Machine Learning
1.[Machine Learning] 기계학습의 정의
사실 아직도 기계학습이 무엇인지에 대해선 합의가 이루어지지 않았다. 그동안 나온 정의를 하나씩 살펴보겠다. Arthur Samuel의 정의 1959년에 정의 되었다. 기계학습이란 명시적 프로그램이 없어도 스스로 학습할 수 있는 능력을 연구하는 학문 분야다. 사무엘은
2.[Machine Learning] 지도학습(Supervised Learning) - 회귀문제, 분류문제

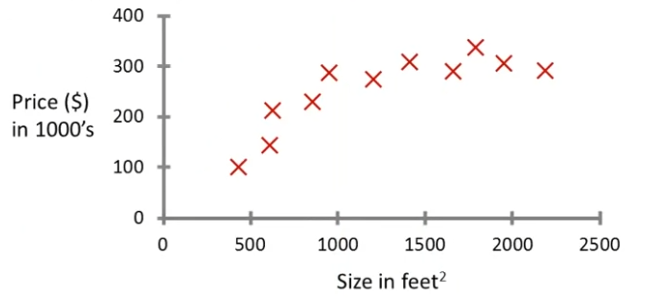
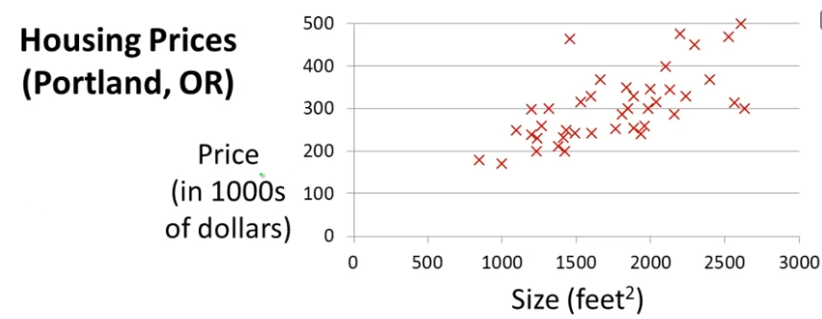
이 포스팅은 Stanford University의 Machine Learning 수업 노트 입니다.가장 일반적인 유형의 기계학습인 지도학습에 대해 다뤄보려고 한다. 가령 우리가 주택 가격을 에측한다고 하자. 얼마 전 어떤 학생이 오리건 주 포틀랜드 시의 데이터를 수집했
3.[Machine Learning] 비지도 학습(Unsupervised Learning) - 클러스터링 알고리즘, 칵테일 파티 알고리즘
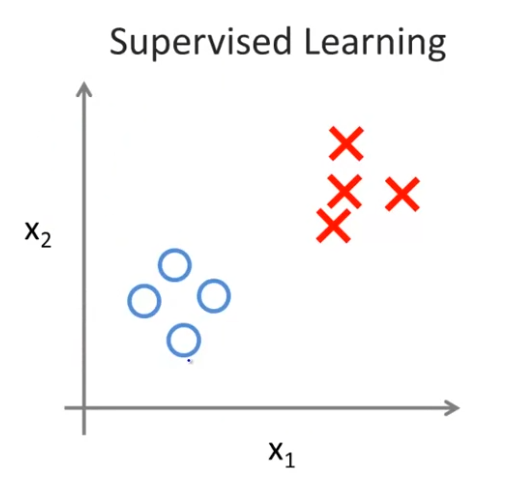
이전에 우리는 지도학습에 대해 얘기했다. 양성 또는 음성이라고 레이블(label)된 데이터를 불러와보자.이 데이터는 양성 종양인지 또는 악성 종양인지를 나타낸다. 지도학습에서는 명시적으로 어떤게 양성인지 악성인지, 소위 말하는 정답이 주어져 있다.비지도 학습에서는 데이
4.[Machine Learning] Linear Regression Model - Hypothesis h(x)
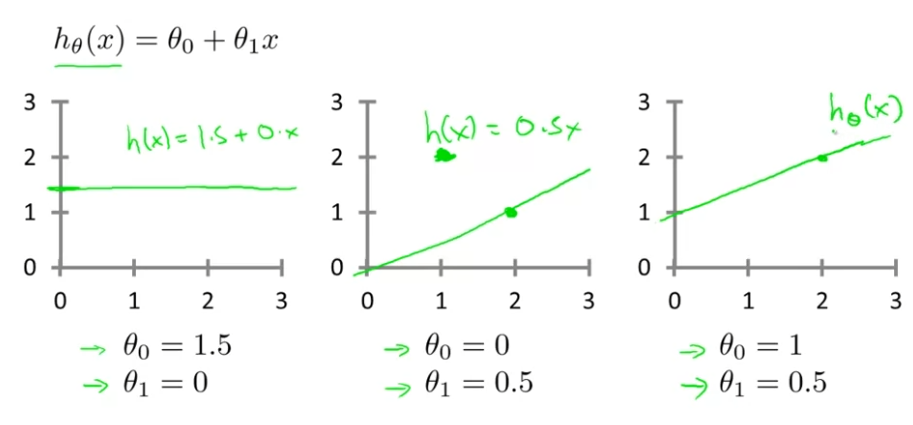
이번엔 선형회귀 Linear Regression에 대해서 살펴보고, 지도학습의 전체적인 과정에 대해 볼 것이다.
5.[Machine Learning] Linear Regression Model - Cost Function
비용함수를 나타내기 위한 공식은 이 공식이 될 것이다.
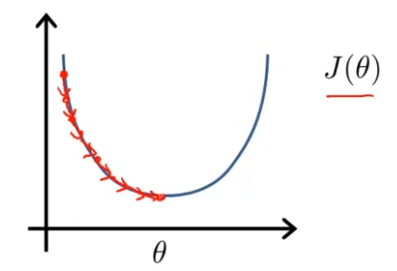
6.[Machine Learning] Gradient Descent Algorithm
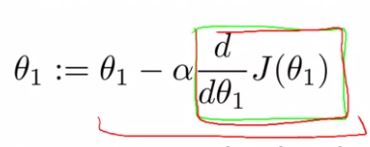
기울기 하강은 기계학습의 모든 곳에서 사용되고 있다. 선형 회귀에서만 사용되는 알고리즘이 아니다. 이 강의의 끝 쯤에 우리는 다른 함수들의 최솟값을 구하기 위해 기울기 하강 알고리즘을 사용할 것이다.위 같은 비용함수를 예시로 사용하고자 한다.여기 문제 조건이 있다. 선
7.[Machine Learning] Gradient Descent For Linear Regression

