
1. 정렬의 성능과 시간복잡도
1. Heap Sort
Max Heap 자료구조를 이용해 다음의 절차를 거쳐 정렬을 수행
1. 비어 있는 Heap에 주어진 원소를 순서대로 삽입하되 도중에 Heap의 성질이 유지되게끔 함
2. Heap의 최상단에는 최댓값이 존재함이 보장되므로, 새로운 수열의 맨 끝에 Heap 최상단 값을 위치시킴
3. Heap 최상단 원소를 제거한 후, Heap의 성질을 유지시키며 동일한 과정을 반복
✅비어 있는 Heap 데이터를 n개 삽입 -> Heap이 다시 빌 때까지 데이터를 n개 제거
1. 데이터를 삽입할 때마다 드는 시간복잡도
😡최악의 경우
최하단에서 시작하여 Root까지 거슬러올라갈 수 있음
최하단부터 Root까지 올라가는 데 필요한 연산 횟수는 트리의 높이
노드 n개 -> 높이 logn
2. 데이터를 제거할 때마다 드는 시간복잡도
삽입의 경우와 정반대로 최상단에서 시작하여 바닥까지 내려갈 수 있다.
방향만 반대로 제거 시간복잡도는 앞과 같은
빅세타(logn)
3. 힙 정렬의 시간복잡도 식은?
✅비어 있는 Heap 데이터를 n개 삽입 -> Heap이 다시 빌 때까지 데이터를 n개 제거
(log1 + log2 + log3 + ... + logn) + (logn + log(n-1) + log(n-2) + ... + log1)
➡️ 2(log1 + log2 + log3 + ... + logn)
➡️ log1 + log2 + log3 + ... + logn
➡️ log(1 2 3 ... n)
➡️ log(n!) => 빅세타(nlogn)
4. 점근적 식을 더 단순화하기
✅모든 n >= n에 대하여, T(n) <= cg(n)이 되게 하는 c와 n이 존재하면 T(n) = O(g(n))
📍log1 + log2 + log3 + ... +logn <= logn + logn + logn + ... + logn = nlogn
부등호 앞을 T(n)이라고 하고 숫자를 다 n으로 바꿔버리자!
그러면 부등호 뒤의 식이 되고 logn이 n개 있으니까 nlogn이 된다.
✅(힙 정렬의 시간복잡도) = O(nlogn) = Ω(nlogn) = 빅세타(nlogn)
📍log1 + log2 + log3 + ... +logn >= log(n/2) + log(n/2) + log(n/2) + ... + log(n/2) = nlogn
부등호 왼쪽의 식에서 반을 무시하고 나머지 반은 log(n/2)로 바꾸기 (왜?)
log(n/2)가 n/2개 있으니까 (n/2)log(n/2) -> nlongn
✅모든 n >= n에 대하여, T(n) <= cg(n)이 되게 하는 c와 n이 존재하면 T(n) = Ω(g(n))
5. 정렬이 갖는 시간복잡도의 하한
비교 정렬이 갖는 최악의 시간복잡도의 하한
1. 원소가 n개인 수열을 비교해 기초해 정렬하는 상황은 결정트리 형태로 나타낼 수 있다.
2. 원소가 n개이므로 결정트리의 리프 노드는 n!개
😡최악의 경우 비교 횟수는 log(n!)을 따름
😡최악의 경우 비교 정렬은 아무리 빨라도 빅세타(nlogn)
=> 비교 정렬에서 nlogn보다 빠른 것은 없다.
