
1. 순차 탐색과 이진 탐색
⚠️ex. 891, 358, 250, 915, 324, 797, 738, 151, 230, 198
세 자리 자연수 ABC는 위 수열 내에 존재할까? 만일 존재한다면 어느 위치에서 ABC를 찾을 수 있을까?
✅Sequential Search Algorithm(순차 탐색)
- 첫 번째 원소부터 순차적으로 확인하며 찾고자 하는 원소가 어느 위치에 존재하는지 파악
- (자연수 250을 탐색하는 경우) 891x -> 358x -> 250 o -> 탐색종료
- (자연수 231을 탐색하는 경우) 891x -> 358x -> ... -> 탐색종료
정확하지만 빠르지 않은 방법이다.
numbers=[30, 94, 15, 23, 19, 22, 98, 44, 52, 56]
target = 23
for i in range(0, len(numbers)) :
if (taget == numbers[i]) :
pring(i)
break
else:
print('NOT FOUND')✅Binary Search Algorithm(이진 탐색)
정렬이 되어있다는 전제
1. 정렬된 목록에서 중앙값을 기준으로 목록을 둘로 쪼개는 과정을 반복
2. 목록에 존재하는 원소의 수가 N일 때, 탐색을 위한 최대 쪼개기 횟수는 ㅣog2n을 따름
ex. N = 1024, log2 1024 = 10
<!--정렬된 수-->
numbers = [15, 19, 22, 23, 30, 44, 52, 56, 94, 98]
target = 23
left = 0
rigth = len(numbers) - 1
while (True) :
mid = (left + rigth) // 2
if (taget == numbers[mid]) :
print(mid)
break
elif (taget < numbers[mid]) :
rigth = mid - 1
else :
left = mid + 1
if (left > rigth) :
