
1. 재귀적 접근의 원리와 실제
재귀적 접근이란?
recursion
- 함수의 정의부에서, 함수 자기 자신을 재귀적으로 호출할 수 있음
- 재귀호출은 분할정복 패러다임 구현을 위한 도구로 흔히 사용됨
문제 해결을 위한 접근과 하향식 접근
- 문제 해결을 위한 접근은 상향식 bottom-up과 하향식 top-down으로 구분 가능
- 재귀호출은 일반적으로 하향식 top-down 접근법에 해당
🧩재귀호출을 이용한 예문
수열의 값이 1, 1, 2, 3, 5, 8, 13, 21, 34...와 같이 주어질 때 N번째 항의 값을 출력하면?
def ex_func(N) :
if(N == 1) or (N == 2)
return 1
return ex_func(N - 1) + ex_func(N -2)문제의 최상단에서 시작하는 top-down 알고리즘
ex_func(7)을 알기 위해서는 f(6), f(5)를 그 다음에서 f(5), f(4)....
📍주어진 수열의 여섯 번째 항의 값을 계산하는 과정에서 ex_func가 호출되는 총 횟수는?
14번
📍시간복잡도를 Big-Theta 표기법으로 나타내면?
빅세타(1.618**n)
분할정복의 이해
Divide and Conquer
여러운 문제를 쉽게 쪼개고, 다시 합하는 알고리즘
🧩분할정복을 이용한 예문
자연수 x와 음이 아닌 정수 n을 인자로 받아, x**n의 값을 반환하는 함수 exp를 정의하면?
def exp(x, n) :
if(n == 0) :
return 1
<!--짝수인 경우-->
elif (n % 2) == 0 :
return exp(x, n //2) ** 2
<!--홀수인 경우-->
else :
reutnr (exp(x, n //2) * x예시)
exp(5, 4) = exp(5, 2) 2 = exp(5, 1) 2) 2 = (((exp(5, 0) 2) *5) 2) 2
...
📍**시간복잡도를 Big-Theta 표기법으로 나타낸다면?
빅세타(logn)
3. 분할정복을 이용한 정렬
✅Merge Sort
수열을 절반으로 쪼개고 다 쪼개졌을 때 순서대로 합쳐서 수열을 정렬하는 방법
🧩합병 정렬을 위한 Python 프로그램
numbers = [800, 32, 4, 122, 766, 12, 98, 53, 772, 8]
<!--❗️분할 과정-->
def merge_sort(num_list) :
if len(num_list) <= 1 :
return num_list
<!--재귀 호출-->
mid = len(num_list) // 2
left_list = merge_sort(num_list[:mid])
rigth_list = merge_sort(num_list[mid:])
return_array = list()
<!--❗️합병 과정-->
while (True) :
<!--한쪽이 비면 그대로 채운다-->
if len(left_list) == 0 :
return_array = return_array + rigth_list
break
if len(rigth_list) == 0 :
return_array = return_array + left_list
break
<!--전교 1등끼리의 비교-->
if (left_list[0] <= right_list[0]) :
return_array.append(left_list[0])
del(left_list[0])
else :
return_array.append(right_list[0])
del(right_list[0])
return return_array
*파이썬 del()은 인덱스 삭제
합병 정렬이 갖는 시간복잡도
🫡분할
합병에 비해 무시할 수준의 시간복잡도
🫤합병
길이가 x인 수열 두 개가 하나로 합쳐지는 경우
1. 최선의 경우 약 x회, 최악의 경우 약 2x회 비교
2. 한 개 층에 원소가 n개라면 합병에 빅세타(n) 소요
3. 한 개 층의 합병을 완료하는 데에는 빅세타(n) 소요
원소 n개의 수열을 합병 정렬하는 데 드는 시간복잡도는 빅세타(nlongn)
✅Quick Sort
피벗에 따라 수열 정렬
1. 피벗 : 수열의 가장 오른쪽 원소
2. 양쪽에서 ><로 출발(기준은 피벗)
3. >이 피벗보다 크거나 <이 피벗보다 작으면 stop하고 둘을 바꿈
4. 화살표 모양이 <>이 되면 피벗과 가까운 쪽 화살표를 맞바꾼다.
5. 맞바꾼 피벗 위치를 기준으로 분할하여 퀵 정렬을 반복한다.
