이 포스팅은 Stanford University의 Machine Learning 수업 노트 입니다.
지도학습(Supervised Learning)
가장 일반적인 유형의 기계학습인 지도학습에 대해 다뤄보려고 한다.
가령 우리가 주택 가격을 에측한다고 하자.
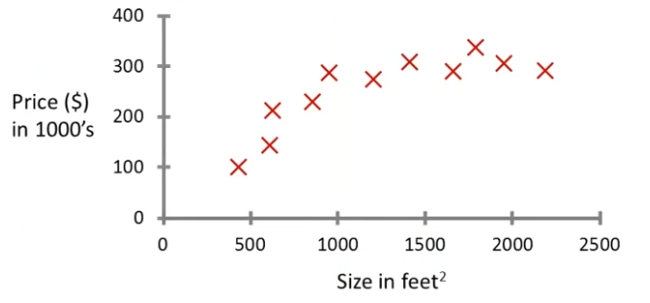
얼마 전 어떤 학생이 오리건 주 포틀랜드 시의 데이터를 수집했는데 우리가 데이터 집합을 이런식으로 도식화 했다고 하자. 이런 데이터가 주어졌을 때 어떤 친구가 750제곱피트짜리 집을 소유하고 있고, 그 집을 팔려고 하는데 얼마에 팔 수 있는지 알고 싶어 한다고 하자. 이럴 떄 학습 알고리즘이 어떻게 도울 수 있을까?
먼저 데이터를 지나는 직선을 하나 그리는 것이다. 직선 하나를 데이터에 맞춘다.
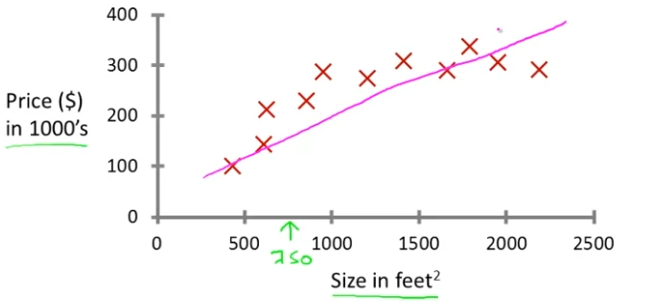
이를 통해 15만 달러 정도에 집을 팔 수 있음을 알 수 있다. 하지만 이게 쓸 수 있는 유일한 학습 알고리즘은 아니고 더 좋은 방법이 있을 수도 있다.
직선을 데이터에 맞추는 것 보단 이차함수를 맞추는 게 더 낫다고 판단할 수 있다.
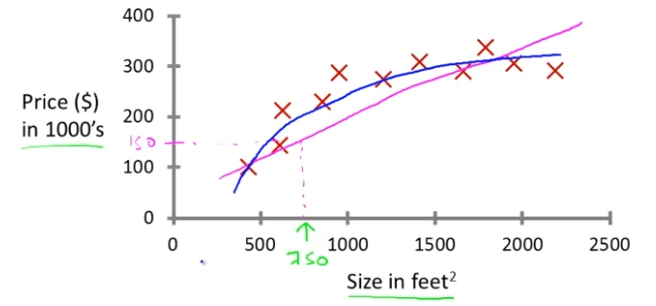
여기서 예상해보면 거의 20만 달러 가까이에 집을 구매할 수 있을 것이다.
지도학습은 우리가 알고리즘에게 데이터 집합을 주는데, 각 데이터에 정답이 포함되어 있는 것이다. 다시 말해 집에 대한 데이터 집합을 제공했는데, 각 집마다 정확한 가격도 알려줬다. 그 집이 매매된 실제 가격을 말이다. 이제 알고리즘의 역할은 그 '정답'을 더 많이 만들어내는 것이다.
회귀 문제(Regression Problem)
또 이것은 회귀 문제(Regression Problem)이라고도 한다. 회귀 문제는 연속된 값을 가진 결과를 예측하려 하는 것이다. 가격처럼 말이다. 회귀라는 용어는 우리가 이런 연속이라는 특징을 가진 값을 예측하려고 한다는 것을 뜻한다.
분류 문제(Classification Problem)
다른 지도학습의 예시를 들어보자. 의료기록을 보고 유방암이 악성인지 양성인지 예측하고 싶다고 하자.

가로축에는 종양의 크기를, 세로축에는 1과 0, Yes or No만 판별할 수 있도록 한다. 악성이면 1, 양성이면 0인 거다.
데이터 셋은 다음과 같다고 가정하자.
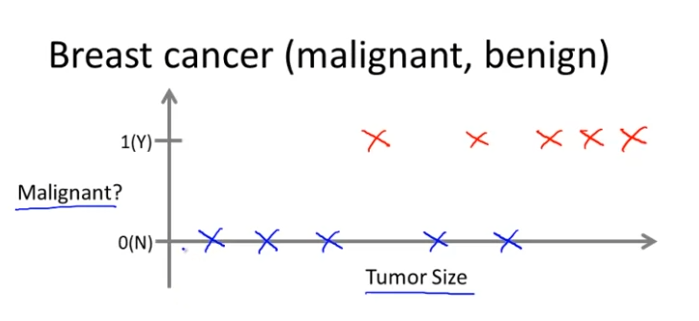
다섯개의 양성 종양과, 다섯개의 악성 종양이 있다.
어떤 친구가 비극적이게도 유방에 종양이 있는데, 사이즈가 화살표로 표시된 크기라고 가정하자.