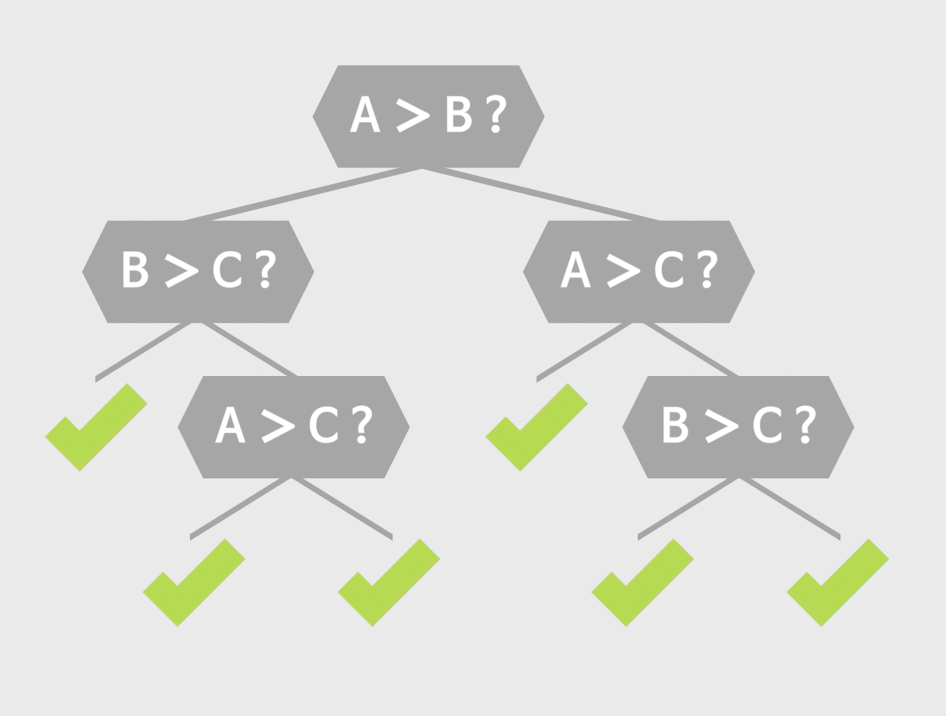
2. 욕심쟁이 알고리즘의 뜻
😈Greedy Algorithm
- 이 순간에서 가장 최적인 것을 찾는다.
- 욕심쟁이 알고리즘으로 얻는 해가 전체 문제에 대해 최적의 해라는 것은 보장할 수 없다.
3. 욕심쟁이 알고리즘의 실체
🧩 예제
일반적으로 화폐로 통용되는 동전은 500원, 100원, 50원, 10원 등 네 종류이다. 편의점에서 일하고 있는 가을이는 최대한 적은 수의 동전만으로 손님에게 거스름돈을 지급하려 한다.
입력받은 금액만큼의 거스름돈을 지급하기 위해 필요한 최소 동전 수를 출력하는 Python 프로그램을 작성하면?
동전만으로 거스름돈 지급이 불가한 경우 Fail을 출력해야 한다.
📍욕심쟁이 알고리즘의 원리에 입각하여 단위가 큰 동전을 우선 사용하여 거스름돈을 지급한다.
<!--단위가 큰 동전부터 순서대로 배치-->
coin = [500, 100, 50, 10]
money = input()
money = int(money)
coin_count = 0
for each_coin in coin :
while (momey >= each_coin) :
money = money - each_coin
coin_count = coin_count + 1
if (money == 0) :
print(coin_count)
else :
print('FAIL')
<!--반복문을 마쳤음에도 거스름돈이 남아있다는 것은
애초에 주어진 동전 종류만으로 지급이 불가했다는 것-->
📍만약에 동전이 900원, 700원, 500원, 100원 단위라면?
-> 동전 각각이 배수, 약수가 아니기 때문에 greedy에 최적이지 않다.
🧩 연습문제 1
성북구에 위치한 햄버거 가게 <맥도리아>에 N명의 고객들이 줄을 서 있다.
<맥도리아>의 직원 은채는 고객들의 평균 대기 시간이 최소가 되도록 주문 순서를 결정하려 한다.
예를 들어 주문 시간이 3분인 고객 A, 6분인 고객 B, 2분인 고객 C가 존재한다고 하자.
고객 별 주문 시간을 띄어쓰기로 구분해 입력받아 최소 평균 대기 시간을 출력하는 Python 프로그램을 작성하시오.
최소 평균 대기 시간이 정수가 아닐 경우, 가장 가까운 정수로 반올림해 출력한다.