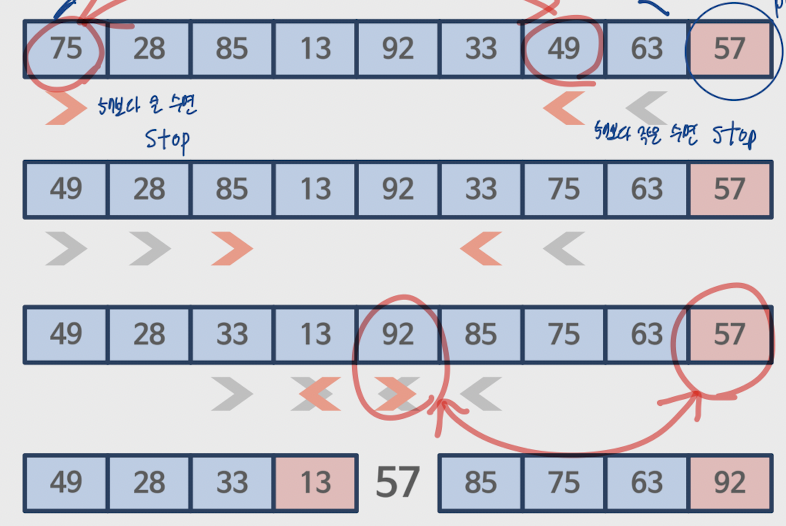
퀵 정렬의 시간복잡도
한 층에서 다음 층으로 넘어가는 데 드는 시간복잡도는 빅세타(n)
➡️층 수 계산이 시간복잡도 분석의 핵심이다
😁최선 시간복잡도
매번 수열의 중앙 인근에서 분할이 이루어지는 것이 최선
층 수는 합병 정렬에서와 동일하게 logn
-> 빅세타(nlong)
😡최악 시간복잡도
주어진 수열의 한쪽 끝 근처에서 분할이 이루어지는 것이 최악
이 경우 층 수는 n
-> 빅세타(n**2)
🧩연습문제
다음과 같은 순서대로 원소들이 배열되어 있고 오름차순으로 정렬하고자 한다.
[15, 30, 60, 5, 35, 18]
퀵 정렬을 이용하여 오름차순 정렬을 수행한다고 할 때, 정렬이 완료된 시점에서 원소간의 총비교 횟수는?
(단, 퀵 정렬에서 기준 원소는 항상 마지막 원소를 사용하는 것으로 가정한다.)
3스텝
(직접 손으로 풀어보기)
4. 분할정복을 통한 문제 해결
분할정복만으로 해결하는 문제가 많지는 않다.
🧩예제
호랑이건설에서는 다음과 같은 방식으로 철근 공사를 진행한다.
1. 철근은 기본 철근과 이음 철근으로 나뉘는데, 기본 철근은 A철근 -B철근 - C철근으로 구성되어 있다.
2. 공사 1단계에서는 기본 철근 - 이음 철근 1개 - 기본 철근의 순서로 총 7개의 철근을 잇는다.
3. 공사 K단계에서는 (직전 단계 철근 구조) - 이음 철근 K개 - (직전 단계 철근 구조)의 순서로 철근들을 잇는다.
예를 들어 공사 2단계를 마친 후의 철근 구조는 다음과 같다.

자연수 N을 입력받아 N번째 철근의 종류를 출력하는 Python 프로그램을 작성하시오.
📍철근 구조는 (하위 단계 철근) - 이음 - (하위 단계 철근) 으로 분할 가능하다.
📍분할정복 패러다임을 이용해서 전체 철근 리스트를 작성하지 않고 N번째 철근의 종류를 파악한다.
1️⃣공사 단계 파악
0단계 철근 수 3개 -> 1단계 철근 수 3 2 + 1 = 7개 -> 2단계 철근 수 7 2 + 2 = 16개
2️⃣문제 분할
현재 단계의 총 철근 수 16개는 (1단계 구조) + (이음 구조) + (1단계 구조)로 분할 가능
현재 단계가 2단계임음 알고 있으므로 (철근 7개) + (철근 2개) + (철근 7개)로 분할 가능
13 > 7 + 2 이므로 찾고자 하는 철근의 종류는 1단계 구조에서의 4번째 처근 종류와 동일하다.
3️⃣재귀적 풀이
1단계에서의 총 철근 수 7개는 (0단계 구조) + (이음 철근) + (0단계 구조)로 분할 가능
현재 단계가 1단계임음 알고 있으므로 (철근 3개) + (철근 1개) + (철근 3개)로 분할 가능
4 = 3 + 1이므로, 찾고자 하는 철근의 종류는 이음 철근
Python 코드
def find_level(N) :
level = 0
length = 3
while (N >= length) :
level = level + 1
length = length * 2 + level
return (level, length)
def find_type(level, length, N) :
if (level == 0) :
if (N == 1) :
return 'A'
elif (N == 2) :
return 'B'
else :
return 'C'
piece_length = (length - level) // 2
if (N <= piece_length) :
return find_type(level - 1, piece_length, N)
elif (N <= (piece_length + level)) :
return '이음'
else :
new_N = N - piece_length - level
return find_type(level - 1, piece_length, new_N)