📢 경사하강법과 최적화함수(Optimizer)의 종류에 대한 페이지입니다.
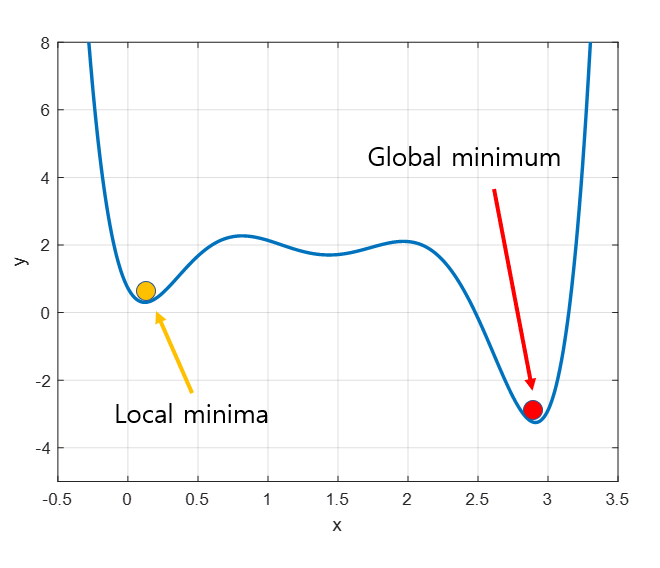
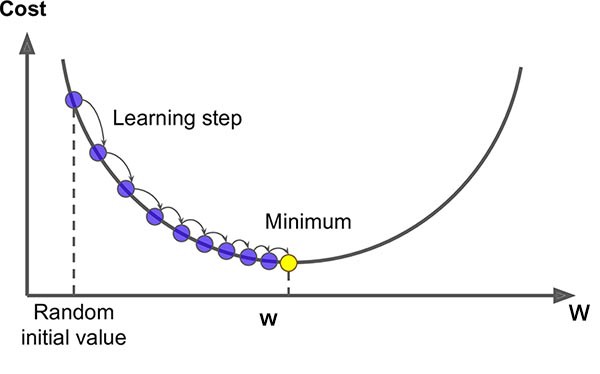
경사하강법 원리
 Reference: https://cdn.analyticsvidhya.com/wp-content/uploads/2024/09/631731_P7z2BKhd0R-9uyn9ThDasA.webp
Reference: https://cdn.analyticsvidhya.com/wp-content/uploads/2024/09/631731_P7z2BKhd0R-9uyn9ThDasA.webp
비용함수(loss function)가 최저가 되는 지점 찾기
= 기울기가 가장 작은 부분 찾기
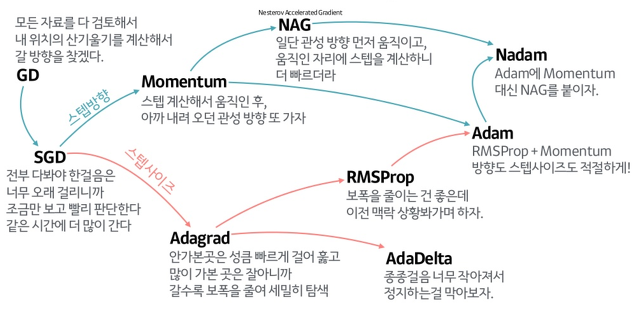
Optimizer 종류
경사하강법(Gradient Descent)
- 전체 데이터를 이용해 업데이트
- 장점: 안정적으로 최적해 찾아갈 수 있음
- 단점: 연산량이 너무 많고 메모리 많이 사용하고, 오래 걸림
확률적 경사하강법(Stochastic Gradient Descent, SGD)
 Reference: https://media.geeksforgeeks.org/wp-content/uploads/20250523171907731347/stochastic.webp
Reference: https://media.geeksforgeeks.org/wp-content/uploads/20250523171907731347/stochastic.webp
- 확률적으로 선택된 일부 데이터를 이용해 업데이트
- 단점
- 배치GD 보다 더 빨리, 더 자주 업데이트 함
- 지역 최저점을 빠져나갈 수 있음
- 탐색 경로가 비효율적 (진폭이 크고 불안정함) (batch 에 있는 데이테에 따라 결과가 달라짐 → 불안정하게 최적해 찾음) Reference: https://angeloyeo.github.io/2020/08/16/gradient_descent.html
Reference: https://angeloyeo.github.io/2020/08/16/gradient_descent.html
모멘텀(Momentum)
Reference: https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS0ZcWE9sW50oUx9s77bbVEtUBELaHMT6LaRA&s
- 경사 하강법에 관성을 적용해 업데이트
- 현재 batch 뿐만 아니라 이전 batch 데이터의 학습 결과도 반영
네스테로프 모멘텀(Nesterov Accelrated Gradient, NAG)
 Reference: https://blog.kakaocdn.net/dna/yB5qn/btrMHJL8INF/AAAAAAAAAAAAAAAAAAAAAAlv22mMtrUAG2DYzao0R0d9pUvVjDxmI1u4tGbEcoi7/img.jpg?credential=yqXZFxpELC7KVnFOS48ylbz2pIh7yKj8&expires=1769871599&allow_ip=&allow_referer=&signature=mZd%2BDmXQh7oODLQjA0XpP0gEONM%3D
Reference: https://blog.kakaocdn.net/dna/yB5qn/btrMHJL8INF/AAAAAAAAAAAAAAAAAAAAAAlv22mMtrUAG2DYzao0R0d9pUvVjDxmI1u4tGbEcoi7/img.jpg?credential=yqXZFxpELC7KVnFOS48ylbz2pIh7yKj8&expires=1769871599&allow_ip=&allow_referer=&signature=mZd%2BDmXQh7oODLQjA0XpP0gEONM%3D
- 개선된 모멘텀 방식
- 모멘텀에서 이전 말고 이후 데이터도 보자!
- w, b 값 업데이트 시 모멘텀 방식을 먼저 더한 다음 계산
- 미리 해당 방향으로 이동한다고 가정하고 기울기를 계산해 본 뒤 실제 업데이트 반영
- 불필요한 이동을 줄일 수 있음
에이다 그래드(Adaptive Gradient, AdaGrad)
 Reference: https://editor.analyticsvidhya.com/uploads/97106gd4.jpeg
Reference: https://editor.analyticsvidhya.com/uploads/97106gd4.jpeg
- 학습률 감소 방법을 적용해 업데이트
- 학습률 크면: 발산
- 학습률 작으면: 최적해 도달 X
- 학습을 진행하면서 학습률을 점차 줄여가는 방법
- 즉, 처음에는 성큼성큼 걷다가(크게 학습하다가) 점점 보폭 줄이기(조금씩 작게 학습)
- 학습을 빠르고 정확하게 할 수 있음
종류
 Reference: https://gilbertlim.github.io/assets/images/posts/dl/optimization.png
Reference: https://gilbertlim.github.io/assets/images/posts/dl/optimization.png