print('Not Found')
break✅시간복잡도 차원에서 살펴보기
😡최악 시간복잡도
1️⃣순차 탐색: 찾고자 하는 값이 주어진 수열에 없음 -> 빅세타(n)
-> 10개의 원소라면 10번 비교가 최악. N개의 원소라면 N번 비교가 최악
2️⃣이진 탐색: 최대 수열 쪼개기 횟수까지 도달 -> 빅세타(logn)
😁최선 시간복잡도
1️⃣순차 탐색: 첫번째 원소가 찾고자 하는 값과 일치: 빅세타(1)
2️⃣이진 탐색: 수열의 중앙값이 찾고자 하는 값과 일치: 빅세타(1)
2. 정렬을 위한 기본 알고리즘
1. 🫧Bubble Sort
✅이웃끼리 비교해 뒤집을지 결정
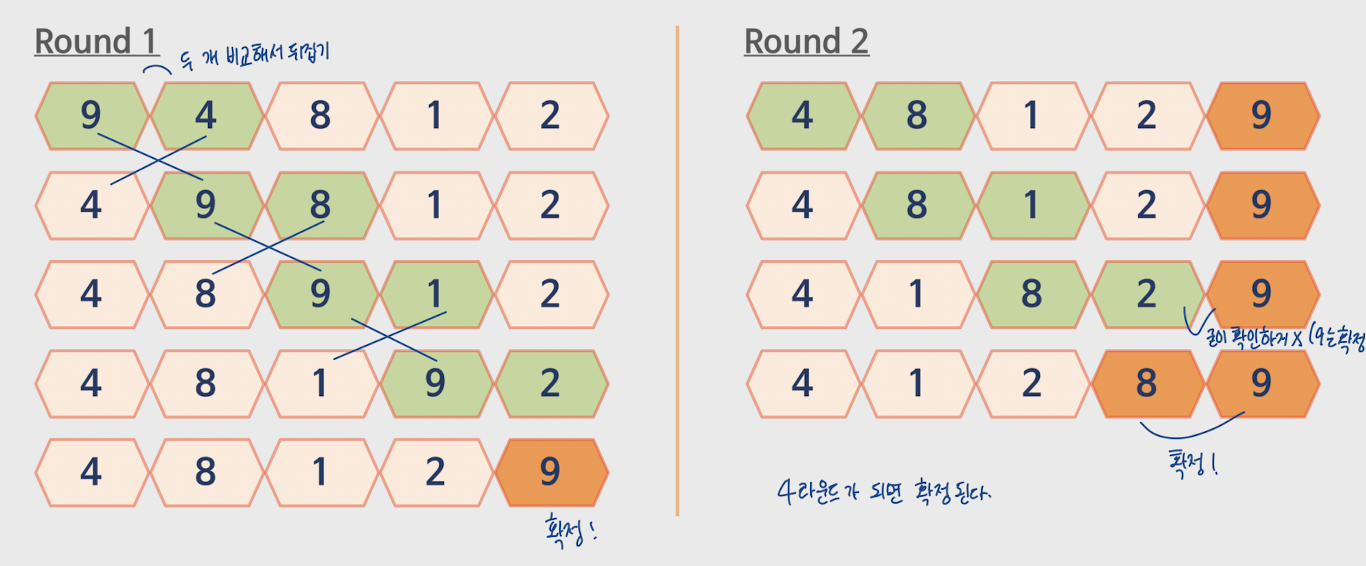
round1 : 5번 비교해서 맨 오른쪽 값 확정
round2 : 4번 진행해서 오른쪽에서 -1 값 확정
=> 총 round 4가 되면 모든 수가 확정
⚠️round 4가 되기 전에 이미 정렬이 끝난 경우
-> 그 다음의 round를 진행할 필요가 없다.
❗️이미 정렬이 끝났음을 확인하기 위한 효과적인 방법?
=> 한 번이라도 뒤집었다면 +1하는 함수를 만들기
만약 한 번도 뒤집지 않았다면 정렬이 끝났다는 것!
✅시간복잡도 차원에서 살펴보기
😡최악 시간복잡도
round1에서의 비교 횟수 : n -1
round2에서의 비교 횟수 : n -2
...
(n-1) + (n-2) + ... + 1 = n(n-2) /2
➡️빅세타(n**2)
😁최선 시간복잡도
이미 정렬된 수열을 버블 정렬 시도할 경우, Round1에서 (n-1)회 비교 후 프로그램 종료
➡️빅세타(n)
Python 프로그래밍 작성하기
numbers = [8, 3, 4, 2, 6, 1, 9, 5, 7]
i = 1
length = len(numbers)
while (i < length) :
swap_check = False
j = 0
while(j < len(numbers) - i)
