안녕하세요
오늘은 AWS EC2 상태를 모니터링 할 수 있도록 AWS CloudWatch를 연결하고, 상태에 따른 경보를 lambda를 이용해 slack으로 전송하도록 구축한 경험을 공유해드리겠습니다.
문제 상황
[프로젝트] 도메인과 HTTPS 설정으로 배우는 Nginx와 ALB(AWS Elastic Load Balancer)
이 포스팅을 보신 분들이라면 아시겠지만, AWS EC2 인스턴스로 t2.micro를 이용하고 있는 상태에서 docker와 spring 서버를 버티지 못하는지 인스턴스가 자주 죽는 현상이 발생했습니다.
문제를 해결하고자 인스턴스 로그를 확인하여 무엇이 문제인지 확인해보았습니다.
에러 로그를 검색해보니 인스턴스 디스크 용량이 부족하다는 에러라는 글이 많아 인스턴스 디스크 용량을 늘려 주었습니다.
이후로 빈도가 많이 줄긴했지만 여전히 간헐적으로 죽는 경우가 있었습니다.
그래서 인스턴를 관리하고, 상태를 확인하고, 상황이 발생했을 때 경보 알림을 통해 빠르게 복구하고자 CloudWatch를 도입하고자 했습니다.
AWS CloudWatch
1. CloudWatch가 뭔데?
CloudWatch는 EC2의 상태를 수집하고 보여줄 수 있는 도구라고 생각하시면 됩니다.
기본적으로 EC2를 생성하면 EC2 대시보드에서 CPU 사용량 등을 수집하고 보여주는 창이 있습니다.
그러나 인스턴스의 Memory 사용량 등은 해당 기능에서 제공되지 않습니다.
따라서 AWS에서는 CloudWatch라는 도구를 제공하여 해당 도구를 이용해 다른 필요한 지표를 수집하고 대시보드를 생성할 수 있습니다.
또한 CloudWatch에서는 경보를 제공합니다.
경보는 수집하고 있는 지표에서 설정한 값보다 큰 값이 발생한다던지, 아니면 문제가 발생했을 때 경보를 활성화하고 연결한 SNS(Simple Notification Service)로 알림을 보낼 수 있는 기능입니다.
이를 통해 인스턴스에 문제가 발생했을 때 빠르게 알아차리고 대응할 수 있죠.
2. CloudWatch를 도입하면서...
CloudWatch를 인스턴스에 도입하는 것은 어렵지 않습니다.
많은 블로그에서 해당 방법을 자세히 알려주고 있어서 따로 포스팅하지는 않겠습니다.
방법은 아래 참고에서 다른 분들의 블로그들을 참고해 주세요!
간단하게만 설명드리면
CloudWatchAgent를 EC2에 직접 설치하고 config를 생성하는 방법과,
AWS System manager를 이용해서 설치하고 config를 생성하는 방법으로 크게 두가지가 있습니다.
AWS System manager는 여러 권한 설정이 필요해서 저는 CloudWatchAgent를 EC2에 직접 설치해서 도입했습니다.
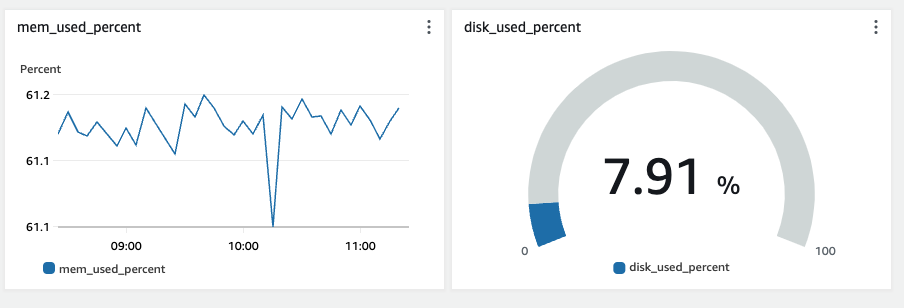
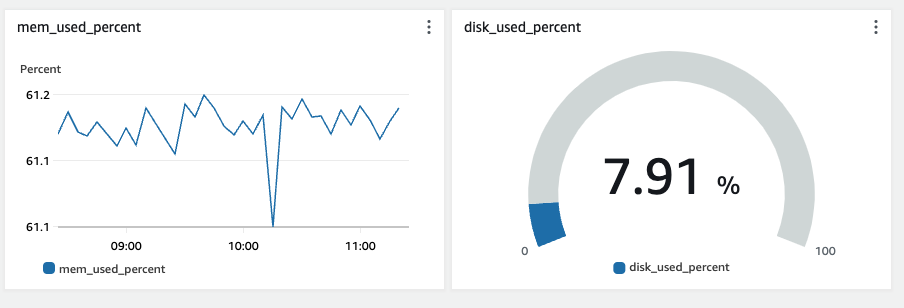
CloudWatch를 도입하고 Memory 사용량과 disk 사용량을 대시보드에 표시한 결과입니다.