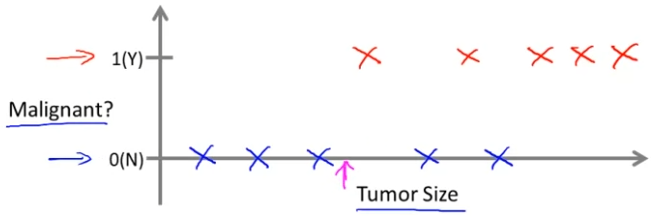
이 때 이 종양이 악성이 가능성이 얼마나 될지 예상할 수 있는지 기계학습으로 판단해보자. 이것은 분류 문제(Classification Problem)의 하나이다. 분류라는 용어는 이 경우 0 또는 1, 악성 또는 양성과 같이 불연속적인(Discrete) 결과값을 예측하려는 것이다. 어떤 분류 문제는 결과가 두 개 보다 많을 수도 있다.
분류 문제에서 이 데이터를 도식화할 수 있는 다른 방법이 있다. 약간 다른 모양의 심볼을 도식화에 사용해보도록 하자. 종양의 크기라는 속성으로 악성인지 양성인지 예측하려고 한다면, 양성종양은 O로 그리고, 악성 공양은 X로 그리면서 다음과 같이 표현할 수도 있다.

이 예시에선 단 하나의 특성(feature) 또는 속성(attribute)만 사용한다. 즉, 종양의 크기로 악성인지 양성인지 예측하고자 한다. 또 다른 기계학습 문제에서는 한 개 이상의 특징, 한 개 이상의 속성이 주어지기도 한다.
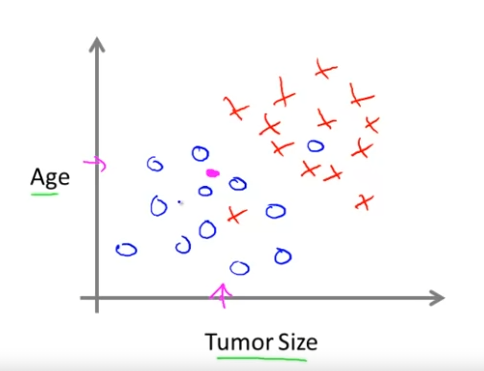
이번엔 환자의 나이와 종양의 크기를 둘 다 알 때, 양성종양은 O로 그리고, 악성 공양은 X로 표현한다. 핑크색으로 표현된 것은 어떤 친구의 종양인데, 이런 데이터 집합이 주어졌을 때, 이 친구의 종양이 악성인지 양성인지 알고 싶다.
학습 알고리즘이 해볼 수 있는 건, 데이터에 직선을 하나 맞춰서 악성 종양을 양성 종양과 분리해보는 것이다.
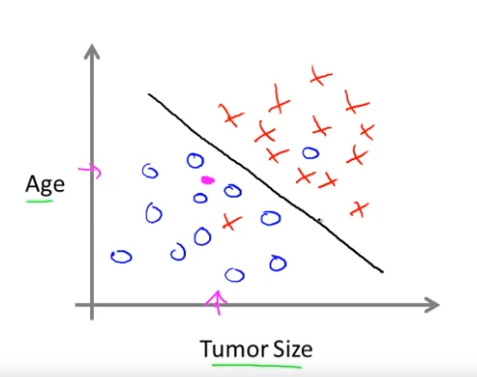
이러면 희망적으로, 그 친구의 종양에 대해서 학습 알고리즘은 양성인 쪽에 있기 때문에 양성일 가능성이 높다고 할 것이다. 이 예시에는 특성이 두 개 있었다. 환자의 나이와 종양의 크기로. 또 다른 기계학습에는 더 많은 특성이 있는 경우가 많다. 두 개, 세 개, 다섯 개를 넘어 무한히 많은 특성과 속성을 다룰 필요가 있는데, 그래야 학습 알고리즘의 특성 또는 속성이나 신호(cue)를 통해 예측할 수 있기 때문이다.
그러면, 무한한 개수의 특성은 어떻게 다뤄야 할까? 이렇게 무한한 특성을 컴퓨터 메모리에 저장하게 되면 컴퓨터의 메모리 용량을 다 써버리게 될 수 있다. 나중에 논의할 서포트 벡터 머신(Support Vector Machine)이라는 알고리즘에서 어떤 깔끔한 수학적 방법을 사용하면 컴퓨터가 무한한 개수의 특성을 다룰 수 있게 된다. 그리고, 우린 이걸 다룰 수 있는 알고리즘을 생각해낼 것이다.
예제
Choose a correct number.
You are running a company, and you want to develop learning algorithms to address each of two problems.
Problem 1 : You have a large inventory of identical items. You want to predict how many of these items will sell over the next 3 months.
Problem 2 : You'd like software to examine individual customer accounts, and for each account decide if it has been hacked/compromised.
Should you treate these as classification of as regression problems?
Problem 1은 Regression으로, Problem 2는 Classification으로 해결해야 한다. 물건이 수천 개나 있어서 이걸 연속적인(continuous) 실수로 볼 수 있기 때문이다. 즉, 내가 팔려는 물건의 수를 연속적인 값으로 말이다. 두 번째는 분류로 다룰 수 있다. 왜냐하면 예측하고자 하는 값을 0으로 설정해서 계정이 해킹 당하지 않았음을, 그리고 1로 하여 계정이 해킹당했음을 나타낼 수 있기 때문이다. 그리고 알고리즘이 이 이산적인(discrete) 값을 예측하게 할 것이다. 이산적인 값의 수가 적기 때문에 분류 문제로 다루는 것이다.
