📢 RNN 으로 네이버 영화 리뷰에 대한 긍부정 감성 분석을 한 페이지입니다.
- SimpleRNN
- LSTM
- GRU
- Word Embedding + LSTM
- Word Embedding + LSTM 2 layer
SimpleRNN 이용
1. 데이터 로드 및 전처리
1.1. 데이터 로드
import pandas as pd
import numpy as np
# 데이터 로딩
train_df = pd.read_csv('./data/ratings_train.txt', delimiter='\t')
test_df = pd.read_csv('./data/ratings_test.txt', delimiter='\t')
train_df.shape, test_df.shape # ((150000, 3), (50000, 3))- data
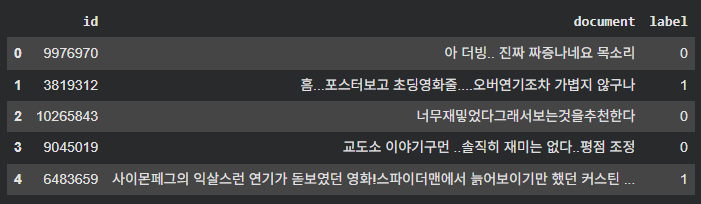
- document: 리뷰
- label: 정답 데이터 (0 부정 / 1 긍정)
1.2. 결측치 제거
# 결측치 확인
train_df.isnull().sum()
test_df.isnull().sum()
# 결측치 제거
# 결측치 데이터 있는 행 제거
train_df.dropna(inplace=True)
test_df.dropna(inplace=True)1.3. 문제와 정답 데이터 분리
# 문제와 정답으로 분리
X_train = train_df['document']
X_test = test_df['document']
y_train = train_df['label']
y_test = test_df['label']- (참고) 딥러닝은 차원 수 상관 없음!
2. 토큰화 & 수치화
TextVectorization: 띄어쓰기 기준으로 잘라줌 → 정교하진 않지만 간단해서 실습 때 사용하겠음
2.1. 객체 생성
from tensorflow.keras.layers import TextVectorization
# 객체 생성
vectorizer = TextVectorization(max_tokens=5000,
output_mode = 'int',
standardize = 'lower_and_strip_punctutation',
output_sequence_length = 10)- 옵션
max_tokens=5000- 단어 사전 5000개로 제한 (빈도 기반으로 상위 5,000개만 cut)
output_mode = 'int'- output 형식
standardize = 'lower_and_strip_punctutation'- 영어 대문자 → 소문자 변환
- 문장부호 제거
output_sequence_length = 10- 수치화를 통해 나온 길이를 10으로 맞춘다는 것
- RNN 에 모든 샘플들의 입력되는 특성 개수가 같아야 함 → 모든 샘플들이 같은 순환 횟수를 가져야 하기 때문 → 그래서 순환 횟수를 통일하는 작업
- 문장이 길면 자르고, 짧으면 0(padding) 으로 채움
2.2. 벡터라이저 적용
- 훈련 데이터를 기반으로 전처리(lower & 문장부호 제거), 토큰화, 단어사전 구축 → 테스트 데이터 적용
- code
# train 기준으로 단어 사전 구축 vectorizer.adapt(X_train) vectorizer.vocabulary_size() # 5000 # 적용 X_train_vec = vectorizer(X_train) X_train_vec.shape # TensorShape([149995, 10]) X_test_vec = vectorizer(X_test) X_test_vec.shape # TensorShape([49997, 10])- 결과 예시
- 리뷰 예시
X_train[0] # 아 더빙.. 진짜 짜증나네요 목소리 - 수치화 예시
X_train_vec[0] # <tf.Tensor: shape=(10,), dtype=int64, numpy=array([ 37, 914, 5, 1, 1077, 0, 0, 0, 0, 0])> - 해석
