
Chapter 3 : List (리스트)
리스트(List)는 이름과 같이 자료의 '목록'을 다루는 자료구조다.
스택이나 큐와 같이 리스트도 자료를 일렬로 나열하여 저장하는 선형 자료구조다.
그러나, 스택이나 큐와 달리 입구와 출구를 정하지 않고 임의의 위치에서 자료를 추가하거나 꺼낼 수 있어 가장 활용이 자유롭다.
리스트는 이전에 배열 구조로 구현하는 것과 달리 연결된 구조를 이용하여 구현할 예정이다.
배열 구조로 구현한다면 여러 가지 편리한 점이 많지만 용량이 고정되는 등 여러 불편한 점도 있기 때문이다.
연결된 구조는 배열 구조보다 좀 복잡하고 어려지만 컴퓨터 분야에서 광범위하게 사용되어 매우 중요하다.
01 "리스트란?"
리스트는 우리가 생활에서 가장 많이 사용하는 자료 정리방법 중 하나다.
리스트 또는 선형 리스트는 가장 자유로운 선형 자료구조로 각 자료는 순서 또는 위치를 가진다.
리스트는 어떤 위치에서도 새로운 요소를 삽입할 수 있고 어느 위치에 요소를 삽입하려면 이후 모든 자료가 한 칸씩 뒤로 밀린다. 삭제도 동일하다. 어느 위치의 요소를 삭제하면 이후의 모든 요소의 위치가 변경된다.
리스트는 집합과 유사한 점이 많지만 중요한 차이가 있다.
리스트에서는 순서가 있지만 집합은 원소 사이에 순서가 없다. (따라서, 집합은 선형 자료구조라 볼 수 있다.)
또한, 집합은 원소의 중복을 허용하지 않는다.
02 "리스트의 연산"
01. 삽입 - insert(pos, e)
pos 위치에 새로운 요소 e를 삽입.
02. 삭제 - delete(pos)
pos 위치에 있는 요소를 꺼내서 반환.
+) getEntry(pos) : pos 위치에 있는 요소를 삭제하지 않고 반환.
03. isEmpty(), isFull()
isEmpty() : 리스트가 비어 있으면 True, 비어 있지 않으면 False 반환
isFull() : 리스트가 가득 차 있으면 True, 차 있지 않으면 False 반환.
04. size()
리스트에 들어 있는 전체 요소의 수를 반환.
05. 추가 연산
리스트는 활용이 자유로워 추가적인 다양한 연산이 가능하다.
1) append(e) : 맨 뒤에 새로운 요소를 삽입.
2) pop() : 맨 뒤의 요소를 삭제.
3) find(e) : 요소 e의 위치를 찾음.
4) replace(pos, e) : pos번째 요소를 변경.
5) display() : 리스트를 화면에 출력.
등 ...
03 "배열구조와 연결된 구조"
리스트는 배열 구조와 연결된 구조로 구현할 수 있다.
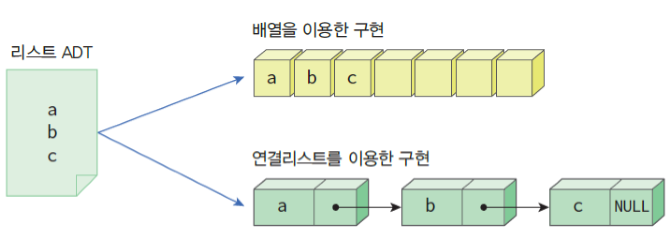
배열 구조로 있을 경우 모든 요소는 중간에 빈자리가 없이 반드시 메모리의 연속된 공간에 저장되어야 한다.
요소들이 연속된 공간에 있으면 원하는 위치의 요소를 빠르게 참조하고 관리할 수 있다.
연결된 구조(Linked structure)에서는 요소들을 메모리의 한군데 모아두는 것을 포기한다. 즉, 요소들이 메모리의 여기저기에 흩어져서 저장되는 것이다.
이렇게 흩어진 요소들은 링크를 이용하여 연결되어 있다.
요소들이 다른 요소를 가리키는 하나 이상의 링크를 갖도록 하여 전체를 순서대로 연결해 관리한다.
