선형회귀에 대한 페이지입니다.
선형 모델 (Linear Model)
개념
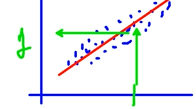
- 회귀 분석은 예측값이 평균과 같이 일정한 값으로 돌아가려는 경향을 이용한 통계학 기법 이용
- 즉, 데이터를 가장 잘 나타내는(즉, 대표하는) 직선을 찾는것!
- 그리고 그 직선에 값을 대입해서 y 값을 찾는 것
- 입력 특성에 대한 “선형 함수”를 만들어 “예측”을 수행
- 분류 / 회귀 모두 가능
- 다양한 선형 모델이 존재
- 딥러닝의 근간
기본 형태
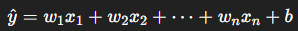
- 각 피쳐가 예측값(
y)에 영향을 많이 미칠수록 가중치(w) 값이 커짐
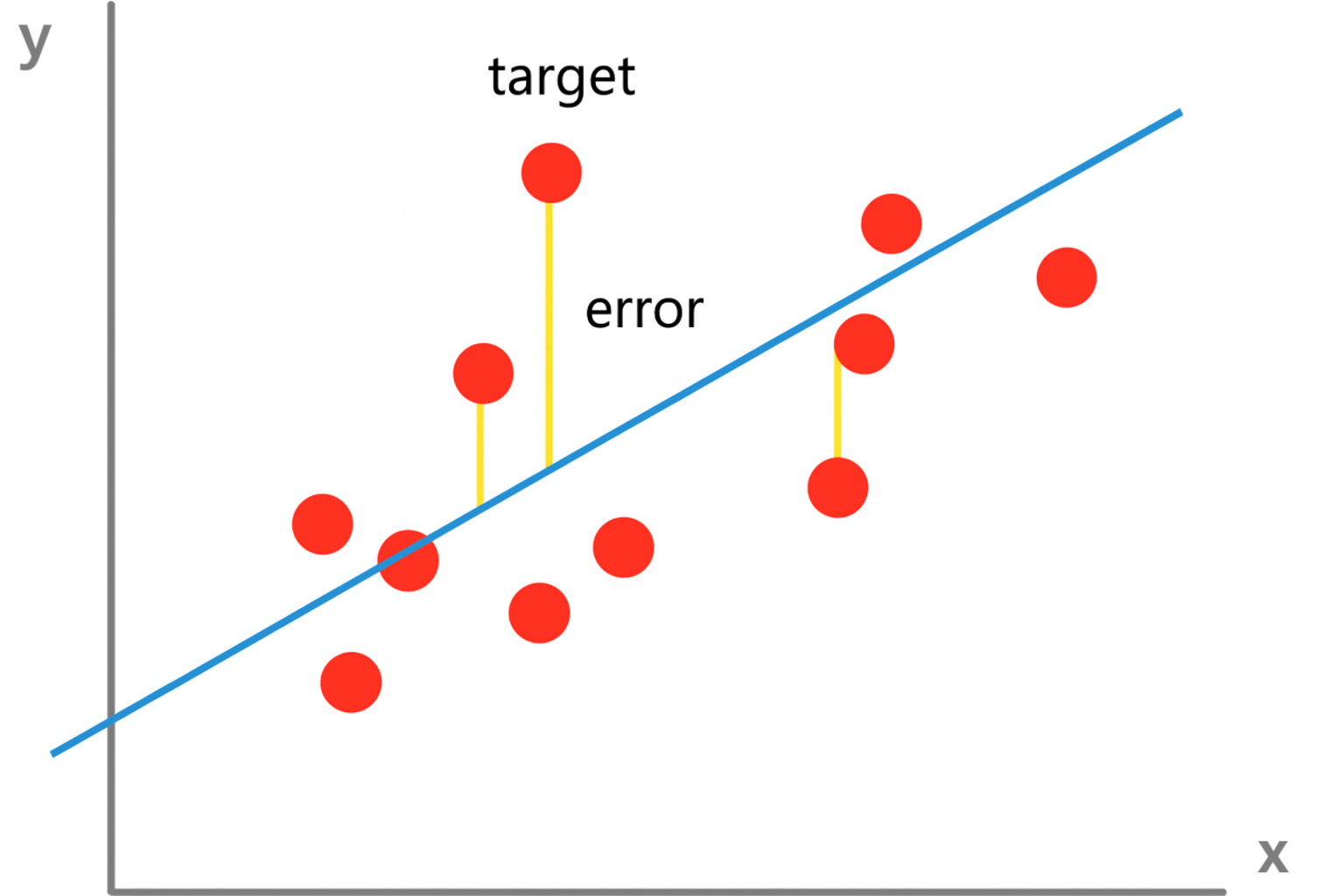
MSE
-
오차 = 실제값 - 예측값
-
선형모델은 오차를 줄여나가는 방향으로 학습한다!
