📢 RAG 를 활용하여 챗봇 만들기
RAG 개념
- Retrieval - Argumented Generation
- 기존의 LLM 을 확장하여 새로 주어진 콘텐츠나 질문에 대해 더욱 정확하고 확실한 정보를 제공하는 방법
- 즉, 모델이 학습하지 않은 외부 데이터에 대해 환각(Hallucination) 발생을 막기 위함
- 외부 데이터를 실시간으로 검색(Retrieval) 하고 활용(Argumented)하여 답변을 생성(Generation)하는 기술 (학습 X, 검색 O)
기본 구조
- 검색 단계(Retrieval): 사용자의 질문이나 컨텍스트를 입력받아 관련된 외부 데이터를 검색하는 단계
- 증강 단계(Argumented): 검색된 데이터를 토큰화, 인코딩, 임베딩 후 VectorDB에 저장하여 검색기를 붙이는 단계
- 생성 단계(Generation): VectorDB에 저장된 데이터와 LLM을 사용하여 사용자의 질문에 답하는 단계
장점
- 풍부한 정보 제공: 검색한 답으로 보다 구체적이고 풍부한 정보 제공
- 실시간 정보 반영: 최신 데이터를 검색하여 답변하므로 모델이 실시간으로 변화하는 정보에 대응 가능
- 환각 방지: 외부 데이터의 검색을 통해 답변을 생성하므로써 환각 현상의 발생을 줄임
프로세스
- 사전 준비 단계
- 문서 불러오기
- 텍스트로 분할(chunking)
- 임베딩
- VectorDB 저장
- 실행
- 검색기(Retreival) 설정
- Prompt 구성
- LLM 생성
- 체인 생성 및 실행
예시
실습1) PDF 를 학습한 챗봇 만들기
-
데이터 로드
- RAG 에 사용할 데이터를 불러오는 단계
# 1. 데이터 로드 from langchain_community.document_loaders import PyPDFLoader loader = PyPDFLoader('./data/미래 필수 역량.pdf') document = loader.load()document[Document(metadata={'producer': 'Skia/PDF m133', 'creator': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36', 'creationdate': '2025-03-05T04:57:45+00:00', 'title': '일문일답 | AI 혁명 속 승자가 되는 법··· AWS 교육 임원이 말하는 미래 필수 역량 | CIO', 'moddate': '2025-03-05T04:57:45+00:00', 'source': './data/미래 필수 역량.pdf', 'total_pages': 6, 'page': 0, 'page_label': '1'}, page_content="홈• 인공지능• 일문일답 | AI 혁명 속 승자가 되는 법··· AWS 교육 임원이 말하는 미래 필수 역량\nBy Lucas Mearian\nSenior Reporter\n일문일답 | AI 혁명 속 승자가 되는 법···AWS 교육 임원이 말하는 미래 필수 역량\n인터뷰\n2025.03.03 • 11분\n교육 산업 생성형 AI IT 직업\nAWS 교육 및 수료증 프로그램에 대한 수요가 급증하고 있다. 일부 과정은 수강생이 전년 대비 9\n배까지 증가했다. 아마존웹서비스(AWS)의 교육·인증 제품 및 서비스 디렉터 제니 트라우트먼은\n이러한 수요 증가는 최근 급변하는 기술 역량에 대한 시장의 요구를 반영한다고 설명한다.\nCREDIT: JENNY TROUTMAN / JENNY TROUTMAN'S LINKEIN"), Document(metadata={'producer': 'Skia/PDF m133', 'creator': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36', 'creationdate': '2025-03-05T04:57:45+00:00', 'title': '일문일답 | AI 혁명 속 승자가 되는 법··· AWS 교육 임원이 말하는 미래 필수 역량 | CIO', 'moddate': '2025-03-05T04:57:45+00:00', 'source': './data/미래 필수 역량.pdf', 'total_pages': 6, 'page': 1, 'page_label': '2'}, page_content='AI와 기술 역량이 빠르게 변화하면서 취업이나 커리어 발전을 위해 필요한 역량도 몇 년 전과 비교해 크게\n달라졌다. 특히 직무 능력 외에 의사소통, 문제 해결, 협업, 리더십 능력 등으로 대표되는 ‘소프트 스킬’의\n중요성이 그 어느 때보다 커지고 있다고 AWS의 교육·수료(training and certification) 제품 및 서비스\n디렉터 제니 트라우트먼이 밝혔다.\n세계경제포럼(WEF)이 올해 1월에 발표한 ‘일자리의 미래 보고서(Future of Jobs Report)’에 따르면 [h ...