if (numbers[j) > numbers[j + 1]) :
numbers[j], numbers[j +1] = numbers[j +1], numbers[j]
swap_check = True
j = j + 1
if (swap_check === False) :
break
i = i + 1
print(numbers)2. 🥗Insertion Sort
✅원소 하나를 골라 적절하게 삽입
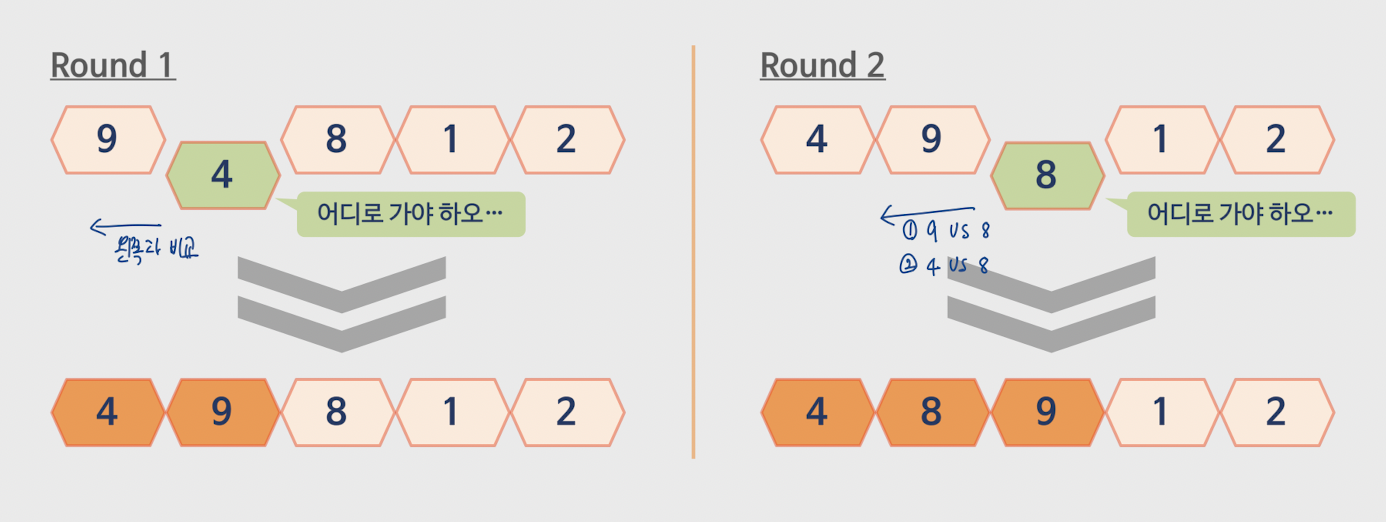
왼쪽과 비교
round4에 정렬 보장
✅시간복잡도 차원에서 살펴보기
😡최악 시간복잡도
Round1에서 1회 비교, Round2에서 2회 비교, Round3에서 3회 비교 ...
1 + 2 + 3 + ... + (n-1) / 2
➡️빅세타(n**2)
😁최선 시간복잡도
이미 정렬된 수열을 삽입 정렬 시도할 경우, 매 Round마다 1회의 비교만을 수행
삽입 정렬의 Round 수는 (n-1)로 고정
➡️빅세타(n)
Python 프로그래밍 작성하기
numbers = [8, 3, 4, 2, 6, 1, 9, 5, 7]
i = 1
length = len(numbers)
while (i < length) :
j = i - 1
key_value = numbers[i]
while (j >= 0) :
if (key_value < numbers[j]) :
numbers[j + 1] = numbers[j]
else:
break
j = j - 1 <!--while문이 j >= 0이기 때문에 반복문을 멈추게 하려고-->
numbers[j + 1] = key_value <!--이 코드가 왜 있는지 모르겠음-->
i = i + 13. ✔️Selection Sort
✅최소 원소를 선택해 맨 앞과 맞바꾼다.
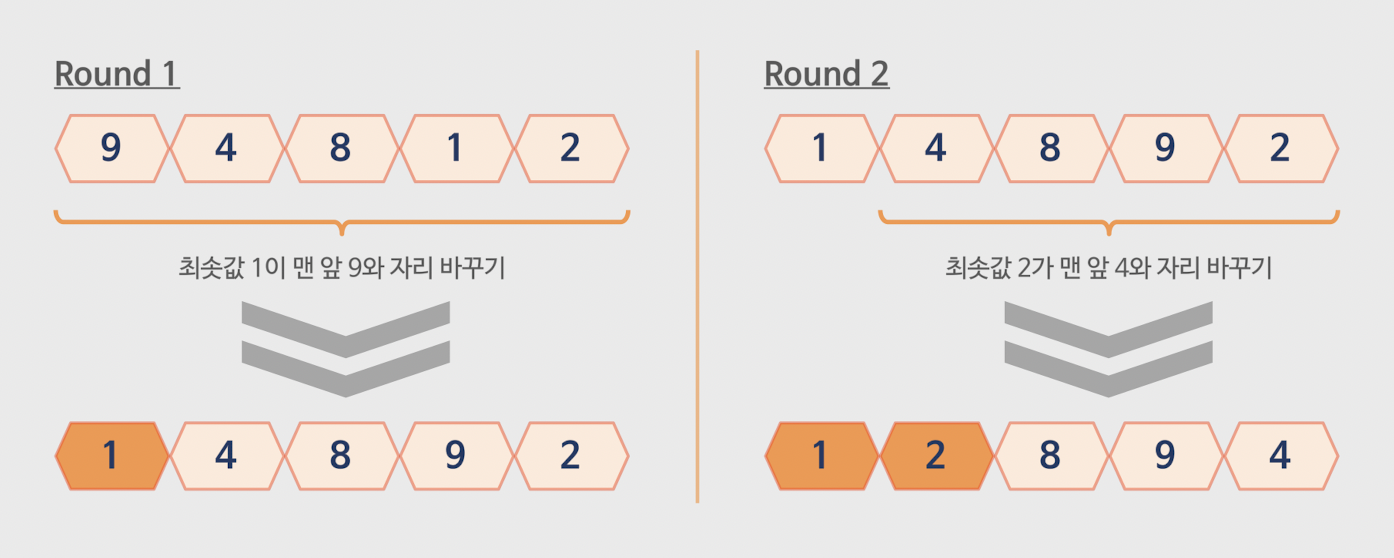
✅시간복잡도 차원에서 살펴보기
😡최악 시간복잡도
Round1에서 최솟값 찾는 데 n회 연산, Round2에서 최솟값 찾는 데 (n - 1)회 연산...
