
09-1. 우선순위 큐의 이해
이름만 보았을 때 우선순위 큐는 큐에서 확장하는 수준이 될 것 같지만 실제로 '큐'의 구현과 '우선순위 큐'의 구현에는 많은 차이가 있다.
우선순위 큐와 우선순위
'큐'의 핵심 연산은 큐에 데이터를 삽입하는 enqueue와 큐에서 데이터를 꺼내는 dequeue가 있다.
'우선순위 큐'에서도 핵심 연산이 동일하게 enqueue와 dequeue다.
하지만, 연산의 결과에 차이가 있다.
'큐'의 연산의 결과로는 먼저 들어간 데이터가 먼저 나오지만, '우선순위 큐
의 경우 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나오게된다.
우선순위 큐에 저장되는 데이터들은 모두 우선순위를 '지니는'것이 아닌 데이터를 근거로 우선순위를 판단할 수 있어야한다.
이 우선순위는 프로그래머가 결정할 수 있으며 목적에 맞게 우선순위를 결정하면 된다.
우선순위는 정수로 표현되기도 하며 정수값이 클수록 우선순위가 높은건지 낮을수록 우선순위가 높은건지도 결정하기 나름이다.
우선순위가 같은 데이터가 존재할 수도 있고 우선순위가 서로 다른 데이터들만 저장된다면 자료구조로 활용할 수 있는 범위가 제한적이게 된다.
우선순위 큐의 구현 방법
우선순위 큐를 구현하는 방법은 다음 세 가지가 있다.
- 배열을 기반으로 구현하는 방법
- 연결 리스트를 기반으로 구현하는 방법
- 힙(heap)을 이용하는 방법
배열이나 연결 리스트를 이용하면 우선순위 큐를 매우 간단히 구현할 수 있다.
다음 그림에서 저장된 숫자는 데이터인 동시에 우선순위 정보라고 가정한다.
숫자 1이 가장 높은 우선순위를 뜻하며 이보다 값이 커질수록 우선순위는 낮아진다.
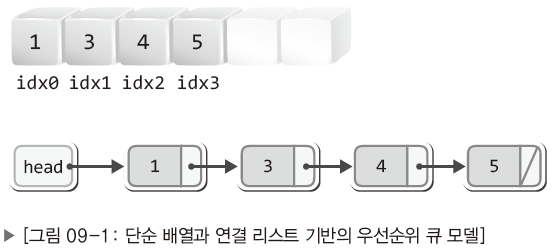
배열의 경우 데이터의 우선순위가 높을수록 배열의 앞쪽에 데이터를 위치시킨다. 이렇게 하면 우선수위가 높은 데이터를 반환 및 소멸하는 것이 보다 쉽다.
하지만 이렇게 배치할 경우 데이터를 삽입 및 삭제하는 과정에서 데이터를 한 칸씩 뒤로 밀거나 한 칸씩 앞으로 당기는 연산을 수반해야 한다.
그리고 우선순위가 가장 낮은 데이터를 저장하는 경우 삽입의 위치를 찾기 위해서 배열에 저장된 모든 데이터와 우선수위의 비교를 진행해야 할 수도 있는 최악의 상황이 벌어지기도 한다.
연결 리스트의 경우 배열의 첫 번째 단점은 갖지 않는다.
두 번째 단점은 연결 리스트에도 존재한다.
삽입의 위치를 찾기 위해서 첫 번째 노드에서부터 시작해서 마지막 노드에 저장된 데이터와 우선순위의 비교를 진행해야 할 수도 있다.
이 단점은 데이터의 수가 적은 경우 크게 문제되지 않을 수 있다.
하지만 데이터의 수가 많아지면, 연결된 노드의 수가 많아지면 노드의 수에 비례해서 성능을 저하시키는 주원인이 된다.
그래서 우선순위 큐는 단순 배열도, 연결 리스트도 아닌 '힙'이라는 자료구조를 이용해서 구현하는 것이 일반적이다.
힙(Heap)
우리는 이전에도 연결 리스트를 기반으로 스택을 구현한 적이 있다.
우선순위 큐도 '힙'이라는 자료구조를 이용해 구현하고자 한다.
그렇다면 힙(Heap)이란 무엇일까?
힙은 '이진 트리'이되 '완전 이진 트리'다.
그리고 모든 노드에 저장된 값은 자식 노드에 저장된 값보다 크거나 같아야 한다.
즉, 루트 노드에 저장된 값이 가장 커야 한다.
여기서 말하는 값이란 말 그래도 '값'일 수도, '우선순위'가 될 수도 있다.
하지만 힙을 기반으로 우선순위 큐를 구현할 때는 '우선순위'가 값이 된다.
힙을 보여주는 간단한 예시 트리가 다음과 같이 있다.
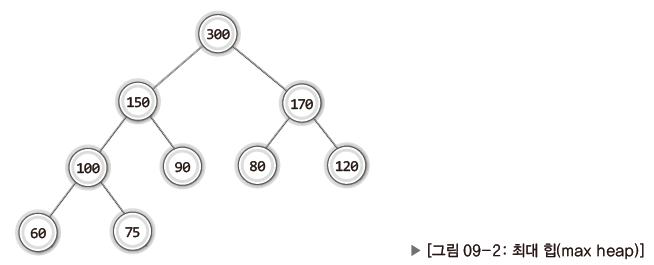
위와 같이 루트 노드로 올라갈수록 저장된 값이 커지는 완전 이진 트리를 가리켜 최대 힙(max heap)이라 한다.
