MetaICL: Learning to Learn In Context(번역)
Abstract
이 프레임워크는 사전학습된 언어 모델이 많은 양의 트레이닝 태스크에서 인컨텍스트 학습을 하도록 조정되어, 테스트 시 새로운 태스크를 단순히 몇 개의 트레이닝 예제를 조건으로 하는 것만으로도 효과적으로 학습할 수 있도록 한다.
이러한 메타-트레이닝은 매개변수 업데이트나 태스크별 템플릿 없이도 새로운 태스크를 빠르게 학습하는 것을 가능하게 한다.
우리는 분류, 질문 답변, 자연어 추론, 유의어 탐지 등 다양한 142개의 NLP 데이터셋으로 구성된 대규모 다양한 트레이닝 태스크에서 실험을 진행했다.
MetaICL은 메타-트레이닝 없이 in context learning을 하는 베이스라인과 멀티태스크 학습 후 제로샷 전이 방법 등 다양한 베이스라인을 능가한다.
특히, 메타-트레이닝 태스크와 도메인이 다른 타겟 태스크에서 이점이 가장 크게 나타난다.
또한, 다양한 메타-트레이닝 태스크를 사용하는 것이 개선에 중요한 역할을 한다.
우리는 또한, MetaICL이 타겟 태스크에 대해 완전히 finetuned된 모델과 성능이 비슷하거나 그보다 우수한 결과를 보이며, 거의 8배나 더 많은 매개변수를 가진 모델보다 우수한 성능을 보이는 것을 보여준다.
마지막으로, MetaICL은 사람이 작성한 지시사항과 보완적인 관계에 있으며, 두 가지 접근법을 결합하면 최상의 성능을 얻을 수 있다.
소개
최근 대형 언어 모델은 적은 양의 트레이닝 예제를 조건으로 하여 테스트 입력을 완성하는 토큰을 예측함으로써, 인컨텍스트 학습(in-context learning)을 수행할 수 있다는 것이 밝혀졌다.
이러한 학습 방법은 모델이 매개변수 업데이트 없이 추론만으로 새로운 작업을 학습하기 때문에 매우 효율적입니다. 그러나 지도학습(finetuning)에 비해 성능이 현저히 떨어지고, 결과가 높은 분산성을 가지며, 기존 작업을 이러한 형식으로 변환하는 템플릿을 설계하는 것이 어려울 수 있습니다.
이 논문에서는 이러한 문제를 해결하기 위해 MetaICL: Meta-training for In-Context Learning을 소개합니다.
MetaICL은 사전학습된 언어 모델을 많은 양의 작업으로 튜닝하여 인컨텍스트 학습을 수행하는 방법을 학습하고, 엄격히 새롭게 보지 못한 작업에서 평가된다.
각 메타-트레이닝 예제는 k+1개의 트레이닝 예제를 포함하며, 이는 언어 모델에게 하나의 시퀀스로 제공되고, 마지막 예제의 출력을 사용하여 크로스 엔트로피 트레이닝 손실을 계산한다.
이러한 데이터 설정에서 모델을 직접 finetuning하는 것만으로도 인컨텍스트 학습이 더욱 개선된다.
이러한 방식은 최근 멀티태스크 학습을 사용하여 제로샷 성능을 개선하는 작업과 관련이 있다.
그러나 MetaICL은 다른 작업 포맷팅(e.g., 모든 것을 질문 답변으로 축소)이나 작업별 템플릿(e.g., 서로 다른 작업을 언어 모델링 문제로 변환)에 의존하지 않고, k개의 예제만으로도 새로운 작업을 학습할 수 있는 차이점이 있다.
우리는 Ye 등(2021)과 Khashabi 등(2020)에서 가져온 142개의 텍스트 분류, 질문 답변, 자연어 추론 및 유의어 탐지 데이터셋으로 구성된 대규모이고 다양한 작업을 실험했다.
