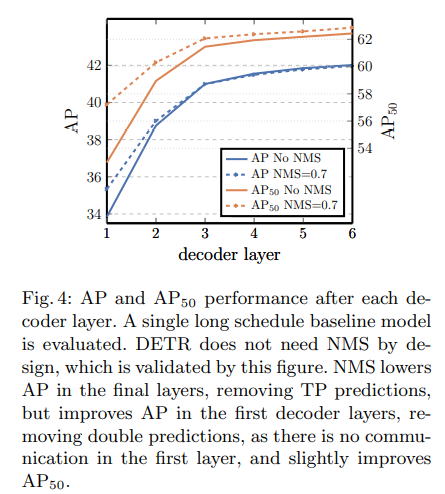
✔"a single decoding layer of the transformer is not able to compute any cross-correlations between the output elements, and thus it is prone to making multiple predictions for the same object"
→ decoder layer 1개 일 때 output간의 cross-correlations 파악하기에 부족, 동일한 object에 대해서 다수의 predictions을 출력(우리가 원하는건 1개 object에 대한 1개의 prediction), NMS 적용했을 때 보다 낮은 AP
→ decoder layer가 증가할수록 NMS 적용한 경우와 적용하지 않은 경우 AP 차이가 줄어듦, DETR은 NMS가 필요없다!

✔Visualizing decoder attention
✔"decoder attention is fairly local, meaning that it mostly attends to object extremities(사람의 사지, 동물의 네 다리) such as heads or legs"
→object의 가장자리 또는 다리나 말단 부분에 attention scores 집중되어 있음
✔"We hypothesise that after the encoder has separated instances via global attention, the decoder only needs to attend to the extremities to extract the class and object boundaries."
→encoder가 instance를 분리, decoder는 class와 object간 경계선 결정
Importance of FFN
✔1x1 convolutional layers
✔FFN 제거 2.3AP 감소
Importance of positional encodings
✔positional encodings:spatial positional encodings, output positional encodings(object queries)
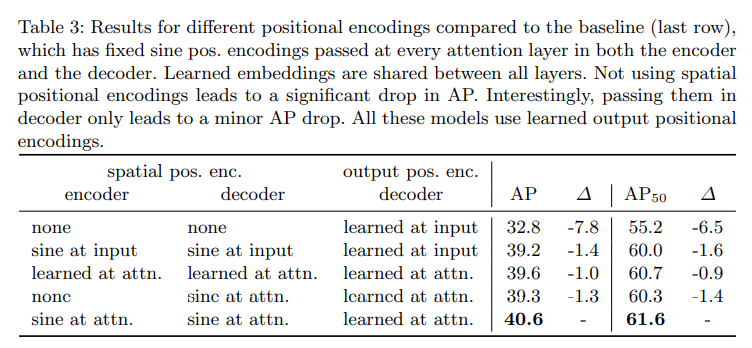
✔queries는 제거를 못하기 때문에 encoder와 decoder에서 positional encodings 변형
✔spatial positional encodings 아예 없애니 AP가 7.8 감소
✔sine spatial positional encodings, Learned spatial encodings
Loss ablations
✔classification loss, 1 bounding box distance loss, GIoU loss
✔"The classification loss is essential for training and cannot be turned off so we train a model without bounding box distance loss, and a model without the GIoU loss, and compare with baseline, trained with all three losses."
→bbox loss와 GIoU loss 하나씩 제거하고 학습시킨 모델과 세가지 loss를 모두 학습시킨 baseline model을 비교
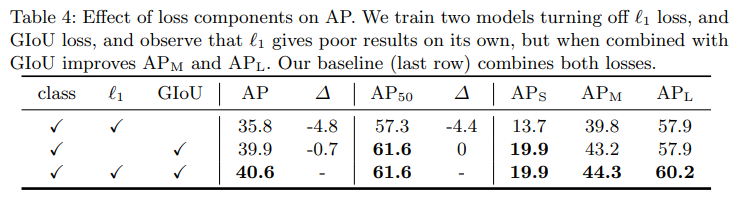
→l1 loss 하나만 사용할 때 보다 GIoU 함께 사용해야 성능 좋음
4.3 Analysis
Decoder output slot analysis

✔query slot이 주요하게 예측하는 부분 시각화
✔COCO 2017 validation set
✔100개 예측 중 20개
✔green color corresponds to small boxes, red to large horizontal boxes and blue to large vertical boxes
✔각 slot은 다른 영역과 박스 크기에 관심있음
Generalization to unseen numbers of instances.