- 5개의 토큰이 수치화 된 것을 확인 (문장부호 제외)
- max 길이를 10이라고 했으니까 뒤에 5개는 0으로 채움
- 리뷰 예시
- 결과 예시
- OOV(Out-Of-Vocabulary)
- train 을 통한 단어 사전을 구축했을 때, 실제 데이터에서 단어 사전에 없는 토큰은 숫자 1로 수치화 (단어 사전 1번에 저장)
- 단어 사전에 없는 경우 2가지
- test 데이터를 수치화 할 때, train 에 없고, test 에만 있는 경우
- train 데이터에서 단어 사전 개수를 5,000개로 지정하여, 빈도 기준 5,000개 안에 들지 못하는 단어인 경우
- 단어 사전
- 0번: padding 값
- 1번: OOV (단어사전에 없는 값)
- 2번~: 실제 단어
3. SimpleRNN 모델링
- 과정
- 뼈대 생성
- 입력층 설계 (샘플 수를 제외한 나머지 특성의 수)
- 현재 입력데이터의 형태를 RNN 이 원하는 형태로 변경
- (샘플 수, 순환 횟수, 특성 수)
- 여기서 특성 수는 긍정/부정 이진분류이므로 '1'
- RNN 층 설계
- 이진 분류를 위한 출력층 설계
- 학습방법 및 평가방법 설정
- 학습 진행
# shape 변경
X_train_vec = np.reshape(X_train_vec, (-1,10,1))
X_test_vec = np.reshape(X_test_vec, (-1,10,1))
# import library
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Input, SimpleRNN, Dense
from tensorflow.keras.optimizers import Adam
# modeling
rnn_model = Sequential()
rnn_model.add(Input(shape=(10,1)))
rnn_model.add(SimpleRNN(units=64))
rnn_model.add(Dense(units=1, activation='sigmoid'))
# 학습/평가 방법 설정
rnn_model.compile(loss = 'binary_crossentropy',
optimizer = Adam(),
metrics = ['accuracy'])
# 학습
h = rnn_model.fit(X_train_vec, y_train,
validation_split=0.2,
epochs = 20,
batch_size = 128)4. 결과 시각화
# 시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(5,3))
plt.plot(h.history['accuracy'], label='acc')
plt.plot(h.history['val_accuracy'], label='val_acc')
plt.legned()- 그래프 해석
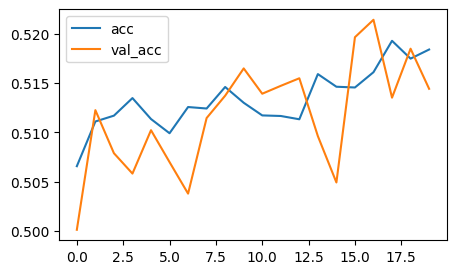
- 정확도가 향상하면서 학습을 진행하고 있으나, 정확도가 높은 편은 아님 → 가장 기본적인 RNN 모델(바닐라 RNN. 아이스크림 기본 맛 = 바닐라 ~)을 사용했기 때문
- 그리고 들쭉날쭉 함..
- 모델 성능 (정확도) 높이는 방법
- 더 좋은 성능의 모델을 사용하는 방법
- 데이터의 질 , 양을 향상 시키는 방법
- 정확도가 향상하면서 학습을 진행하고 있으나, 정확도가 높은 편은 아님 → 가장 기본적인 RNN 모델(바닐라 RNN. 아이스크림 기본 맛 = 바닐라 ~)을 사용했기 때문
LSTM 이용
- 기존 SimpleRNN 의 기억 소실 문제를 보완한 모델
from tensorflow.keras.layers import LSTM, GRU
lstm_model = Sequential()
lstm_model.add(Input(shape=(10,1)))
lstm_model.add(LSTM(units=64)) # <- 이 부분에 SimpleRNN 대신 LSTM 이 들어감 !!!
