판다 판다 판다스
1.[판다스] 판다스란?

판다스가 무엇인지 알아보자
2.[판다스] 시리즈
1차원 자료구조DataFrame(표)의 한 행이나 한 열을 표현한다.각 원소는 index로 접근할 수 있다.index는 순번과 지정한 이름 두 가지로 구성된다.⭐index명을 명시적으로 지정하지 않으면 순번이 index명이 된다.순번은 0부터 1씩 증가하는 정수.벡터화
3.[판다스] 결측치
결츠으으으으으으으으윽치
4.[판다스] 데이터 프레임 개요와 생성
데이터 프레임을 생성해보자
5.[판다스] 데이터 프레임의 주요 메서드와 기본 정보 조회
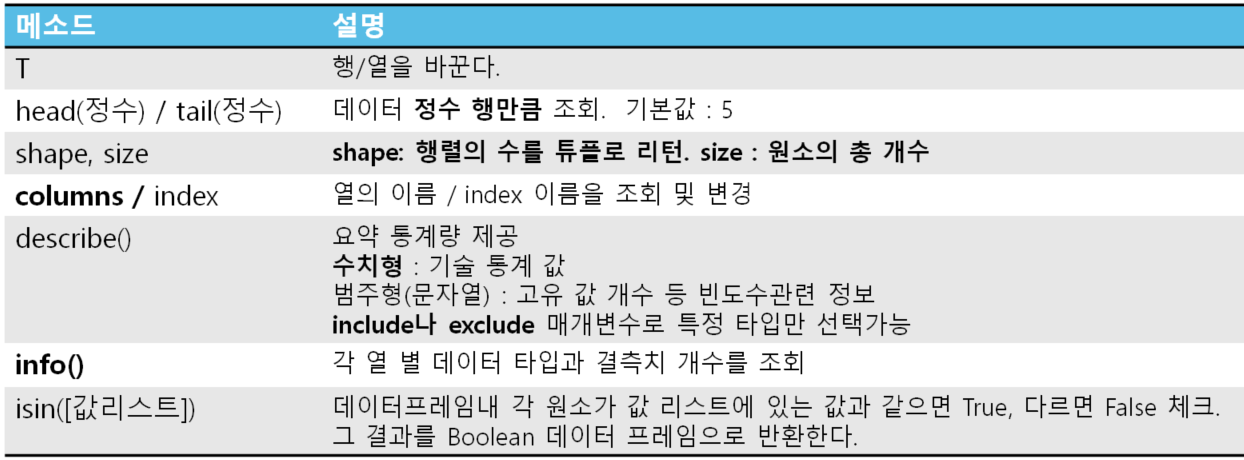
데이터 프레임의 주요 메서드와 분석을 위해서 데이터에 대한 기본 정보를 파악하는 기초 루틴
6.[판다스] 데이터 프레임 (3)
데이터 프레임 행과 열
7.[판다스] 데이터 프레임 행 별 열 별 값 조회
데이터 프레임의 열과 행 별로 값을 조회해보자!
8.[판다스] 정렬과 집계
행별, 열별 값 조회 11 열(컬럼) 조회 - Series로 리턴 df['컬럼명'] 컬럼 이름이 정수면 정수를 넣어주면 된다. df.컬럼명 컬럼 이름에 공백이 들어가 있으면 사용할 수 없다. 팬시 indexing 여러개의 컬럼을 조회할 경우 컬럼명들을 담은 리스트/튜
9.[판다스] 그룹핑
특정 열을 기준으로 데이터셋을 묶는다.\~~ 별 집계를 할 때 사용한다.구문DF.groupby('그룹으로묶을기준컬럼')\['집계할 컬럼'].집계함수()집계할 컬럼은 Fancy Indexing 으로 지정(리스트, 튜플로 전달)집계함수기술통계 함수들agg() / aggre
10.[판다스] groupby 관련 메서드
DataFrameGroupBy.filter(func, dropna=True, \*args, \*\*kwargs)특정 집계 조건을 만족하는 Group의 원소들만 조회한다.DataFrameGroupBy 를 함수에 전달한다.함수는 받은 DataFrameGroupBy로 집계를
11.[판다스] 데이터 프레임 합치기
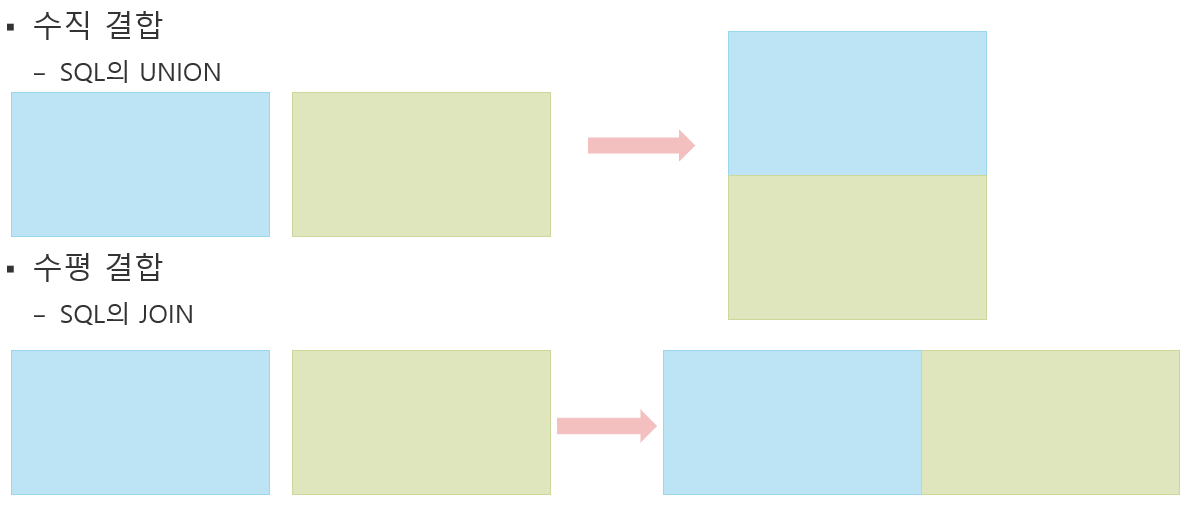
두개 이상의 DataFrame을 합쳐 하나의 DataFrame으로 만든다.기본 개념수직, 그리고 조인을 이용한 수평 결합 두 가지 모두 지원한다.수평 결합의 경우, full outer join과 inner join을 둘 다 지원한다.full outer join이 기본값
12.[판다스] 정돈된 데이터
대부분 실행환경에서의 많은 데이터 셋은 세부적 분석을 작업을 하기 전에 상당한 양의 데이터 재구성을 할 필요가 있다. 경우에 따라서는 전체 프로젝트 자체가 오로지 다른 사람들이 가공하기 쉬운 형태로 데이터를 재구성하는 일일 때도 있다.데이터 재구성의 목적은 정돈된 데이