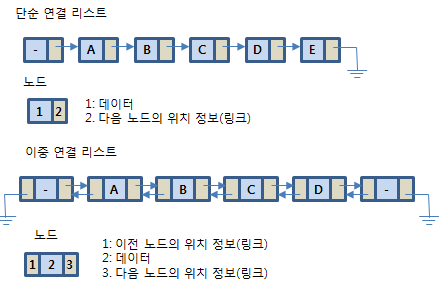
연결 리스트에서 하나의 상자를 노드(node)라 부르고 이는 데이터와 함께 링크를 갖는다.
링크의 수가 하나가 아닌 여러 개로 늘리면 트리나 그래프와 같이 훨씬 복잡한 구조들도 효율적으로 표현할 수 있다.
배열 구조와 연결된 구조의 장단점을 리스트의 몇 가지 연산으로 살펴보자.
01. 리스트 요소들에 대한 접근
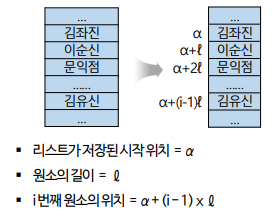
리스트의 k번째 요소의 위치를 찾는데 가장 빠른 방법이 뭘까?
- 배열 구조
- 모든 요소의 크기가 같고 연속된 메모리 공간이 있다.
- 배열의 시작 주소와 요소 하나의 크기를 알고 있다면?
→ k번째 요소의 위치 = 시작 주소 + (요소 하나의 크기)*k
- 연결된 구조
- 시작 노드의 주소만 알고 있다.
- 시작 노드에서부터 원하는 요소까지 링크를 따라 이동해야한다.
- 배열 구조에서 요소를 찾는데 걸리는 시간보다 원하는 요소 k의 숫자가 커질 수록 비효율적이다.
👉 배열 구조의 승!
그렇다면 왜 연결된 구조를 사용할까?
02. 리스트의 용량
- 배열 구조
- 용량이 고정되어 있어 고정된 용량을 늘리려면 같은 용량만큼 늘어나 필요한 만큼의 공간을 늘리거나 줄이는 것이 어렵다.
- 이는 메모리 낭비가 심해질 수 있다.
- 용량이 적게 할당될 경우 포화 상태가 자주 발생해 새로운 요소를 넣지 못하는 상황이 발생할 수 있다.
- 연결된 구조
- 용량이 고정되어 있지 않다.
- 필요할 때 필요한 크기만큼 새로 할당해 사용한다.
- 메모리를 효율적으로 사용할 수 있다.
- 메모리가 남아 있는 한 자료를 계속 넣을 수 있기 때문에 포화 상태가 잘 발생할 수 없다.
👉 연결된 구조의 승!
03. 리스트의 삽입 연산
- 배열 구조
- 중간에 자료를 삽입하려면 그 위치 이후 모든 요소를 한 칸씩 뒤로 밀어야한다.
- 많은 요소의 이동이 필요하다.
- 연결된 구조
- 삽입할 위치를 알고 있다면 효율적인 삽입이 가능하다.
- 삽입할 위치의 앞 노드의 링크와 새로운 요소의 링크만 수정하면 된다.
👉 연결된 구조의 승!
04. 리스트의 삭제 연산
- 배열 구조
- 삽입 연산과 동일하게 요소 하나를 삭제하게 되면 그 위치 이후 모든 요소를 한 칸씩 앞으로 당겨야한다.
- 많은 요소의 이동이 필요하다. (비효율적)
- 연결된 구조
- 삭제할 노드 바로 앞 노드의 링크만 수정하면 된다. (효율적)
👉 연결된 구조의 승!
04 "배열 구조의 리스트 : 파이썬 리스트"
파이썬의 리스트는 자료 구조 리스트를 배열 구조로 구현한 하나의 사례다.
파이썬 리스트는 클래스로 구현되어 있어 다양한 연산들을 멤버함수(메서드)로 지원한다.
| 멤버함수(method) | example |
|---|---|
| insert(pos, e) | pos 위치에 새로운 요소 e를 삽입. |
| append(e) | 새로운 요소 e를 맨 뒤에 삽입. |
| pop(pos) | pos 위치의 요소를 꺼내고 반환. |
| pop() | 맨 뒤의 요소를 꺼내고 반환. |
| extend(lst) | 리스트 lst를 리스트에 삽입. |
| count(e) | 리스트에서 요소 e의 개수를 세어 반환. |
| index(e, [시작], [종료]) | 요소 e가 나타나는 가장 작은 위치(인덱스)를 반환. 탐색을 위한 시작 위치와 종료 위치 지정 가능. |
| remove(e) | 요소 e를 리스트에서 제거. |
| reverse(e) | 리스트 요소들의 순서를 뒤집기. |
| sort([key], [reverse]) | 요소들을 key를 기준으로 오름차순 정렬. reverse=True면 내림차순으로 정렬. |
파이썬 리스트는 배열 구조를 사용하지만 용량이 제한되지 않도록 내부적으로 구현되어 있다.