n + (n-1) + ... + 1 = n(n+1) / 2
➡️빅세타(n**2)
😁최선 시간복잡도
수열이 어느 정도 정렬되어 있든 상관없이, 최솟값을 찾는 연산 수를 줄일 방법은 없음
➡️빅세타(n**2)
Python 프로그래밍 작성하기
numbers = [8, 3, 4, 2, 6, 1, 9, 5, 7]
i = 0
length = len(numbers)
while(i < length - 1) :
target_numbers = numbers [i:length]
target_minimum = min(target_numbers)
target_index = numbers.index(target_minimum)
numbers[i], numbers[target_index] = numbers[target_index], numbers[i]
i = i + 1*index 함수는 배열에서 값의 위치를 찾아주는 함수
3. 보다 빠른 정렬을 위한 방법
1. 🌲이진트리
1. Root Node와 Leaf Node
- 부모 Node를 갖지 않는 Node는 Root Node(맨 꼭대기)
- 자식 Node를 갖지 않는 Node는 Leaf Node(맨 아래쪽)
Leaf Node가 아닌 모든 Node를 내부 Node라고 함
2. 이진 Tree
모든 Node가 최대 2개의 자식 Node를 갖는 Tree(0개, 1개, 2개)
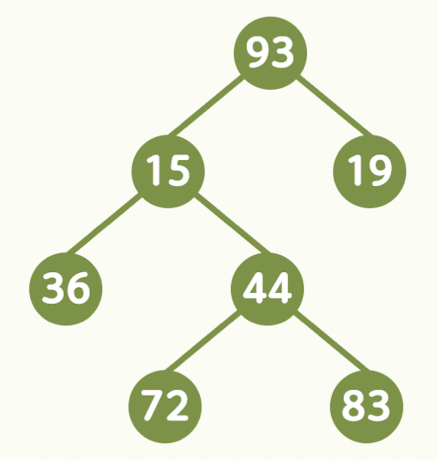
3. Perfect Binary Tree
- 모든 곳이 빈틈없이 채워진 이진 Tree
- 모든 내부 Node의 자식이 둘이며, 모든 Leaf Node의 깊이가 동일한 이진 Tree
4. Complete Binary Tree
- Tree의 최하단을 제외한 영역은 Perfect Binary Tree를 이루며, 최하단의 모든 Node는 좌칙에 몰려 있는 경우 완전 이진 Tree라고 한다.