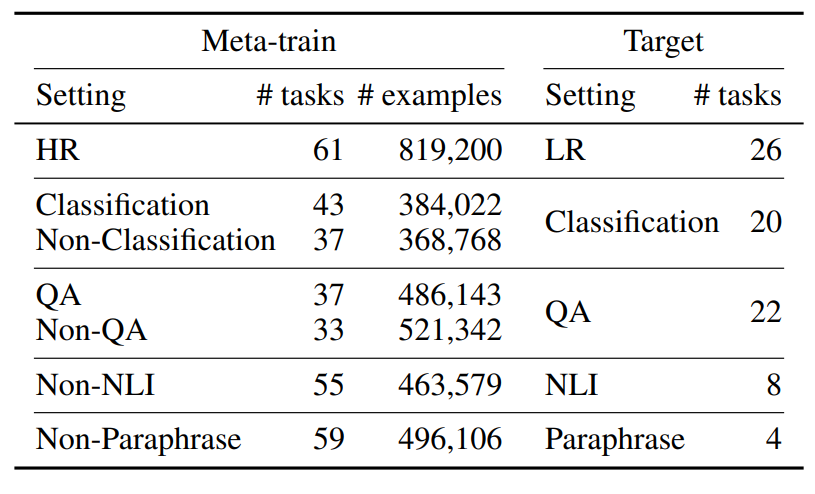
우리는 메타-트레이닝과 타겟 작업 간에 중복이 없는 일곱 가지 다른 설정을 보고했다.
이를 통해 총 52개의 고유한 타겟 작업이 생성되었으며, 우리의 지식에 따르면 모든 최근 관련 작업 중 가장 많은 수의 타겟 작업을 다룬다.
실험 결과, MetaICL이 메타-트레이닝 없이 인컨텍스트 학습 베이스라인과 멀티태스크 학습 후 제로샷 전이 방법을 포함한 다양한 베이스라인을 일관되게 능가한다는 것을 보여준다.
메타-트레이닝 태스크와 타겟 태스크가 유사하지 않은 경우, 예를 들어 작업 형식, 도메인 또는 필요한 기술에 큰 차이가 있는 경우, 멀티태스크 제로샷 전이 대비 이점이 특히 크다.
이는 MetaICL이 인컨텍스트 학습을 통해 모델이 추론 시 타겟 작업의 의미를 복구할 수 있도록 하기 때문이다.
MetaICL은 종종 타겟 데이터셋에서 지도학습(finetuning)된 모델의 성능에 가깝게(때로는 능가하며) 성능을 보이며, 8배의 매개변수를 가진 모델과도 동등한 성능을 보인다.
우리는 또한, 메타-트레이닝 태스크의 수와 다양성과 같은 MetaICL의 성공에 중요한 요소를 식별하기 위해 광범위한 실험을 수행했다.
마지막으로, 우리는 MetaICL이 어떤 템플릿도 사용하지 않고 최근의 인간이 작성한 자연어 지시사항보다 더 나은 성능을 보이지만, 두 가지 접근법을 결합하면 최상의 성능을 얻을 수 있다.
Related Work
- In-Context Learning
- Meta-training
(생략)
MetaICL
Meta-training for InContext Learning은 표 1에서 개요를 제공한다.
이 접근 방법의 핵심 아이디어는 메타-트레이닝 작업의 대규모 다중태스크 학습 방법을 사용하여 모델이 소수의 트레이닝 예제를 조건으로 하여 작업의 의미를 복구하고 출력을 예측하는 방법을 학습하도록 하는 것이다.
이전 논문들을 따르면, 훈련 예제는 연결되어 하나의 입력으로 제공되며, k-shot 학습에 적합합니다.
테스트 시간에는 모델이 k개의 훈련 예제를 가진 본래의 타겟 작업에서 평가되며, 추론은 메타-트레이닝과 동일한 데이터 형식을 따른다.

Meta-training
모델은 메타-트레이닝 작업 모음에서 메타-트레이닝을 받는다.
각 반복에서 하나의 메타-트레이닝 작업이 샘플링되며, 선택된 작업의 훈련 예제에서 k + 1개의 훈련 예제 (x1, y1), · · · ,(xk+1, yk+1)가 샘플링된다.
그런 다음, x1, y1, · · · , xk, yk, xk+1을 연결하여 입력으로 모델에 제공하고, 모델이 yk+1을 생성하도록 negative log likelihood 목적 함수를 사용하여 모델을 지도 학습한다.
이는 추론 시 인컨텍스트 학습을 모방하며, 첫 k개의 예제가 훈련 예제로 사용되고 마지막 (k + 1)-번째 예제가 테스트 예제로 간주됩니다.