리스트가 포화 상태일 때 기존 리스트의 용량만큼 늘려 요소를 추가할 수 있다.
05 "연결 리스트의 구조와 종류"
01. 노드(node)
연결 리스트에서 하나의 노드는 하나의 데이터와 함께 하나 이상의 링크를 갖는다.
링크는 다른 노드를 가리키는(다른 노드의 주소를 저장하는) 변수다.
02. 헤드 포인터(head pointer)
연결 리스트는 시작 노드만 알면 링크로 매달려 있는 모든 노드에 순차적으로 접근할 수 있다.
가장 앞에 있는 노드를 보통 머리 노드(head node)라 하고 이 머리 노드의 주소를 저장하는 변수를 헤드 포인터(head pointer)라 한다. 마지막 노드를 보통 꼬리 노드(tail node)라 부르는데 꼬리 노드의 링크를 처리하는 방법에 따라 단순 연결과 원형 연결로 구분한다.
03. 연결 리스트의 종류
1) 단순 연결 리스트 (singly linked list)
: 하나의 방향으로만 연결된 리스트.
꼬리 노드의 링크는 마지막 노드라는 것을 나타내기 위해 None을 갖고 있다.
2) 원형 연결 리스트 (circular linked list)
: 꼬리 노드의 링크가 None이 아닌 머리 노드를 가리키는 리스트.
3) 이중 연결 리스트 (doubly linked list)
: 하나의 노드가 두 개의 링크(이전 노드, 다음 노드의 링크)를 갖고 있는 리스트.
이전 노드에 대한 정보도 있어 어디로든 쉽게 찾아갈 수 있다는 장점이 있다.
편리한 만큼 링크를 이중으로 정확히 유지해야 하므로 코드가 복잡해진다.
06 "단순 연결 구조로 리스트 구현하기"
01. Node 클래스의 정의와 생성자.
단순 연결 구조의 노드는 데이터 필드와 하나의 링크를 갖고 있다.
link는 디폴트 인수 기능을 이용해 인수가 저장되지 않으면 None으로 자동으로 초기화하도록 하였다.
# 코드 3.1a: 단순 연결 구조를 위한 Node 클래스
class Node:
def __init__(self, elem, link=None):
self.data = elem # 데이터 멤버 생성 및 초기화
self.link = link # 링크 생성 및 초기화02. append() 연산 - 새로운 노드를 뒤에 추가.
# 코드 3.1b: Node 클래스 - append(node)연산
def append(self, node): # self 다음 node를 넣는 연산.
if node is not None:
node.link = self.link # node의 링크가 self.link를 가리키게 함.
self.link = node # self 링크가 node를 가리키게 함.03. popNext() 연산 - 다음 노드를 연결 구조에서 꺼내는 Node 클래스
# 코드 3.1c: Node 클래스 - popNext()연산
def popNext(self): # self의 다음 노드를 삭제하는 연산
next = self.link # 현재 노드(self)의 다음 노드
if next is not None:
self.link = next.link # self.link가 next의 link를 가리키게 함.
return next # 다음 노드를 반환04. 단순 연결 리스트 클래스의 데이터
맨 처음에는 공백 상태가 되어야 하므로 생성자에서 head는 None으로 초기화한다.
# 코드 3.2a: 단순 연결 리스트 클래스 정의와 생성자
class LinkedList: # 단순 연결 리스트 클래스
def __init__(self): # 생성자
self.head = None # head 선언 및 None으로 초기화05. isEmpty(), isFull() 연산 - 공백 상태, 포화 상태 검사.