lstm_model.add(Dense(units=1, activation='sigmoid'))
lstm_model.compile(loss = 'binary_crossentropy',
optimizer = Adam(),
metrics = ['accuracy'])
h2 = lstm_model.fit(X_train_vec, y_train,
validation_split=0.2,
epochs = 20,
batch_size = 128)
# 학습시간 5분- 결과
```python # 시각화 import matplotlib.pyplot as plt plt.figure(figsize=(5,3)) plt.plot(h2.history['accuracy'], label='acc') plt.plot(h2.history['val_accuracy'], label='val_acc') plt.legend() ```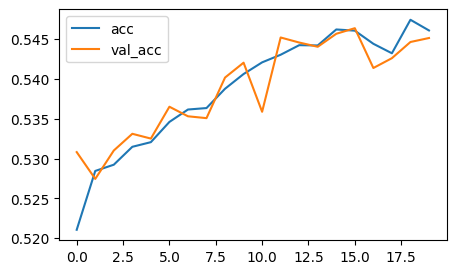
- 결과 해석
- SimpleRNN 보다 accuracy 값이 안정적으로 증가하나, 여전히 정확도 낮음
- 학습 횟수 늘리면 성능 향상될 것 같음
GRU 이용
- LSTM 연산량 많아서 GRU 이용
from tensorflow.keras.layers import LSTM, GRU
gru_model = Sequential()
gru_model.add(Input(shape=(10,1)))
gru_model.add(GRU(units=64))
gru_model.add(Dense(units=1, activation='sigmoid'))
gru_model.compile(loss = 'binary_crossentropy',
optimizer = Adam(),
metrics = ['accuracy'])
h3 = gru_model.fit(X_train_vec, y_train,
validation_split=0.2,
epochs = 20,
batch_size = 128)
# 학습시간 6분-
결과
# 시각화 import matplotlib.pyplot as plt plt.figure(figsize=(5,3)) plt.plot(h3.history['accuracy'], label='acc') plt.plot(h3.history['val_accuracy'], label='val_acc') plt.legend()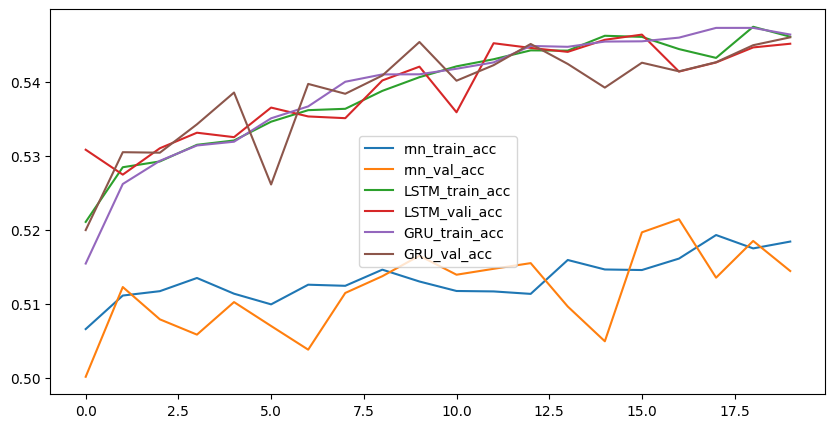
- 결과 해석
- LSTM 이랑 별 차이 없음. 시간도 차이 없음.
- 결과 해석
결과 비교 (SimpleRNN v.s. LSTM v.s. GRU)
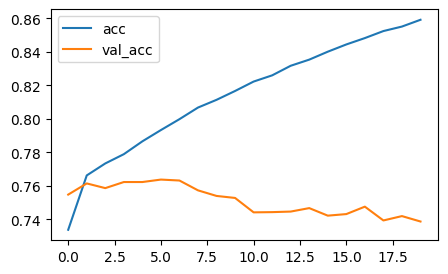
- 결과 해석
- SimpleRNN 보다 LSTM, GRU 가 성능 더 좋아지긴 함
- 그래도 아직 성능이 좋지는 않음
- 학습 횟수 늘리면 성능 좋을 것 같지만 .. 시간이 오래 걸림!
- 모델 성능 높이기 위해 성능 더 좋은 모델도 사용해봄. 데이터양은 늘릴 수는 없음. → 그럼 이제 한 번 데이터의 질 높여보자! → 수치화 방법을 단순히 BOW 가 아닌 워드 임베딩으로 의미 유사성을 고려해서 벡터화 하자!
Word Embedding 이용
Word Embedding 개념
- 자연어 처리에서 사용되는 단어를 수치화하는 방법 중 하나
- 의미적 유사성을 반영하여 수치화 하는 방법
- 유사한 단어들은 유사한 벡터를 가지도록 수치화 = 벡터화
코드
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.optimizers import Adam
# 차원 수 조정
X_train_vec = X_train_vec.squeeze(-1)
X_train_vec.shape # (149995, 10)
# 모델 설계
embedding_model = Sequential()
embedding_model.add(Embedding(5000,50))
embedding_model.add(LSTM(units=64))
embedding_model.add(Dense(units=1, activation='sigmoid'))
embedding_model.compile(loss = 'binary_crossentropy',
optimizer = Adam(),
metrics = ['accuracy'])
embedding_model.fit(X_train_vec, y_train, validation_split = 0.2, batch_size=128, epochs=20)- RNN(LSTM) 사용할 경우, LSTM 전에 Embedding layer 추가하면 됨
embedding_model.add(Embedding(5000,50))(단어 사전 크기, 한 단어를 표현 할 벡터 크기)지정
- Embedding layer 넣어서 Input layer 는 따로 설정하지 않아도 됨!