Linear Regression을 위한 Gradient Descent.
8.[Machine Learning] Multiple features
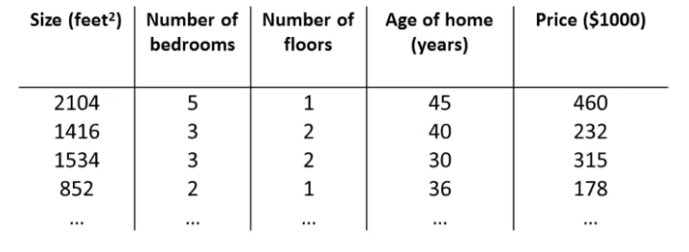
이제 feature을 여러 개 갖는 형태가 될 수 있음도 생각해볼 수 있다.
9.[Machine Learning] Gradient Descent for Multiple Variables

이번에는 Linear Regression을 위한 Gradient Descent를 여러 변수가 있을 때 어떻게 쓰는지 알아보려고 한다.
10.[Machine Learning] Gradient Descent in Practice - Feature Scaling, Learning Rate
이번엔 Gradient Descent를 잘 활용할 수 있는 몇 가지 방법을 알아보려고 한다.
11.[Machine Learning] Features and Polynomial Regression
이번엔 적절한 feature의 선택 방법을 알아본다.
12.[Machine Learning] Normal Equation
iteration 필요 없이 θ 찾아내기
13.[ML] Classification
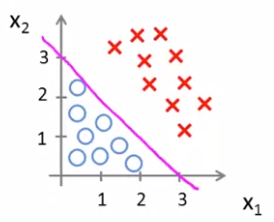
Classifictaion을 살펴본다(설명 수정 필요)
14.[ML] Neural Networks : Learning

Neural Networks : Learning
15.[ML] Advice for Applying Machine Learning

machine learning을 실생활에서 적용하는 것은 쉬운 것이 아니다. 이번 시간에는 실생활에서 machine learning을 적용하는 best practice를 알아보고, learned models의 성능을 평가하는 가장 좋은 방법에 대해 알아보자.
16.[ML] Machine Learning System Design

머신러닝 알고리즘을 최적화하기 위해서, 다양한 파트에서의 머신러닝 알고리즘 퍼포먼스를 이해하는 방법에 대해 살펴보고, skewed data를 다루는 방법을 알아보도록 하겠다.
17.[ML] Support Vector Machines
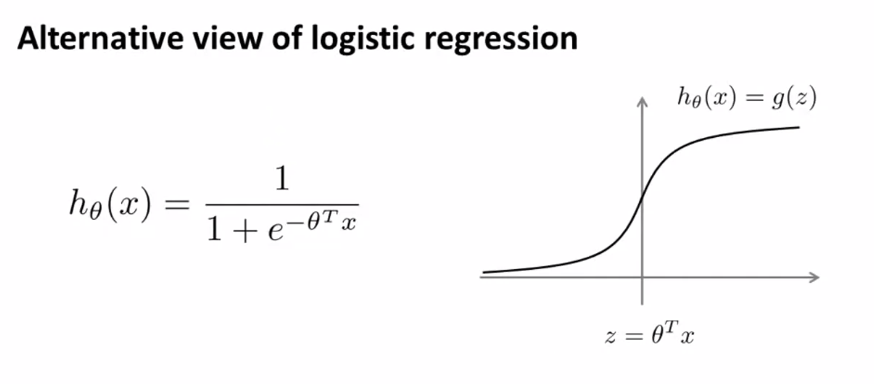
이번에는 Support Vector Machines 알고리즘에 대해 배워보도록 할 것이다. SVMs는 가장 강력한 'black box' learning algorithm으로서 오늘날 가장 널리 쓰이고 있는 알고리즘 중 하나이다. logistic regression과 n