✔인위적으로 기린 이미지 13장 생성
✔out of distribution(trainig data에 없는 unseen data)
✔모든 기린 다 찾음(genrealization ability 좋음)
4.4 DETR for panoptic segmentation
💨 Panoptic Segmentaion: semantic segmentation + instance segmentation
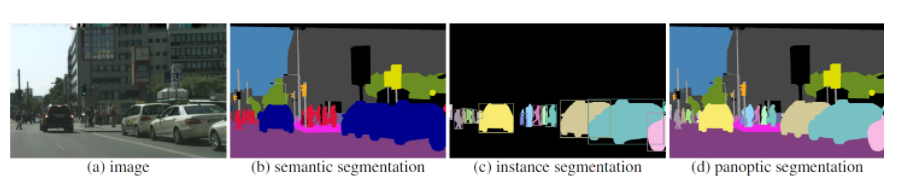
✔semantic segmentaion은 instance간의 구분하지 않고 동일한 class label 부여
✔instance segmentaion은 동일한 class라도 서로 다른 instance로 구분
✔panoptic segmentation은 [class][instance id]로 label
✔stuff:셀 수 없는 물체
✔things:셀 수 있는 물체
💨 Panoptic Segmentation metric
✔TP:IoU 0.5 이상
✔True Positive(TP), False Negative(FN), False Positive(FP) 3개로 구분
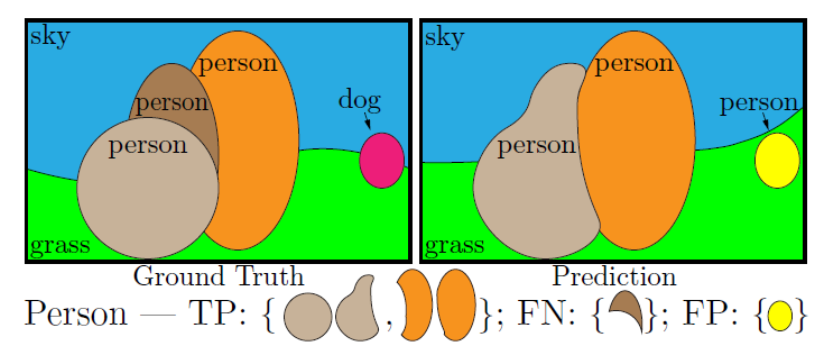
✔옅은 갈색과 주황색은 IoU 0.5 이상으로 TP에 해당, 진한 갈색FN, 노란색 FP(class 잘못 분류)

✔∑ IoU / | TP |:matched segment의 평균IoU
✔| FP | / 2 + | FN | / 2:matching 되지 않은 segment에 패널티
✔SQ:matched segment의 평균IoU
✔RQ:F1 score
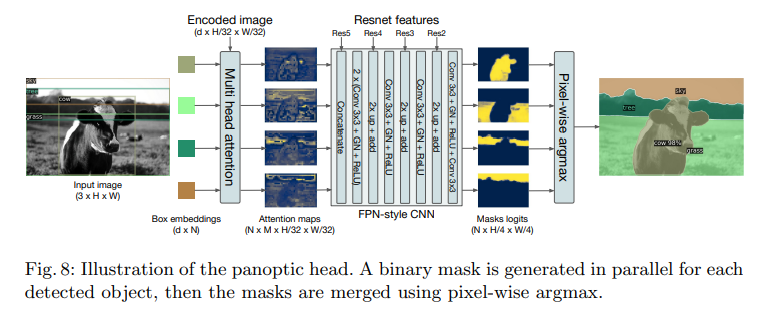
✔COCO dataset, 53 stuff, 80 things
✔adding a mask head on top of the decoder outputs.
✔increase the resolution, an FPN-like architecture is used
Training details.
Main results.
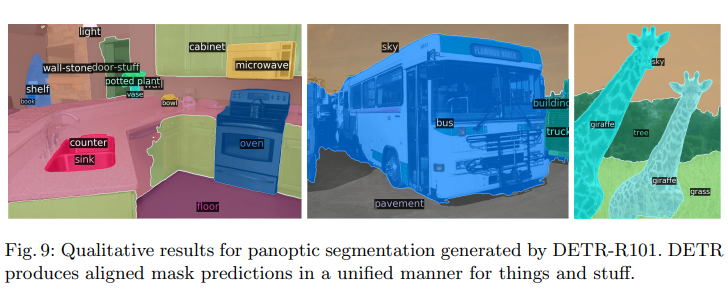
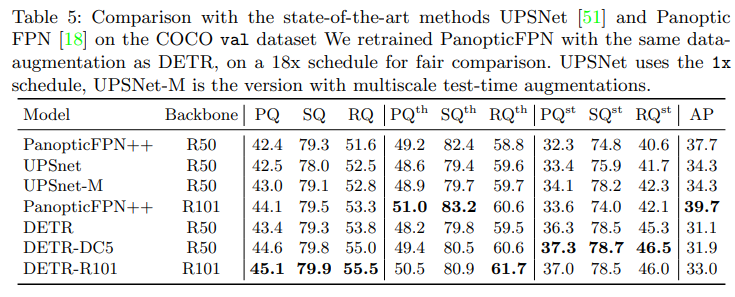
✔things (PQth), stuff (PQst)
✔SOTA를 달성한 PanopticFPN, UPSNet보다 stuff에 대하여 좋은 성능
→the global reasoning allowed by the encoder attention is the key element to this result
5. Conclusion