- Input Data 로는 리뷰 원문을 넣는게 아니라, 토큰화 후 단어사전까지 만들어서 Count 된 것을 넣어준다
- Embedding 을 통해 나온 한 단어에 대한 차원 수를 특성 수로 사용할 것이므로, 특성 수에 대해서는 지정하지 않고
(샘플 수, 순환 횟수)이렇게 넣어줘야 함! - 즉, RNN 모델에 넣는 대로
(샘플 수, 순환 횟수, 특성 수)이렇게 넣으면 오류 발생!
- Embedding 을 통해 나온 한 단어에 대한 차원 수를 특성 수로 사용할 것이므로, 특성 수에 대해서는 지정하지 않고
결과
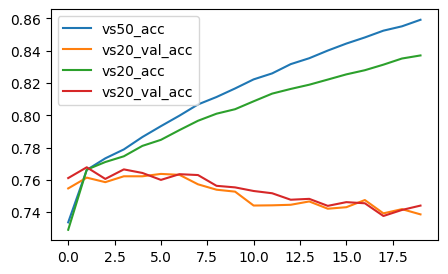
-
기존 LSTM 모델 보다 성능은 좋아짐!
-
그치만 과적합이 되었군여 …. validation accuracy 낮음 ㅠㅠ
-
벡터 크기 너무 크게 해서 과적합 된 것일 수 있으므로, vector size 를 50 에서 20 으로 줄여서 재학습
-
결과
- 문제
- 벡터 사이즈 50 보다는 과적합이 줄어들긴 했으나, 여전히 과적합 ㅠㅠ
- 여기서 더 사이즈 줄이면 너무 학습이 잘 안되는 과소적합이 될 수 있음
- 해결 방법
- Dropout 사용해봐도 좋음!
- 그럼 LSTM 층 여러개 쌓기 보자!
- 문제
-
RNN 여러 층 쌓기
개념
- RNN 은 many to one 이 가장 기본 구조
리뷰 (단어 N개)→긍/부(출력 값 1개)- 1번째 LSTM 을 나온 값으로 2번째 LSTM 에 넣어주면 차원 오류 발생함!
- 따라서, 중간 퍼셉트론(노드)마다 출력되도록 옵션 추가해야함!
return_sequences = True
<정리>
- RNN 계열의 레이어는 기본적으로
다수 입력 → 단일 출력구조 - RNN 계열의 레이어를 여러개 쌓으려면 이전 레이어를 다수 입력 할 수 있는 형태로 변경해야 함
return_sequences = True(RNN 계열 모델의 출력 형태를 결정) → 모든 시점의 출력을 진행
code
embedding_model3 = Sequential()
embedding_model3.add(Embedding(5000,20))
embedding_model3.add(LSTM(units=64, return_sequences=True)) # <- 이 부분 추가!!
embedding_model3.add(LSTM(units=64))
embedding_model3.add(Dense(units=1, activation='sigmoid'))
embedding_model3.compile(loss = 'binary_crossentropy',
optimizer = Adam(),
metrics = ['accuracy'])
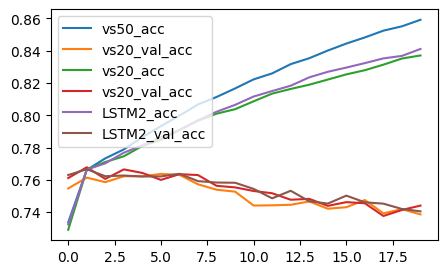
embedding_model3.fit(X_train_vec, y_train, validation_split = 0.2, batch_size=128, epochs=20)결과
-
accuracy
- LSTM 2층으로 쌓아도 비슷해욧 ..
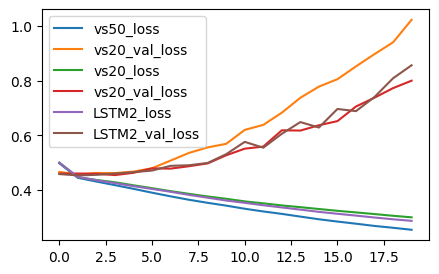
-
loss
- loss 엄청 커짐 !!! 이거 이거 안되겠네 …
-
결론: 성능 개선하는거 되게 어렵네 … → 전이학습 이용하자!