-
텍스트 분할 (Text Split)
- 블러온 데이터를 작은 크기 단위인 Chunk 로 분할
- Chunk: 하나의 문서를 일정한 길이로 잘라낸 조각 (보통 문단 단위)
CharacterTextSpliter# CharacterTextSpliter from langchain_text_splitters import CharacterTextSplitter text_spliter = CharacterTextSplitter(separator='\n\n', chunk_size = 500, # 최대 길이 chunk_overlap = 50, # 얼마나 겹쳐서 자를건지 length_function = len) # chunk 크기 기준 (여기서는 길이) # chunk chunks = text_spliter.split_documents(document)- 가장 기본적인 텍스트 분할 도구 → 단순히 지정된 단위로 분할
- 주어진 텍스트를 설정한 단위로 분할
- 주로 문단(
\n\n), 문장(\n) 단위로 분할 - 단점: 의미적 관계를 미포함
- pdf, 뉴스데이터에는 맞지 않아서 잘 사용하지 않음 → 구조가 살아있는 데이터(예, 소설)가 잘 맞음!
chunks
RecursiveCharacterTextSpliter# RecursiveCharacterTextSpliter from langchain_text_splitters import RecursiveCharacterTextSplitter text_spliter2 = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 50, length_function = len) # chunk chunks2 = text_spliter2.split_documents(document)- 문단 → 문장 → 단어 → 문자 순으로 재귀적 분할
- 텍스트의 구조를 고려하여 분할
- 문맥이 잘리는 단점을 보완
- pdf, 뉴스, 보고서에 사용하기 적합
chunks2-
overlap 되어 있지 X → 아마 문장단위로 잘 쪼개져서 overlap 할 필요 없다고 생각해서 그런 듯
==========결과1=========== page_content='홈• 인공지능• 일문일답 | AI 혁명 속 승자가 되는 법··· AWS 교육 임원이 말하는 미래 필수 역량 By Lucas Mearian Senior Reporter 일문일답 | AI 혁명 속 승자가 되는 법···AWS 교육 임원이 말하는 미래 필수 역량 인터뷰 2025.03.03 • 11분 교육 산업 생성형 AI IT 직업 AWS 교육 및 수료증 프로그램에 대한 수요가 급증하고 있다. 일부 과정은 수강생이 전년 대비 9 배까지 증가했다. 아마존웹서비스(AWS)의 교육·인증 제품 및 서비스 디렉터 제니 트라우트먼은 이러한 수요 증가는 최근 급변하는 기술 역량에 대한 시장의 요구를 반영한다고 설명한다. CREDIT: JENNY TROUTMAN / JENNY TROUTMAN'S LINKEIN' metadata={'producer': 'Skia/PDF m133', 'creator': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36', 'creationdate': '2025-03-05T04:57:45+00:00', 'title': '일문일답 | AI 혁명 속 승자가 되는 법··· AWS 교육 임원이 말하는 미래 필수 역량 | CIO', 'moddate': '2025-03-05T04:57:45+00:00', 'source': './data/미래 필수 역량.pdf', 'total_pages': 6, 'page': 0, 'page_label': '1'} ==========결과2=========== page_content='AI와 기술 역량이 빠르게 변화하면서 취업이나 커리어 발전을 위해 필요한 역량도 몇 년 전과 비교해 크게 달라졌다. 특히 직무 능력 외에 의사소통, 문제 해결, 협업, 리더십 능력 등으로 대표되는 ‘소프트 스킬’의 중요성이 그 어느 때보다 커지고 있다고 AWS의 교육·수료(training and certification) 제품 및 서비스 디렉터 제니 트라우트먼이 밝혔다. 세계경제포럼(WEF)이 올해 1월에 발표한 ‘일자리의 미래 보고서(Future of Jobs Report)’에 따르면 [htt ps://www.weforum.org/publications/the-future-of-jobs-report-2025/digest/], 경제 불확실성과 생성형AI의 확산, 기술 발전 속도에 따라 현재 노동자의 보유 역량 중 39%가 2030년까지 효용성을 잃을 것으로 전망됐다. 