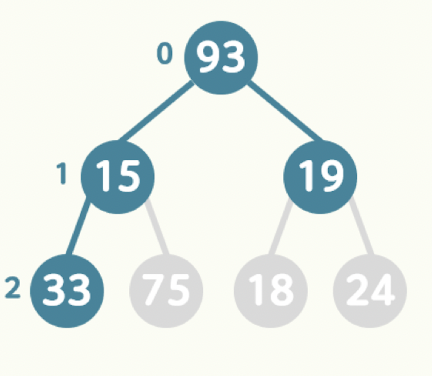
2. Heap
-
이진 Max Heap (다음 조건을 만족하는 이진 Tree)
1) 주어진 Tree는 완전 이진 Tree
2) 모든 부모 Node는 자신의 자식 Node보다 크거나 같은 값을 가짐
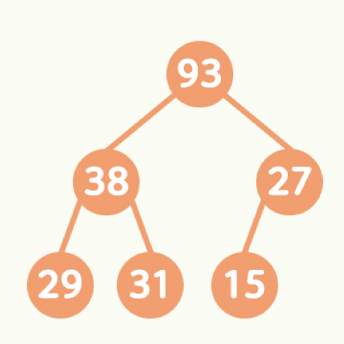
-
이진 Min Heap
위와 반대로 모든 부모 Node가 자식 Node보다 작거나 같은 값을 갖는 경우
1. Heap에서 새 원소 삽입하기.
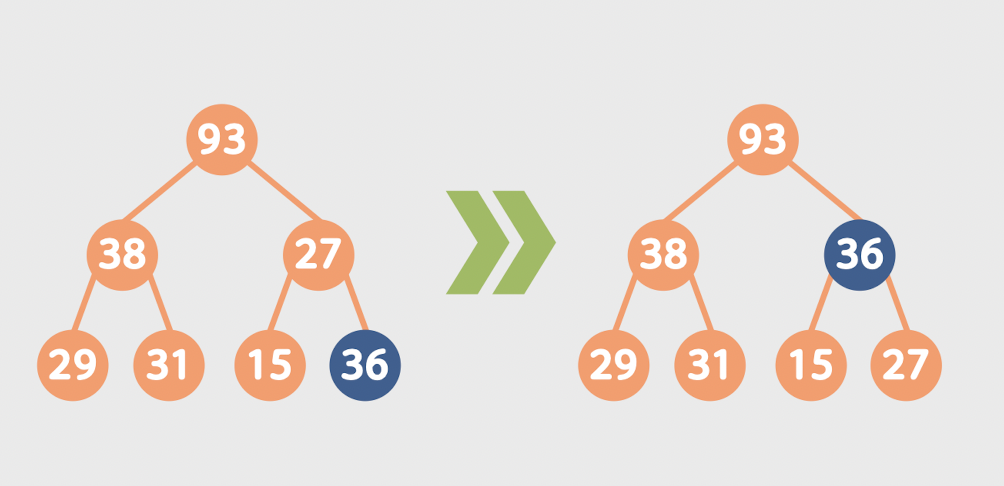
1. 완전 이진 트리의 정렬이 깨지지 않게 원소를 1차 삽입
2. 부모와 비교를 거듭해 힙의 성질 유지
1. Heap에서 삭제
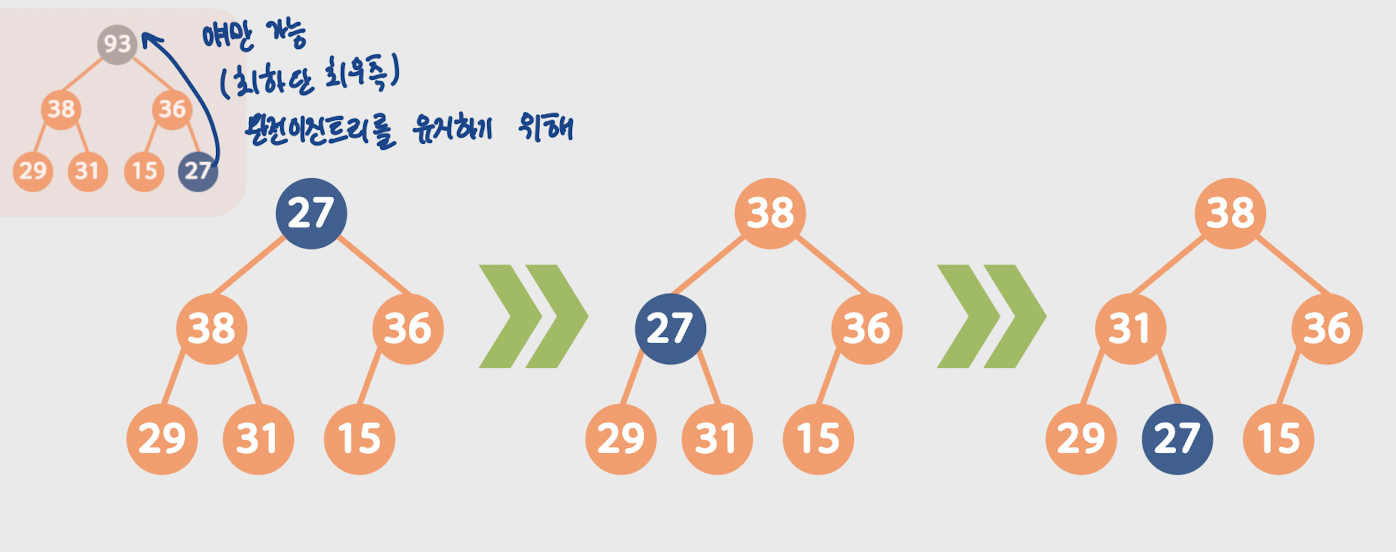
1. 힙에서의 삭제는 Root 삭제만 가능하다
2. root 삭제 후 최하단 최우측 이진트리를 root 자리에 넣는다.
3. 부모와 비교를 거듭해 힙의 성질을 유지한다.
3. Heap Sort
✅Max Heap 자료구조를 이용하여 다음의 절차를 걸쳐 정렬을 수행
1. 비어 있는 Heap에 주어진 원소를 순서대로 삽입하되 도중에 Heap의 성질이 유지되게끔 함
2. Heap 최상단에는 최댓값이 존재함이 보장되므로, 새로운 수열의 맨 끝에 Heap 최상단 값을 위치시킴
3. Heap 최상단 원소를 제거한 후, Heap의 성질을 유지시키며 동일한 과정을 반복