Inference
새로운 타겟 작업에 대해서는, 모델은 k개의 훈련 예제 (x1, y1), · · · ,(xk, yk)와 테스트 입력 x가 주어진다.
또한, 분류의 경우 레이블의 집합이나 질문 응답의 경우 답변 옵션의 집합인 후보 집합 C가 제공된다.
메타-트레이닝과 마찬가지로, 모델은 x1, y1, · · · , xk, yk, x를 연결하여 입력으로 사용하고, 각 레이블 ci ∈ C의 조건부 확률을 계산한다.
조건부 확률이 최대인 레이블이 예측값으로 반환된다.
Channel MetaICL
우리는 Min et al. (2022)을 따라 Channel MetaICL이라는 메타-트레이닝의 노이즈 채널 변형을 소개한다.
노이즈 채널 모델에서는 P(y|x)를 P(x|y)P(y)P(x) ∝ P(x|y)P(y)로 재매개화한다.
우리는 Min et al. (2022)과 같이 P(y) = 1/|C|로 설정하고, P(x|y)를 모델링하여 xi와 yi를 간단히 뒤바꾸는 채널 접근 방법을 사용할 수 있다.
구체적으로, 메타-트레이닝 시간에 모델은 y1, x1, · · · , yk, xk, yk+1을 연결하여 입력을 받으며, xk+1을 생성하도록 학습된다.
추론 시에는 모델이 argmaxc∈CP(x|y1, x1, · · · , yk, xk, c)를 계산한다.
환경 설정
데이터셋
(생략)
베이스 라인
- zero-shot
- in-context
- PMI zero-shot, PMI in-context
- Channel zero-shot, Channel in-context
- Multi-task zero-shot
- Channel Multi-task zero-shot
- Fine-tune
- Fine-tune w / meta-train
평가
상세 경험
실험 결과
메인 결과
Ablations
결론
본 논문에서는 MetaICL이라는 새로운 퓨샷 학습 방법을 제안했다.
이 방법은 LM이 메타-트레이닝을 받아 훈련 예제에 대한 조건부로 작업을 복구하고 예측하는 것을 학습한다.
우리는 142개의 고유한 작업과 52개의 고유한 타겟 작업을 포함하는 다양한 작업 모음으로 실험을 진행했다.
메타-트레이닝 없는 인컨텍스트 학습과 멀티태스크 학습 및 제로샷 전이를 비롯한 여러 강력한 베이스라인을 능가하며, 8배 더 큰 모델과도 성능을 비교하거나 뛰어넘었다.
우리는 메타-트레이닝 작업의 수와 다양성과 같은 MetaICL의 성공 요소를 식별했다.
또한, MetaICL이 최근의 자연어 지시어 사용 보다 우수함을 보였으며, 이를 보완하여 MetaICL과 지시어를 통합하면 최고의 성능을 얻을 수 있다는 것을 보였다.
한계점 & 제한점
우리의 연구는 여러 가지 차원에서 제한적이다.
첫째, 인컨텍스트 학습 방법은 일반적으로 훈련 데이터의 연결을 입력으로 사용하기 때문에 메타-트레이닝과 추론 모두에서 매우 긴 컨텍스트를 필요로 하므로, 인컨텍스트 학습을 사용하지 않는 베이스라인에 비해 효율성이 떨어진다.
둘째, 우리의 연구는 크기가 중간 정도인 캐주얼 언어 모델(GPT-2 Large, 770M 파라미터)로 실험을 진행했다.
미래의 연구는 마스크 언어 모델 및 더 큰 모델에 대한 접근법을 연구할 수 있다.
셋째, 우리의 실험은 후보 옵션이 주어지는 분류 및 다중 선택 작업(오지선다형 문제)에 중점을 두고 있다.
미래의 연구는 자유형식 생성을 포함한 더 넓은 범위의 작업에 우리의 접근법을 적용하는 것을 연구할 수 있다.
미래의 연구 방향으로는, 메타-트레이닝을 사용하여 지도 모델을 능가하는 MetaICL의 성능을 더 개선하는 것, 타겟 작업에 도움이 되는 메타-트레이닝 작업의 식별, 인간 작성 지시어와 MetaICL을 더 잘 결합하는 방법 등이 있다.
출처