📍입력예시: 2 9 3 8
📍출력예시 : 5
num_list = input()
num_list = num_list.split()
<!--문자열을 정수화시켜주기-->
for i in range(0, len(num_list)) :
num_list[i] = int(num_list[i])
<!--대기시간이 짧은 순대로 정렬-->
num_list.sort()
total_time = 0
multi_num = len(num_list) - 1 <!--곱하는 수 = 길이 - 1 -->
<!--예를 들어 [2 9 3 8]이 있을 때
2 * 3 + 3 * 2 + 8 * 1 + 9 * 0-->
for each_num in num_list :
total_time = total_time + (each_num * multi_num)
multi_num = multi_num - 1
avg = total_time / len(num_list)
avg = round(avg) <!--반올림-->
print(avg)4. 욕심쟁이 알고리즘의 응용
욕심쟁이 알고리즘에서 최적의 결과를 내지 않았을 때, 관점을 바꾸면 최적의 해를 만들 수 있다.
예를 들어 다음과 같은 경우에서 시간이 겹치지 않으면서 가장 많은 수업을 듣기 위해서는
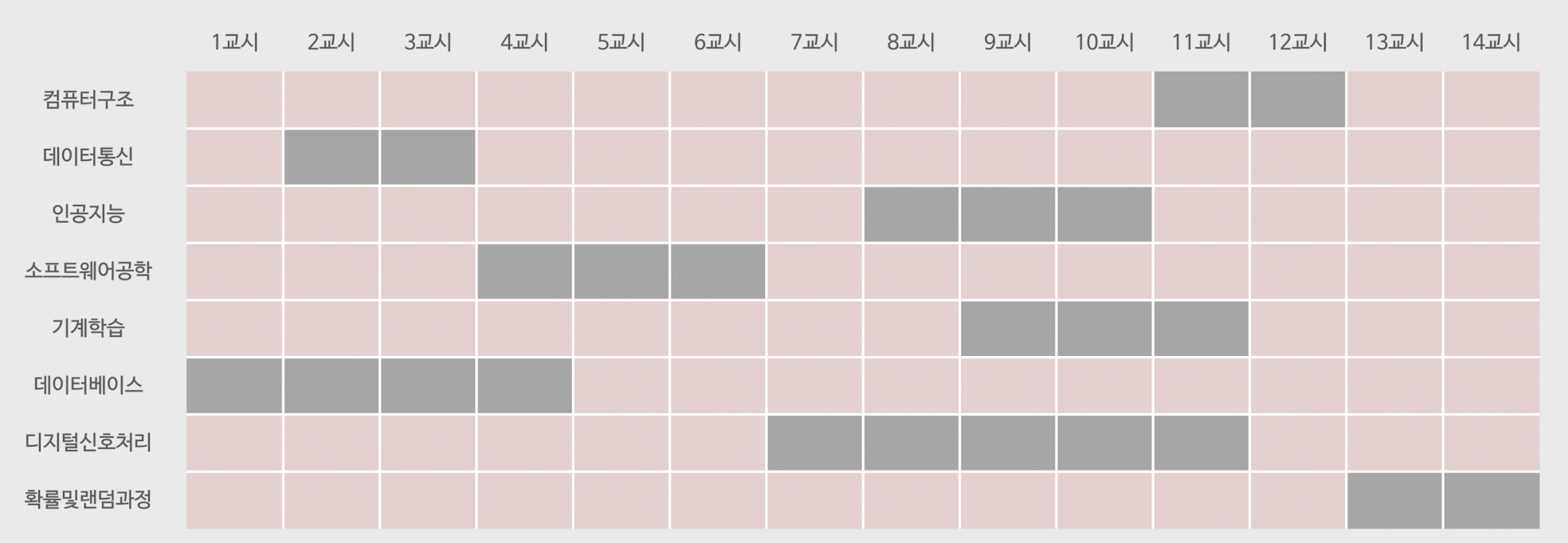
- 시작이 빠른 것부터 넣는다 -> 수업 3개 😡
- 종료가 빠른 것부터 넣는다 -> 수업 5개 😁