생성형AI, 네트워크 및 사이버 보안, 기술적 소양과 관련된 역량은 현재 가장 빠르게 성장하고 있으며,' metadata={'producer': 'Skia/PDF m133', 'creator': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36', 'creationdate': '2025-03-05T04:57:45+00:00', 'title': '일문일답 | AI 혁명 속 승자가 되는 법··· AWS 교육 임원이 말하는 미래 필수 역량 | CIO', 'moddate': '2025-03-05T04:57:45+00:00', 'source': './data/미래 필수 역량.pdf', 'total_pages': 6, 'page': 1, 'page_label': '2'}
-
-
임베딩 (Embedding)
- 분할된 텍스트 데이터들을 검색 가능한 형태로 만드는 단계
- 분리된 토큰을 인코딩하고 토큰 간의 연관성을 포함하여 벡터화하는 과정
- 임베딩 결과 벡터 DB 에 저장
- FAISS, Chroma
- Chroma DB: python 언어에 최적화된 vectorDB → LLM, LangChain 프레임워크와 호환성이 좋음
- 역할: 데이터 저장 + 벡터화 → 저장과 검색 동시에 가능
- 데이터를 숫자(벡터) 형태로 저장 → 유사도 기반 검색이 가능
- 이것도 model 이 사용한 임베딩 모델과 동일하게 사용해야 함
from langchain_openai import OpenAIEmbeddings from langchain_community.vectorstores import Chroma # 텍스트 데이터 임베딩 후 DB에 저장 embedding = OpenAIEmbeddings() vectordb = Chroma.from_documents(documents = chunks2, embedding = embedding) -
검색
- 사용자의 질문에 대답하기 위하여 가장 관련 있는 정보(즉, 유사도 높은 chunk 검색)를 찾는 단계
- 사용자의 입력을 바탕으로 쿼리를 생성하고 연관성이 높은 정보를 검색
# 검색기 retriever = vectordb.as_retriever(search_kwargs = {'k': 2}) -
생성
- 검색한 정보를 기반으로 사용자의 질문에 답변을 생성
- LLM 에게 사용자의 입력(질문)과 검색한 결과를 함께 전달하여 모델은 사전학습된 지식과 검색 결과를 결합하여 적절한 답변을 생성
from langchain_core.prompts import ChatPromptTemplate from langchain_openai import ChatOpenAI from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough # 프롬프트 템플릿 생성 chat_rompt = ChatPromptTemplate.from_messages([ ('system','{context}'), # context 에 retrieval 내용 넣어줄거임! ('human','{question}') ]) # model 생성 llm_model = ChatOpenAI(model='gpt-4o-mini', temperature=0) # chain 연결 output_parser = StrOutputParser() rag_chain = ( {'question': RunnablePassthrough(), 'context': retriever} | chat_prompt | llm_model | output_parser ) # chain 구동 rag_chain.invoke('위 파일은 어떤 내용이야?') q = input("질문 입력하시오: ") res = rag_chain.invoke(q) print(res)- std
위 파일은 AI 혁명과 관련된 내용으로, AWS 교육 임원이 미래에 필요한 필수 역량에 대해 이야기하는 인터뷰 형식의 기사입니다. 주요 내용은 AI를 활용하는 방법과 그 중요성에 대한 설명으로, 개인적인 용도로 AI를 사용해보는 것이 필요하다는 점을 강조하고 있습니다. 예를 들어, 자녀의 학교 문제로 이메일을 작성하거나 연말 편지를 쓸 때 AI를 활용할 수 있다는 사례를 제시하고 있습니다. 이를 통해 AI가 어떤 일을 할 수 있는지 직접 경험해보는 것이 업무와 일상생활에서 AI를 활용하는 데 도움이 될 것이라고 언급하고 있습니다.
