자료구조
1.<자료구조>배열(Array)

많은 수의 데이터를 다룰 때 사용하는 자료구조각 데이터를 인덱스와 1:1 대응하는 구조메모리에 연속적으로 저장된다.인덱스를 이용해 데이터에 빠르게 접근 가능하다.데이터의 추가/삭제가 번거롭다\-길이를 정해서 생성해야 한다, 길이 변경할 때마다 새로운 배열을 생성해야함.
2.<자료구조>Map 정렬, 순회하기
HashMap은 정렬되지 않은 순서로 순회한다.알고리즘 문제를 풀다보면 벨류값을 기준으로 정렬해서 뽑고싶은 순간이 자주 온다!HashMap.entrySet()은 Map의 요소를 Entry 객체로 Set에 저장하고 리턴합니다. 리턴된 Set은 ArrayList 생성자의
3.<자료구조>LinkedList
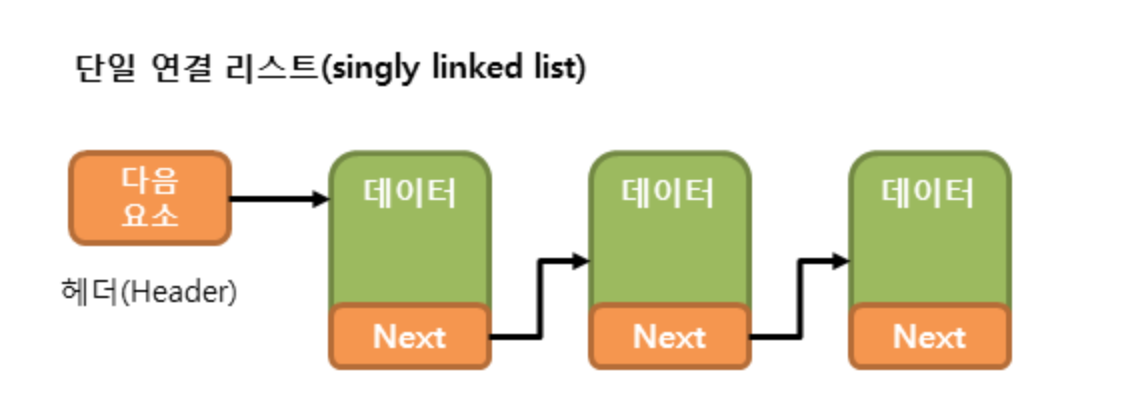
ArrayList는 인덱스를 가지고 있어 탐색이 빠르지만 삽입,삭제가 비효율적이고 연속, 순차적으로 메모리에 저장되어있어 메모리 활용이 비효율적이다.이러한 단점을 극복하기 위해 LinkedList가 고안되었다.LinkedList는 각각의 노드를 포인터로 연결하는 방식으
4.<자료구조>HashMap
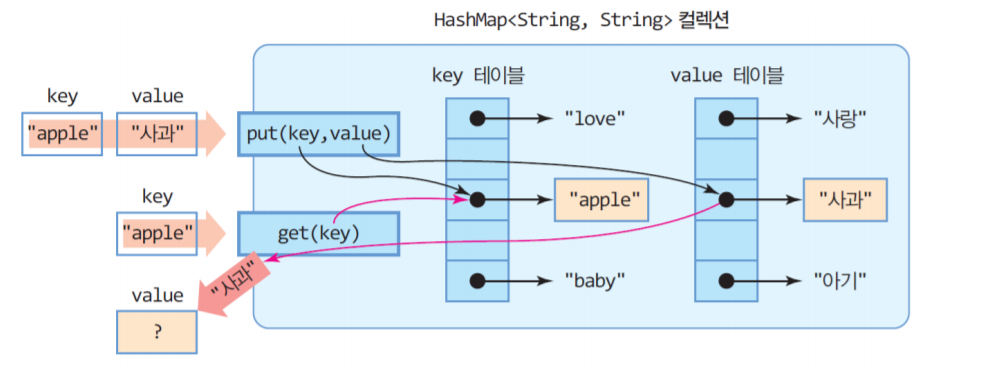
HashMap은 Map 인터페이스를 상속하고 있기에 Map의 성질을 그대로 가지고 있다. (Map은 키와 값으로 구성된 Entry객체를 저장하는 구조를 가지고 있는 자료구조)값은 중복 저장가능, 키는 중복 저장X. 만약 기존에 저장된 키와 동일한 키로 값을 저장하면 기
5.Stack
Stack의 사전적 정의는 '쌓다', '더미'입니다. 상자에 물건을 쌓아 올리듯이 데이터를 쌓는 자료 구조라고 할 수 있습니다. Stack의 가장 큰 특징은 나중에 들어간 것이 먼저 나오는 (LIFO, Last In First Out)의 형태를 띈다는 것입니다. 이 방
6.큐(Queue)
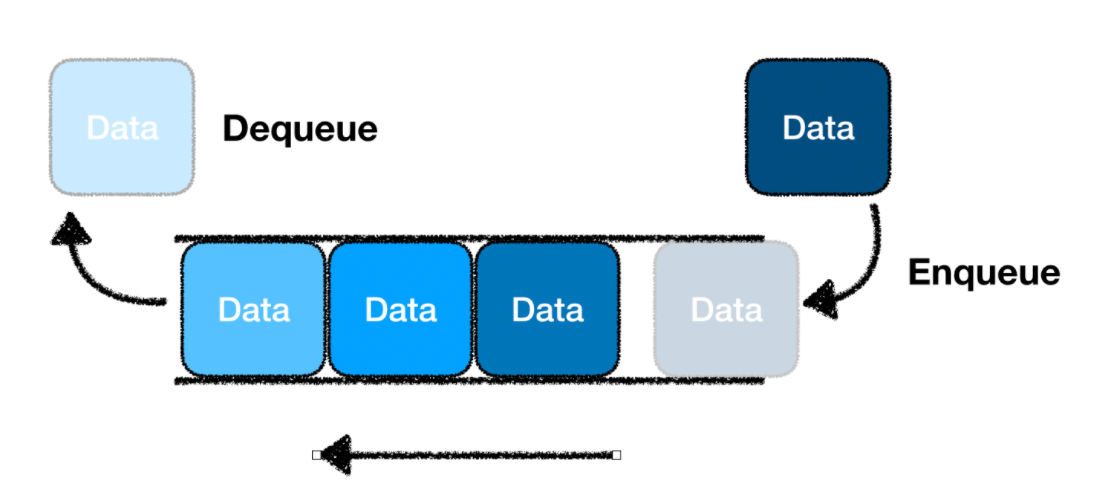
큐는 FIFO 선입선출(First In First Out)의 구조를 가진다. 즉, 큐에서는 먼저 들어온 데이터가 가장 먼저 나가는 구조이다. 큐는 입력 순서대로 데이터 처리가 필요할 때 사용그래프의 넓이 우선 탐색(BFS)에서 사용된다.Enqueue : 큐 맨 뒤에 데
