1. 주요 메서드
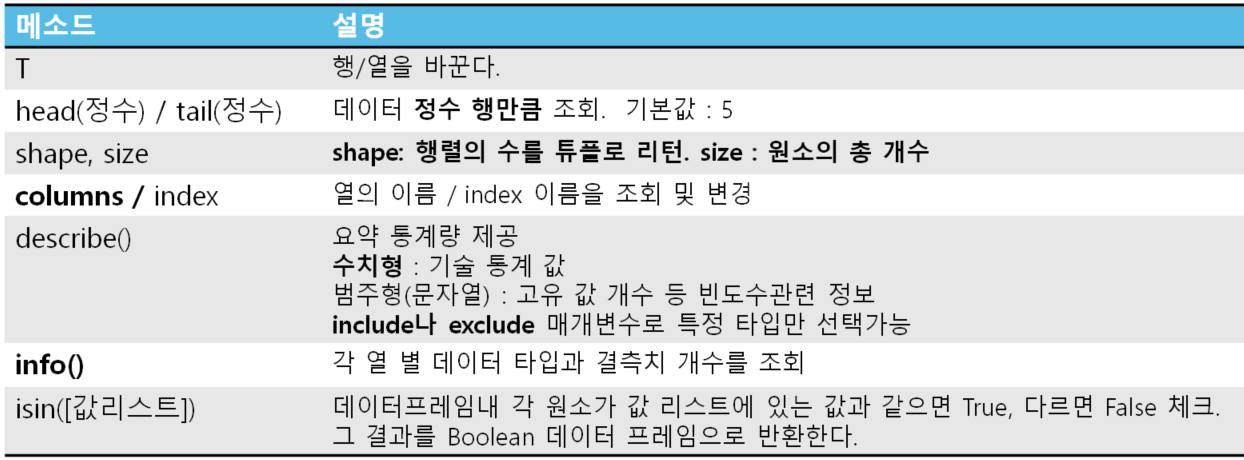
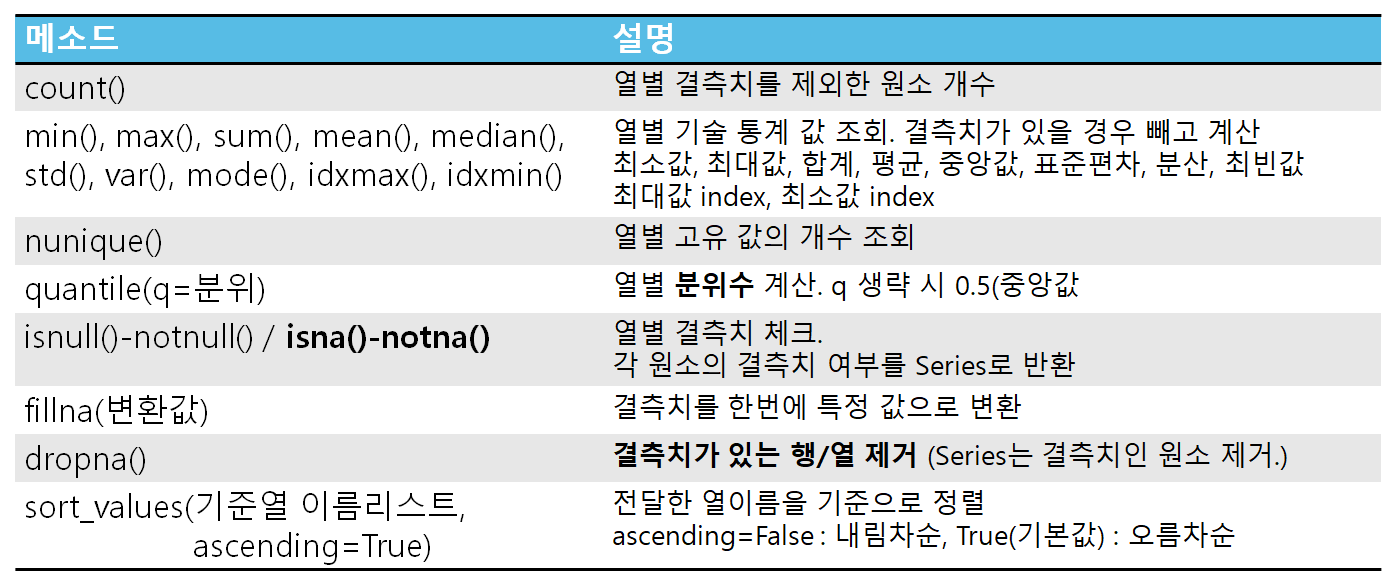
- size보단 거의 shape을 사용
- 컬럼 이름을 리스트로 저장해놓고 인덱스를 이용하기도 한다.
- info()
- 컬럼 정보를 확인한다.
- describe()
- 통계를 묶어서 알려줌
- 시리즈에서 쓴 것과 같음.
- 기술통계 함수
- 시리즈 별로 계산한다.
- isna()
- isnull()과 기능은 똑같다
- 차이점은 DF에서만 사용 가능
- 정렬
- 정렬할 기준을 알려줘야 함
2. 데이터 프레임의 기본 정보 조회
- csv 파일 읽기
- shape
- head()
- tail()
- info()
- isnull().sum() => 컬럼별 null 체크 (sum() 한번더 하면 총개수)
- index / columns : index와, 컬럼명 조회
- describe() : 숫자형-기술통계값, 문자열-총개수, 유니크값, 최빈값
이 작업들을 통해서 데이터에 대한 기본 정보를 알 수 있음.
2.1 TODO
# 파일 불러오기 전에 먼저 열어서 확인해보기(헤더, 인덱스 등등)
df = pd.read_csv('data/movie.csv', encoding='UTF-8')
df
# 행렬 크기와 데이터 수 확인
df.shape
# head로 확인
df.head()
# 컬럼도 많으면 중간에 생략됨.
# 헤드에 숫자 넣으면 더 볼 수 있음
# 맨 밑에 몇 행 몇 열인지 나온다.
# 테일로 확인하기
df.tail()
# info 사용하기
df.info()
# 전체 행 수, 컬럼에 대한 정보, 결측치 있는지 없는지, 데이터 타입, 메모리 사용량
# 플롯64 같은 것들 봐서 인트32로 바꿔줘서 메모리를 세이브할 수 있다.
# 결측치 확인
print(type(df.isnull().sum())) # 시리즈로 반환
print(df.isnull().sum())
# 전체 결측치가 알고 싶을 때
df.isnull().sum().sum()
# 결측치 확인 isna()도 가능
df.isna().sum()
# 이 친구는 데이터프레임에만 있음.
# 컬럼 이름 조회
df.columns
# 이름만 리스트로 조회한다.
# 인덱스 확인
df.index
# 전체적인 통계량 확인
df.describe()
# 통계치를 컬럼 단위로 내준다.
# 오브젝트 타입인 애들은 나오지 않는다. 수치형 타입만 나온다.
# 정수, 실수형 컬럼들의 요약 통계
# describe 파라미터
# include=[데이터타입, ...] 지정한 데이터 타입의 컬럼들의 요약 통계 조회
df.describe(include=[np.object])
# exclude=[데이터타입, ...] 지정한 데이터 타입을 뺀 컬럼들의 요약통계조회
# 보통은 인클루드를 많이 쓴다.
# 행과 열을 바꿔주는 메서드
df.describe(include=[np.object]).T
# .trance()
# 행이 몇 줄 안되는데 열이 많을 때 쓰면 좋다.
대한민국 4차 산업의 역군을 꿈꾸며.