# 코드 3.2b: LinkedList 연산 - 포화, 공백 상태 검사
def isEmpty(self): # 공백 상태 검사
return self.head == None # head가 None이면 공백
def isFull(self): # 포화 상태 검사
return False # 연결된 구조에서는 포화 상태 없음.06. getNode(pos) 연산 - pos번째 노드를 반환.
pos번째 요소를 구하기 위해서는 먼저 해당 요소가 들어 있는 노드를 찾아야한다.
따라서 pos번째 노드를 반환하는 연산을 구현해야한다.
(이 연산은 배열 구조에서는 전혀 필요 없다는 것에 유의✨)
# 코드 3.2c: LinkedList 연산 - getNode(pos) : pos번째 노드를 반환
def getNode(self, pos):
if pos < 0:
return None
p = self.head
for i in range(pos):
if p == None:
return None
p = p.link
return p07. getEntry(pos) 연산 - pos번째 요소를 반환.
이 연산은 위에서 만든 getNode(pos)로 찾은 노드에 대한 데이터를 반환하는 연산이다.
# 코드 3.2d: LinkedList 연산 - getEntry(pos) : pos번째 요소를 반환
def getEntry(self, pos):
node = self.getNode(pos)
if node == None:
return None
else:
return node.datapos번째 요소를 알기 위해서는 pos번의 getNode(pos) 연산을 해서 이루어지기 때문에 연결된 구조의 단점을 볼 수 있다.
08. insert(pos, e) 연산 - pos 위치에 새로운 요소를 삽입.
pos 위치에 새로운 노드를 삽입하려면 pos-1 위치의 노드 before를 알아야한다. (연결된 구조의 특징)
연산의 순서는 아래와 같습니다.
1) 요소를 이용해 새로운 노드 node를 만듦
2) pos-1 위치의 노드 before를 찾음
3) before에 node를 추가함.
여기서 pos-1 위치의 노드가 없다는 것은 리스트이 맨 앞에 추가하려는 것으로 보고 연결 구조의 맨 앞에 새로운 노드를 넣는 경우를 추가해 줍니다.
# 코드 3.2e: LinkedList 연산 - insert(pos, e) : pos 위치에 새로운 요소를 삽입
def insert(self, pos, e):
node = Node(e, None) # 삽입할 새로운 노드 생성.
before = self.getNode(pos-1) # 삽입할 위치 이전 노드 탐색.
if before == None: # before가 없다면 리스트 맨 앞에 노드 생성.
node.link = self.head
self.head = node
else: # 아닌 경우 before 뒤에 추가.
before.append(node)09. delete(pos) 연산 - pos 위치의 요소를 삭제.
pos 위치의 노드를 삭제할 때에도 pos-1 위치의 노드 before를 알아야한다.
삭제를 위해 변경되는 것은 pos 위치의 노드가 아니라 pos-1의 노드의 링크이기 때문이다.
pos 위치 다음의 노드를 찾아 (popNext()) pos-1의 노드를 연결해준다.
before가 없다면 머리 노드를 삭제하는 상황이다.
# 코드 3.2f: LinkedList 연산 - delete(pos) : pos 위치의 요소를 삭제
def delete(self, pos):
before = self.getNode(pos-1) # 삭제할 위치 이전 노드 탐색.
if before == None: # 머리 노드 삭제하게 되는 경우.
before = self.head
if self.head is not None:
self.head = self.head.link # 머리 노드가 다음 노드로 변경.
return before
else:
return before.popNext()10. size() 연산 - 전체 요소의 수 구하기.
연결 리스트에서는 전체 요소의 수를 바로 알 수 없다.
머리 노드부터 꼬리 노드 까지 한번씩 방문하여 세어보는 방법이 필요하다.
# 코드 3.2g: LinkedList 연산 - size() : 전체 요소의 수를 구함.
def size(self):
ptr = self.head
count = 0
while ptr != None:
ptr = ptr.link
count += 1
return count11. display() 연산 - 리스트를 화면에 출력.
size() 연산과 비슷한 방식으로 구현할 수 있다.
# 코드 3.2h: LinkedList 연산 - display() : 화면 출력
def display(self, msg='LinkedList:'):
print(msg, end=' ')
ptr = self.head
while ptr is not None:
print(ptr.data, end='->')
ptr = ptr.link
print('None')12. replace(pos, e) 연산 - pos번째 요소를 e로 교체.