✅시간복잡도 차원에서 살펴보기
😡최악 시간복잡도
➡️빅세타(nlogn)
4. 특수한 상황에서의 정렬
1. Radix Sort
✅원소를 비교하는 것이 아니라 점검(이전까지는 다 비교)

- 왼쪽 위부터 순서대로 원소 확인
- round1 : 일의 자리 값에 따라 원소 할당
- round2 : 십의 자리 값에 따라 원소 할당
- round3 : 백의 자리 값에 따라 원소 할당
Python 프로그래밍 작성하기
numbers = [800, 32, 4, 122, 766, 12, 98, 53, 772, 8]
M = 3 <!--최대 자릿수-->
def digit_func(n, d) :
if n >= (10 ** (d-1)):
return int(str(n)[-d])
else:
return 0
for i in range(1, M + 1) :
bucket = list()
for j in range(0, 10) :
bucket.append(list())
for number in numbers :
bucket[digit_func(number, i)].append(number)
numbers = list()
for j in range(0, 10) :
for number in bucket[j] :
numbers.append(number)*파이썬 list()함수는 리스트로 변환해주는 함수이다.
✅시간복잡도 차원에서 살펴보기
😡최악 시간복잡도
Round 수: 3
한 번 씩 읊기 N 번
=> 3N
➡️빅세타(n)