이제 CloudWatch를 통해 인스턴스를 모니터링 할 수 있게 되었습니다.
프로젝트를 진행하면서 점점 커지고, docker 등을 도입하면서 t2.micro 인스턴스의 Scale Up 필요성을 느끼고 있었습니다.
또한 실제 서비스 상황에서도 t2.micro로는 성능이 부족할 것이라 생각했습니다.
하지만 아무래도 사양이 높아질수록 비용이 증가하기 때문에 적절한 인스턴스 사양을 찾고싶었습니다.
CloudWatch를 도입해서 현재 사용하고 있는 인스턴스를 모니터링하여 현재 인스턴스 스팩에서 어떤 부분이 부족한지 파악하고자 했습니다.
물론 이것만 가지고는 상당히 부족하다고 생각합니다.
적잘한 인스턴스를 찾으려면 현재 서버의 성능이 얼마나 나오는지, 어떤 기술을 사용하고 있는지, 사용자는 얼마인지 등등 여러 지표가 필요할 것이라 생각했습니다.
추후 성능 테스트와 각종 서버 분리 작업을 하면서 해당 지표를 수집하고 적절한 사양을 찾아볼 생각입니다.
AWS Lambda
1. Lambda???
AWS lambda는 AWS에서 제공하는 서버리스 컴퓨팅 플랫폼입니다.
여기서 서버리스란 정말 서버가 없다는 것이 아니라 사용자는 서버를 신경쓸 필요없이 코드 구현만 하면 된다는 의미입니다.
따라서 매일 서버를 켜놓아야 하는 작업이 아니라, 특정 이벤트가 발생했을 때 메일을 발송한다던가, 알림을 보내는 등의 작업에 적합합니다.
2. Lambda로 뭘 할건데요?
앞에서 CloudWatch를 인스턴스에 연결하여 필요한 지표를 수집했습니다.
수집한 Memory 사용량을 보니 제 인스턴스는 보통 61%의 Memory 사용량을 보이고 있습니다.
만약 어떤 일로 인해 Memory 사용량이 급증하게 된다면 인스턴스에서 오류가 발생할 가능성이 있습니다.
따라서 원인을 파악하고 인스턴스를 관리해주어야 하죠.
그럼 Memory 사용량이 급증할 때 까지 CloudWatch를 계속 보고있어야 할까요?
다른 할일이 많으니 그럴 수 있는 사람이 많지는 않을 겁니다.
따라서 저는 AWS lambda를 활용해서 Memory 사용량이 특정 값을 넘어가면 저에게 slack 알림이 오도록 구축하였습니다.
또한 Memory 사용량 뿐만 아니라 다른 것의 영향으로 인스턴스가 죽는 문제가 발생할 수도 있어서 인스턴스 상태검사에서 연결성 검사가 Fail이 되면 slack 알림이 오는 기능도 추가로 구현했습니다.
AWS Lambda를 구축하는 과정도 어렵지 않습니다.
아래 참고에 링크한 블로그를 참고해주세요!
모니터링을 하자
서비스를 개발하고 배포하는 것도 중요하지만 배포한 서비스를 잘 운영하는 것 또한 굉장히 중요합니다.
아직은 사용자가 없어서 트래픽이 발생하는 상황은 아니지만 추후 서비스를 오픈하고 사용자가 생긴다면, 사용자가 불편하지 않도록 점검하고 관리해야 하기 때문이죠.
모니터링을 통해 지속적으로 인스턴스를 관리할 수 있기에 모니터링을 꾸준히 해야겠습니다.
참고
- https://bigco-growth-diary.tistory.com/40
- https://velog.io/@khyup0629/AWS-CloudWatch-%EC%9A%94%EA%B8%88-%EC%A0%95%EB%B3%B4
- https://dev.classmethod.jp/articles/try-installing-cloudwatch-agent-on-ec2-instances/
- https://systorage.tistory.com/entry/AWS-CloudWatch%EB%A1%9C-EC2-%EB%94%94%EC%8A%A4%ED%81%AC-%EC%82%AC%EC%9A%A9%EB%9F%89-%EB%AA%A8%EB%8B%88%ED%84%B0%EB%A7%81-%EB%B0%8F-%EC%95%8C%EB%A6%BC%EB%B0%9B%EA%B8%B0
- https://engineerinsight.tistory.com/164
- https://www.youtube.com/watch?v=8t1kmIDtfqc
- https://dev.classmethod.jp/articles/jw-how-to-collect-logs-from-the-cloudwatch-agent/
- https://dev.classmethod.jp/articles/manage-the-cloudwatch-agent-from-the-parameter-store/
- https://junhyeong-jang.tistory.com/13
- https://cloud-oky.tistory.com/3440
- https://velog.io/@wngud4950/AWS-Lambda%EB%A1%9C-Slack-%EC%9E%90%EB%8F%99%EC%95%8C%EB%A6%BC-%EC%83%9D%EC%84%B1%ED%95%98%EA%B8%B0
- https://pacloud.tistory.com/3#google_vignette
- https://blog.cowkite.com/blog/2001151846/