7.<자료구조>힙 (Heap)
힙(heap)은 데이터에서 최대값과 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리(Complete Binary Tree)다.트리에서 사용되었던 노드가 아닌, Array를 활용하여 데이터를 관리합니다.노드를 삽입하면 배열(트리)의 가장 마지막에 삽입합니다.Top에 위
8.<자료구조>트리, 이진트리
트리는 노드와 링크로 구성된 비선형 자료구조이다. 계층적 구조를 나타낼 때 사용한다.BFS / DFS 와 같은 문제를 푸는 경우 비-선형 구조의 형태를 많이 활용 한다.먼저 선형구조와 비선형구조의 차이점을 알아보자.노드(Node):트리 구조의 자료 값을 담고 있는 다위
9.<자료구조>균형이진탐색트리, AVL트리
균형 이진 탐색 트리(Balanced Binary Search Tree, BST) 균형 이진 트리 : 모든 노드의 좌우 서브 트리 높이가 1이상 차이 나지 않는 트리. 노드의 삽입과 삭제가 일어날 때 균형을 유지하도록 하는 트리. AVL트리, Red-Black트리 AV
10.<자료구조> 그래프(Graph)
정점(Node, Vertex)과 간선(Edge,연결된 정점간의 관계를 표현)으로 이루어진 자료구조(Cyclic).G = (V,E)로 나타낸다. \- 간선에 방향이 없는 그래프(양방향 이동 가능) \- 정점(vertex): {A,B,C,D,E}
11.<자료구조>우선순위 큐
우선순위가 높은 데이터가 먼저 나옴(!= FIFO) \- 모든 데이터에 우선순위가 있음Dequeue시 우선순위가 높은 순으로 나온다.우선 순위가 같은 경우 FIFO앞쪽은 자연 순서에 따라 가장 적은 요소를 가지며 뒤쪽은 대기열에서 가장 큰 요소를 가리킵니다. 알파벳
12.<자료구조> 스택(Stack) & 큐(Queue)
스택(stack)이란 쌓아 올린다는 것을 의미한다. 책을 쌓는 것처럼 차곡차곡 쌓아 올린 형태의 자료구조를 말한다.LIFO(Last In First Out, 후입선출) == FILO(First In Last Out, 선입 후출) 구조단방향 입출력 구조 : 데이터의 들어