단순하게 getNode() 함수를 이용해 pos번째 요소를 찾고 해당 node가 None이 아니라면 요소 e로 변경해준다.
# 예제 3-5)1번
def replace(self, pos, e):
node = self.getNode(pos)
if node != None:
node.data = e13. 연결 리스트와 파이썬 리스트(배열 구조) 비교
- 5개의 요소를 삽입
- 하나의 요소 교체
- 세 개의 요소 삭제
▶ 연결 리스트
# 코드 3.3: LinkedList와 파이썬 리스트 비교
# 단순연결리스트(LinkedList) 사용
s = LinkedList()
s.display('연결리스트( 초기 ): ')
s.insert(0, 10)
s.insert(0, 20)
s.insert(1, 30)
s.insert(s.size(), 40)
s.insert(2, 50)
s.display("연결리스트(삽입x5): ")
# s.delete(2)
# s.insert(2, 90)
s.replace(2, 90)
s.display("연결리스트(교체x1): ")
s.delete(2)
s.delete(3)
s.delete(0)
s.display("연결리스트(삭제x3): ")
> 출력
연결리스트( 초기 ): None
연결리스트(삽입x5): 20->30->50->10->40->None
연결리스트(교체x1): 20->30->90->10->40->None
연결리스트(삭제x3): 30->10->None▶ 파이썬 리스트
# 파이썬의 리스트 사용
l = []
print('파이썬list( 초기 ):', l)
l.insert(0, 10)
l.insert(0, 20)
l.insert(1, 30)
l.insert(len(l), 40)
l.insert(2, 50)
print('파이썬list(삽입x5):', l)
l[2] = 90
print('파이썬list(교체x1):', l)
l.pop(2)
l.pop(3)
l.pop(0)
print('파이썬list(삭제x3):', l)
> 출력
파이썬list( 초기 ): []
파이썬list(삽입x5): [20, 30, 50, 10, 40]
파이썬list(교체x1): [20, 30, 90, 10, 40]
파이썬list(삭제x3): [30, 10]07 "이중 연결 구조로 리스트 구현하기"
이중 연결 구조에서는 노드에 링크가 하나 더 추가되어 삽입과 삭제를 위한 연산이 더 복잡해진다.
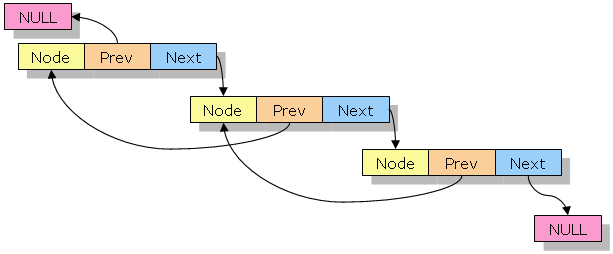
01. 이중 연결 구조의 노드 클래스 정의와 생성자
이중 연결을 위해서는 두 개의 링크가 필요한데, 각각 prev와 next라 한다.
next는 단순 연결 구조의 link와 동일하고,
prev는 이전 노드를 가리킨다.
# 코드 3.4a: 이중 연결 구조를 위한 DNode class 정의
class DNode:
def __init__(self, elem, prev=None, next=None):
self.data = elem
self.next = next
self.prev = prev02. append() 연산
1) node의 next가 self.next를 가리키게 함.
2) node의 prev가 self를 가리키게 함.
3) node.next가 있으면(다음 노드가 있으면), 이전 노드로 node를 가리키게 함.
4) self의 next가 node를 가리키게 함.