-
챗봇 만들기
# 챗봇만들기 while True: q = input('입력: ') if q == 'end': print('종료.') break res = rag_chain.invoke(q) print(f"답변: {res}") print('-------------------------------')
실습 2) 네이버 뉴스 페이지를 검색하여 질문에 답변하는 챗봇
-
import library
- code
from langchain_community.document_loaders import WebBaseLoader import bs4 from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_openai import OpenAIEmbeddings from langchain_community.vectorstores import FAISS, Chroma from langchain_core.prompts import PromptTemplate, ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough from langchain_core.output_parsers import StrOutputParser from langchain_teddynote.messages import stream_response from langchain_openai import ChatOpenAI라이브러리/모듈 기능 설명 bs4웹페이지를 파싱하고 HTML/XML 구조에서 텍스트 데이터를 추출하는 라이브러리 (BeautifulSoup) langchain_community.document_loaders.WebBaseLoader웹사이트에서 텍스트를 로딩하고 LangChain의 문서 객체로 변환 langchain_text_splitters.RecursiveCharacterTextSplitter텍스트를 문단 → 문장 → 단어 등 계층적으로 나누어 청크 단위로 분할 langchain_openai.OpenAIEmbeddingsOpenAI 모델을 사용하여 텍스트를 벡터(임베딩)로 변환 langchain_community.FAISS벡터 데이터베이스 중 하나로, 벡터 간 유사도 기반 검색 수행 langchain_core.prompts.PromptTemplate입력값을 프롬프트 템플릿에 채워 넣어 LLM 호출용 프롬프트 생성 langchain_core.runnables.RunnablePassthrough입력을 변경하지 않고 그대로 다음 단계로 전달하는 연결용 Runnable langchain_core.output_parsers.StrOutputParserLLM의 출력 결과를 문자열로 파싱해 후처리 용도로 사용 langchain_teddynote.messages.stream_response스트리밍 방식으로 LLM 응답을 처리하는 기능 (Teddynote 확장 모듈) langchain_openai.ChatOpenAIOpenAI의 GPT 모델을 LangChain에서 채팅형 LLM으로 사용
- code
-
데이터 로드
- RAG 에 사용할 데이터를 불러오는 단계 (웹페이지로딩)
- 페이지주소, 요소 추출
# 1. 웹페이지 읽어오기 (페이지 주소 공유, 참고하고자 하는 요소 추출) url = 'https://n.news.naver.com/mnews/article/001/0015828345' loader = WebBaseLoader(web_path = [url], bs_kwargs = dict( parse_only = bs4.SoupStrainer( "div", attrs = {'class': ['media_end_head_title', 'newsct_article _article_body', 'media_end_head_info_datestamp']} ) )) # div 태그가 가지는 제목, 본문, 날짜 부분의 클래스 이름 추출 # 문서 저장 docs = loader.load() docs -
텍스트 분할 (Text Split)
- 불러온 데이터를 작은 크기 단위인 (Chunk)로 분할
# 2. 텍스트 분할 text_spliter = RecursiveCharacterTextSplitter(chunk_size=1000) chunks = text_spliter.split_documents(docs) -
임베딩 (Embbeding)
- 분할된 텍스트 데이터들을 검색 가능한 형태로 만드는 단계
# 3. 임베딩 embedding = OpenAIEmbeddings() vectordb = Chroma.from_documents(documents = chunks, embedding = embedding) -
검색
- 사용자의 질문에 대답하기 위하여 가장 관련있는 정보를 찾는 단계 (유사도 검색)
# 4. 검색 retriever = vectordb.as_retriever(search_kwargs = {'k': 2}) -
생성
- 검색한 정보를 기반으로 사용자의 질문에 답변을 생성
# 5. 생성 chat_prompt = PromptTemplate.from_template(''' 당신은 주어진 내용에서 검색하여 사용자 질문에 맞는 대답을 하는 AI 질문-답변 못이야. 주어진 문맥(context)에서 주어진 질문(qeustion)을 답할 때, 문맥(context)에서 찾을 수 없다면 '주어진 정보에서 찾을 수 없습니다.'라고 답해. 한글로 답변해. question: {question} context: {context} ''') llm_model = ChatOpenAI(model='gpt-4o-mini', temperature=0) output_parser = StrOutputParser() rag_chain = ( {'question': RunnablePassthrough(), 'context': retrieval} | chat_prompt | llm_model | output_parser) result = rag_chain.stream('LLM 모델을 사용할 때 주의해야 하는 분야는 뭐야?') stream_response(result) # teddynote 의 stream 기능 활용
실습 3) 이미지 데이터를 입력받는 챗봇 생성
- MultiModal 모델 사용 (이미지, 텍스트)
-
teddynote 가 만든 multimodal 함수 사용
-
프롬프트 입력으로 텍스트만 분석하여 출력하는 것이 아니라 이미지, 오디오 등 데이터를 사용할 수 있는 모델
-
이미지 인식(Vision) 기능이 추가되어 있는 모델
-
LangChain + teddynote Multimodal 함수 함께 사용
-
장점: 쉽게 사용 가능
-
단점: customize 하기 어려움
# 모델 생성 llm_model = ChatOpenAI(model = 'gpt-4o-mini', temperature=0) # MultiModal 객체 생성을 위한 시스템 메시지와 휴먼 메시지 작성 system_message = '당신은 재무분석 전문가입니다. 재무재표를 분석하여 중요한 내용을 정리해 주세요.' human_message = '재무재표를 분석하여 현 기업의 상태를 알려주세요.' # MultiModal 객체 생성 multimodal_llm = MultiModal(llm_model, system_prompt=system_message, user_prompt=human_message) # 이미지 전송 후 출력 res = multimodal_llm.stream('./data/table01.png') stream_response(res) -
std
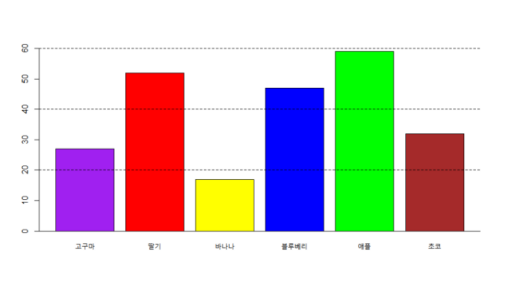
가장 많이 판매된 아이스크림 맛은 "애플"입니다.