→ 그 오차로 ‘MSE’ 를 사용한다~
-
MSE = Mean Squared Error
- 평균제곱 오차
- 선형 모델은 MSE 가 최소인 직선을 찾는다!
- (참고) 직선을 찾는다 = w 와 b 를 찾는 것 !
비용 함수(cost function) = 손실 함수(loss function)
- cost function 을 줄이는 방향으로 직선 그림
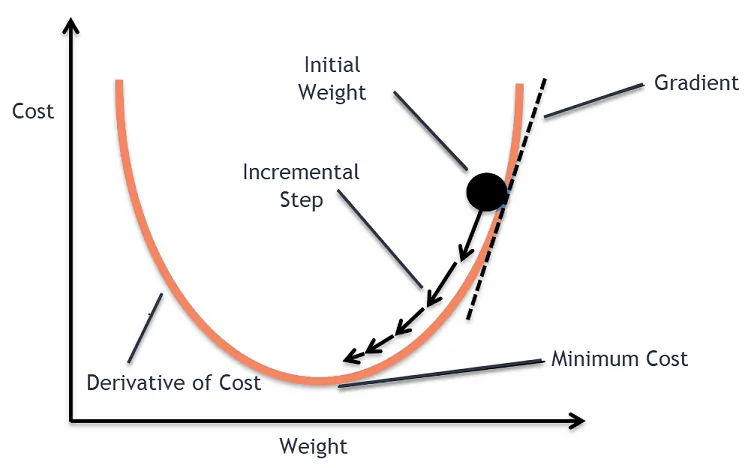
경사하강법(Gradient Descent Algorithm)
-
MSE 가 최소가 되는 W와 b를 찾는 방법 중 하나
 Reference: https://www.analyticsvidhya.com/blog/2020/10/how-does-the-gradient-descent-algorithm-work-in-machine-learning/
Reference: https://www.analyticsvidhya.com/blog/2020/10/how-does-the-gradient-descent-algorithm-work-in-machine-learning/
-
X축: 가중치
-
Y축: J(w) = cost function = 오차
-
비용 함수의 기울기가 낮은 쪽으로 이동하여 값을 최적화 시키는 방법
학습률 (Learning rate)
- 경사하강법의 hyper parameter
- 보폭! = 얼마만큼의 크기로 가중치 업데이트 할거냐 ~
- 보폭이 너무 크면 왔다갔다 함 ㅠ
- 보폭이 너무 작으면 시간이 오래 걸린다 ㅠ or 정해진 학습 시간 내에 최적해에 도달하지 못할 수 있음 ㅠ
코드
모델링
# 공부시간에 따른 성적 변화
# 1. 데이터
import pandas as pd
score = pd.DataFrame({'시간':[2,4,6,8], '성적':[20,40,60,80]}, index = ['민정','도한','윤선','영준'])
score
# 2. 선형모델 모델링
from sklearn.linear_model import LinearRegression # target이 성적 수치형이라서 회귀!
linear_model = LinearRegression()
# X, y 분리
X = score[['시간']]
y = score['성적']
# 학습
linear_model.fit(X,y)
# 예측
linear_model.predict([[7]])- 하이퍼 파라미터 없음
- 최적의 가중치를 찾아나가는 과정이 단순 MSE 계산 -> 오차가 줄어드는 방향으로 학습
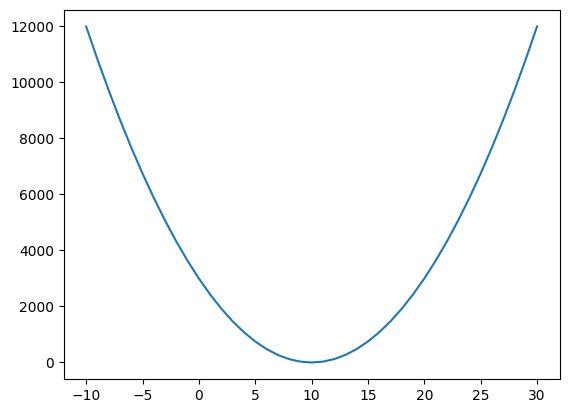
경사하강법 그래프
# 예측직선과 실제값의 차이 -> loss
# 가설함수 h(x)
def h(w,x):
return w*x + 0 # 지금은 가중치만 볼거라서 b 에 임의로 0 넣기
# 비용힘수 -> mse -> 평균제곱오차
def loss(data, target, weight): # data: X, target: 실제값, weight: 가중치
# 예측값
y_pre = h(weight,data)
# 오차
mse = ((y_pre - target)**2).mean()
return mse
# 예측 w 값의 범위
w_arr = range(-10,31)
# mse 를 리스트에 저장
loss_list = [loss(score['시간'], score['성적'], w) for w in w_arr]
# 시각화
import matplotlib.pyplot as plt
plt.plot(w_arr, loss_list)