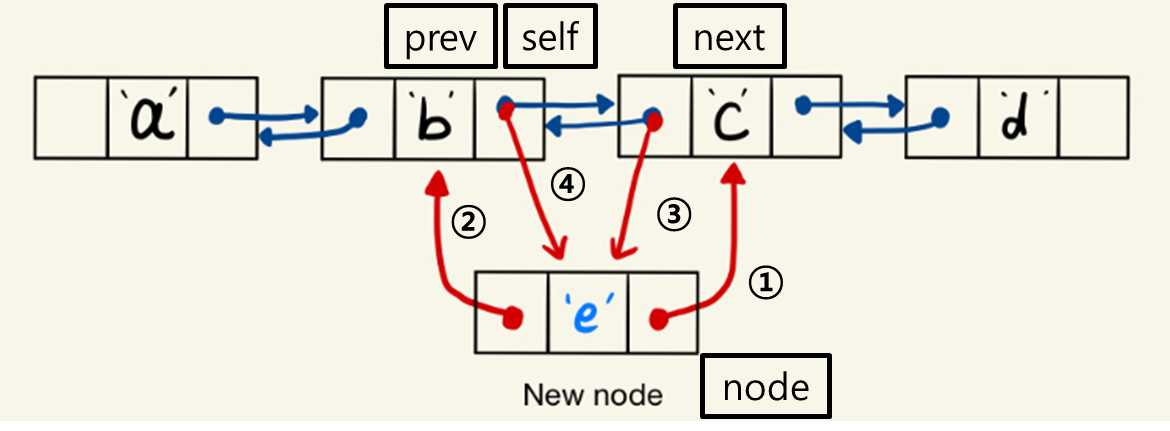
# 코드 3.4b: DNode의 append(node) 연산 - 새로운 노드를 뒤에 추가
def append(self, node):
if node is not None:
node.next = self.next
node.prev = self
if node.next is not None:
node.next.prev = node
self.next = node03. popNext() 연산
1) self의 next가 node의 next를 가리키게 함.
2) self의 next가 있으면 self.next.prev가 self를 가리키게 함.
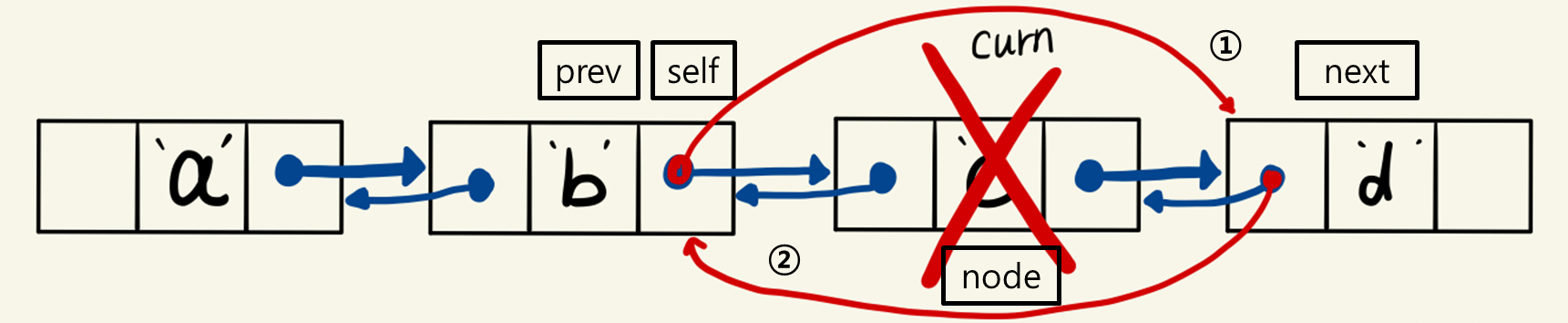
# 코드 3.4c: DNode의 popNext() 연산 - 다음 노드를 연결 구조에서 꺼냄.
def popNext(self):
node = self.next
if node is not None:
self.next = node.next
if self.next is not None:
self.next.prev = self
return node04. 이중 연결 리스트 클래스 정의와 생성자
DBlLinkedList의 데이터 멤버는 LinkedList와 동일하다.
# 코드 3.5a: 이중 연결 리스트 클래스 정의와 생성자
class DblLinkedList: # 이중 연결 리스트 클래스
def __init__(self): # 생성자
self.head = None # head 선언 및 None으로 초기화05. isEmpty(), isFull(), getEntry(pos)
LinkedList의 getNode(), size(), display() 등의 연산에서 .link를 .next로 수정하면 동일하게 동작한다.
# 코드 3.5b: DblLinkedList 연산 - 포화, 공백 상태 검사
def isEmpty(self): # 공백 상태 검사
return self.head == None # head가 None이면 공백
def isFull(self): # 포화 상태 검사
return False # 연결된 구조에서는 포화 상태 없음.