-
- OpenAI 에서 제공하는 SDK 호출하여 이용
-
공식적인 방법
-
SDK: Software Development Kit
# import library import openai import base64 # 이미지를 문자로 바꾸기 위한 라이브러리 import matplotlib.pyplot as ply import matplotlib.image as ping # 텍스트 질문과 이미지 파일의 경로를 입력받아 모델에게 질문을 보내고 답을 반환하는 함수 정의 # 텍스트 질문과 이미지 파일의 경로를 입력받아 모델에게 질문을 보내고 답을 반환하는 함수 정의 def multimodal(query, image_path): with open(image_path, 'rb') as img_file: img = img_file.read() # gpt-4o 모델 넣어주기 response = openai.chat.completions.create( model = 'gpt-4o', messages=[ {"role": "user", "content": [{"type": "text", "text": query}, {"type": "image_url", "image_url": {"url": "data:image/png;base64," + base64.b64encode(img).decode('utf-8')}} ]} ] ) return response.choices[0].message.content # 이미지 출력 img_path = './data/chart.png' img = pimg.imread(img_path) plt.imshow(img) plt.axis('off') plt.show() # 그래프 이미지 모델에 넣어 분석 후 출력 query = '가장 많이 판매된 아이스크림 맛의 종류는 무엇인가요?' multimodal(query, img_path) -
std
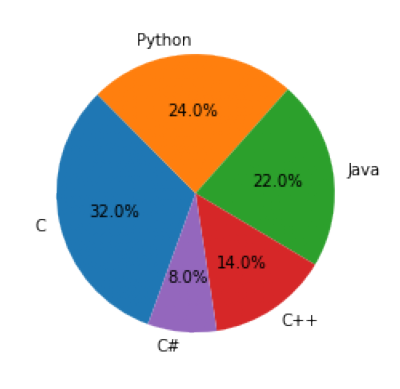
가장 많이 사용하는 프로그래밍 언어는 C로, 32.0%입니다.
-
- 시스템 메시지 추가하기
# 텍스트 질문과 이미지 파일의 경로를 입력받아 모델에게 질문을 보내고 답을 반환하는 함수 정의 def multimodal_sys(query, image_path): with open(image_path, 'rb') as img_file: img = img_file.read() # gpt-4o 모델 넣어주기 response = openai.chat.completions.create( model = 'gpt-4o', messages=[ {"role": "system", "content": "당신은 문자 인식 전문가입니다. 이미지에서 텍스트를 추출해주세요."}, {"role": "user", "content": [{"type": "text", "text": query}, {"type": "image_url", "image_url": {"url": "data:image/png;base64," + base64.b64encode(img).decode('utf-8')}} ]} ] ) return response.choices[0].message.content # 번호판 이미지 넣어서 출력 img_path3 = './data/car_number.png' img3 = pimg.imread(img_path3) plt.imshow(img3) plt.axis('off') plt.show() multimodal_sys('자동차 번호판 글자 읽어오세요.',img_path3)- std

이미지의 자동차 번호판에는 "112고 8128"이라고 적혀 있습니다.
- std
- 도로 표시 읽기
def multimodal_sys2(query, img_path): with open(img_path, 'rb') as img_file: img = img_file.read() response = openai.chat.completions.create( model = 'gpt-4o-mini', messages=[ {"role": "system", "content": '''당신은 대한민국 도로 위 표지 이미지 인식 전문가 입니다. 한국 도로교통법에 기반하여 답하세요. 다양한 경우의 예시를 출력해주세요.'''}, {"role": "user", "content": [{"type": "text", "text": query}, {"type": "image_url", "image_url": {"url": "data:image/png;base64," + base64.b64encode(img).decode('utf-8')}} ]} ] ) return response.choices[0].message.content img_path4 = './data/load_sign3.jpg' img4 = pimg.imread(img_path4) plt.imshow(img4) plt.axis('off') plt.show() multimodal_sys2('도로 표지 이미지의 의미와 예시 출력해주세요. 출력형식 -> 의미: 표지의미 \n 예시: 예시(명사형 어미로 출력)', img_path4)
