데이터 스케일링에 대한 페이지입니다.
개념
데이터 성능을 올리기 위해서는
- 하이퍼 파라미터 조절 (but 드라마틱한 변화는 없음)
- 학습 데이터 추가
- 데이터 전처리!!! ← 중요
- 그 중 하나가 스케일링!
Scaling
- 데이터 특성(feature)들의 값 범위를 일정한 수준으로 맞춰주는 작업
- 즉, 분산 정도를 맞춰주는 것!
- 특성마다 다른 범위를 가지면서 편차가 큰 데이터의 경우 모델들이 잘못된 결과를 도출할 가능성 있음
- 거리/수치 기반 모델만 해당!
- KNN, 선형 회귀, 로지스틱 회귀 등
- Decision Tree 는 해당 X
- 거리/수치 기반 모델만 해당!
- 예) A 사람: 키 176cm, 시력 2.0 / B 사람: 키 180cm, 시력 0.9
- 두 사람의 키 차이는 4cm, 시력 차이는 1.1 차이임
- 절댓값만 보면 키 차이가 더 커보이지만 사실 시력의 1.1이 훨씬 큰 차이임
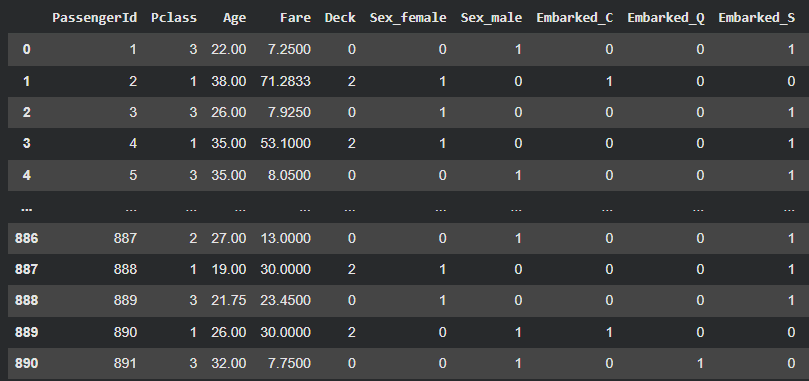
- 예) titanic 데이터에서 Pclass 가 생존에 많은 영향을 미치는데, Age와 Fare 의 값 범위가 커서 영향력이 가려질 수 있음! ㅠㅠ
Standard Scaler
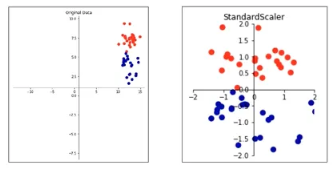
- 가장 많이 사용하는 스케일링 방법
- 변수의 평균, 분산을 이용해 정규 분포 형태로 변환 (평균 0, 분산 1)
- (참고) 분산: 데이터가 퍼져있는 정도로, 클수록 들죽날죽하고 불안정함
- 이상치가 있다면 평균과 분산에 영향을 미쳐 변환된 데이터의 분포는 매우 달라짐
사용법
from sklearn.preprocessing import StandardScaler
# 객체 생성
std_scaler = StandardScaler()
# scaler 학습 (우리의 데이터에 맞게 학습)
std_scaler.fit(X_train)
# scaler 를 통한 변환
X_train = std_scaler.transform(X_train)
X_test = std_scaler.transform(X_test)
##
# fit + transform 한 번에 하는 방법
X_train = std_scaler.fit_transform(X_train)
X_test = std_scaler.transform(X_test) # train 데이터로 학습한 스케일러로 변환하기!!- 방법 1
- train 데이터
fit학습 - train 데이터
transform변환 - test 데이터
transform변환
- train 데이터
- 방법 2
- train 데이터
fit+transform학습과 변환 동시에 - test 데이터
transform변환
- train 데이터
- 여기서 중요 포인트!
- test 데이터는 train 데이터로 학습한 스케일러로 변환하기!!