# 코드 3.5c: DblLinkedList 연산 - getNode(pos) : pos번째 노드를 반환
def getNode(self, pos):
if pos < 0:
return None
p = self.head
for i in range(pos):
if p == None:
return None
p = p.next
return p
# 코드 3.5d: DblLinkedList 연산 - size() : 전체 요소의 수를 구함.
def size(self):
ptr = self.head
count = 0
while ptr != None:
ptr = ptr.next
count += 1
return count
# 코드 3.5e: DblLinkedList 연산 - display() : 화면 출력
def display(self, msg='LinkedList:'):
print(msg, end=' ')
ptr = self.head
while ptr is not None:
print(ptr.data, end='<=>') # 이중 연결 표시.
ptr = ptr.next # 다음 노드로 이동.
print('None')06. insert(pos, e) 연산
pos 위치에 새로운 노드를 삽입하려면 pos-1 위치의 노드 before를 알아야한다.
이중 연결 구조에서는 pos 위치의 노드를 찾더라도 prev 링크를 통해 pos-1번째 노드를 알 수 있다.
# 코드 3.5e: DblLinkedList 연산 - 삽입 연산 insert(pos, e)
def insert(self, pos, e):
node = DNode(e) # 삽입할 이중 연결 구조의 노드 생성
before = self.getNode(pos-1) # 삽입할 위치 이전 노드 탐색
if before == None:
node.next = self.head # node의 다음 노드가 현재 head가 되고,
if node.next is not None:
node.next.prev = node # 그 노드의 prev를 node로 수정하여
self.head = node # 마지막으로 머리 노드 head를 node로 변경.
else: # 아닌 경우 before 다음에 추가.
before.append(node)07. delete(pos) 연산
삭제 연산도 getNode(), size(), display() 연산처럼 LinkedList의 getNode(), size(), display() 등의 연산에서 .link를 .next로 수정하면 동일하게 동작한다.
# 코드 3.5f: DblLinkedList 연산 - 삭제 연산 delete(pos)
def delete(self, pos):
before = self.getNode(pos-1)
if before == None:
before = self.head
if self.head is not None: # 머리 노드를 삭제하면 head가 다음 노드로 변경.
self.head = self.head.next
if self.head is not None:
self.head.prev = None
return before
else:
return before.popNext+) replace()
def replace(self, pos, e):
node = self.getNode(pos)
if node != None:
node.data = e08. 이중 연결 리스트 클래스 테스트
▶ 이중 연결 리스트
# 연결리스트 테스트
s = DblLinkedList()
s.display('연결리스트( 초기 ): ')
s.insert(0, 10)
s.insert(0, 20)
s.insert(1, 30)
# s.display()
s.insert(3, 40)
s.insert(2, 50)
s.display("연결리스트(삽입x5): ")
s.replace(2, 90)
s.display("연결리스트(교체x1): ")
s.delete(2)
s.delete(3)
s.delete(0)
s.display("연결리스트(삭제x3): ")
print("")
> 출력
연결리스트( 초기 ): None
연결리스트(삽입x5): 20<=>30<=>50<=>10<=>40<=>None
연결리스트(교체x1): 20<=>30<=>90<=>10<=>40<=>None
연결리스트(삭제x3): 30<=>90<=>10<=>40<=>None▶ 파이썬 리스트
# 파이썬
l = []
print('파이썬list( 초기 ):', l)
l.insert(0, 10)
l.insert(0, 20)
l.insert(1, 30)
l.insert(len(l), 40)
l.insert(2, 50)
print('파이썬list(삽입x5):', l)
l[2] = 90
print('파이썬list(교체x1):', l)
l.pop(2)
l.pop(3)
l.pop(0)
print('파이썬list(삭제x3):', l)
> 출력
파이썬list( 초기 ): []
파이썬list(삽입x5): [20, 30, 50, 10, 40]
파이썬list(교체x1): [20, 30, 90, 10, 40]
파이썬list(삭제x3): [30, 10]<후기>

이중 연결 리스트를 멘토링 시간에 나갈 땐 이해가 안되고 구현도 잘 안되서 답답했었는데
내가 getNode() 연산과 size() 연산에서 .link를 .next로 수정하지 않아서 오류가 계속 생겼다는 것을 알고 제대로 실행되는 것을 보니 아주 뿌듯했다!
다음은 트리인데 트리는 배우면서 탐색하는 부분이 게임 순서 맞추기(?) 느낌이 나서 아주 재밌게 배웠다.😋
계속해서 KEEP GOING~🚗