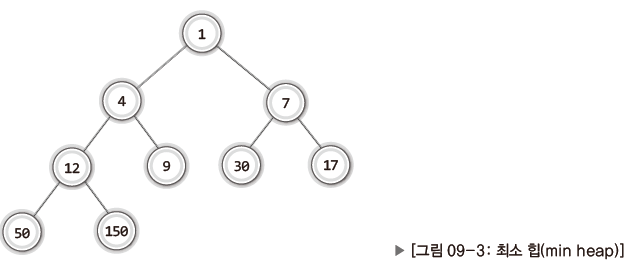
그리고 위 그림과 같이 루트 노드로 올라갈수록 저장된 값이 작아지는 완전 이진 트리를 가리켜 최소 힙(min heap)이라 한다.
이렇듯 힙은 루트 노드에 우선순위가 가장 높은 데이터를 위치시킬 수 있는 자료구조기 때문에 이를 기반으로 하면 우선순위 큐를 간다히 구현할 수 있다.
(힙 자체의 의미는 '차곡차곡 무엇인가를 쌓아 올린 더미'로 이 트리 모양과 흡사해 지어진 이름이다.)
09-2. 힙의 구현과 우선순위 큐의 완성
힙의 구현은 곧 우선순위 큐의 완성이다.
따라서 힙과 우선순위 큐를 동일하게 인식할 수 있다.
하지만, 동일하지 않으며 우선순위 큐와 힙을 어느정도는 구분할줄 알아야 한다.
힙은 우선순위 큐의 구현에 어울리는 완전 이진 트리의 일종이라는 것을 알아야한다.⭐
0. 힙의 구현
힙을 구현한고 이를 기반으로 우선순위 큐를 구현하고자 한다.
힙의 구현을 위해서는 데이터의 저장과 삭제 방법을 먼저 알아야 한다.
1) 힙에서의 데이터 저장과정
데이터의 저장과정을 '최소 힙'을 기준으로 배워보자.
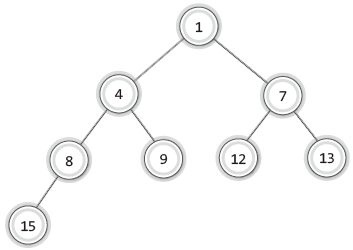
위 그림에 쓰여있는 숫자를 데이터 겸 우선순위라 하자.
그리고 숫자가 작을수록 우선순위가 높다고 가정한다.
그렇다면 위 트리는 우선순위 관점에서 힙이 맞고 완전 이진 트리면서 어느 위치든 자식 노드 데이터의 우선순위 ≤ 부모 노드 데이터의 우선순위가 성립한다.
이 상황에서 3을 저장한다고 생각해보자.
저장한 후에도 트리의 우선순위 관계를 유지하는 것이 관건이다.
문제 해결을 위한 알고리즘이 딱 떠올리기가 어렵다.
이렇게 생각해보자.
"새로운 데이터는 우선순위가 제일 낮다는 가정하에서 마지막 위치에 저장한다. 그리고 부모 노드와 우선순위를 비교해서 위치가 바껴야 한다면 바꿔준다. 바뀐 다음에도 올바른 위치에 도달할 때 까지 계속해서 부모 노드와 비교한다."
여기에서 말하는 '마지막 위치'는 노드를 추가한 이후에도 완전 이진 트리가 유지되는, 마지막 레벨의 가장 오른쪽 위치를 뜻한다.
위에서 언급한 방법을 그림과 함께 살펴보자.
| No. | Pic. | Expl. |
|---|---|---|
| 1 | 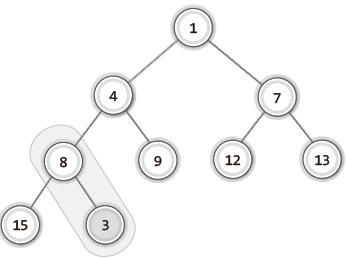 | 마지막 노드에 새 노드를 추가하고 부모 노드와 우선순위 비교. 두 노드의 위치 바뀔 필요 있음. |
| 2 | 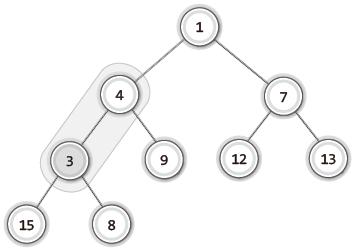 | 두 노드의 위치가 바뀐 이후 이어서 다시 부모 노드와 비교. 부모 노드보다 우선순위 높으므로 바뀔 필요 있음. |
| 3 | 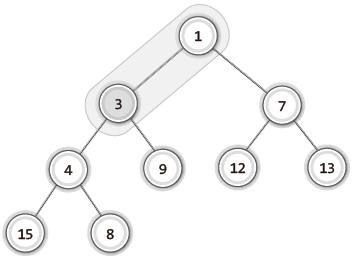 | 두 노드의 위치가 바뀐 이후 부모 노드와 비교. 부모 노드의 우선순위가 더 높으므로 비교 종료. |
최종적으로 힙의 조건을 만족하여 새로운 데이터를 넣는데 성공했다.
이렇듯 데이터의 추가과정은 마지막 위치에 데이터를 두고서 부모 노드와의 비교를 통해 자신의 위치를 찾아가는 매우 단순한 방식이다.
2) 힙에서의 데이터 삭제과정
삭제과정은 저장과정보다 까다로울 것이 예상된다.
만약 가장 높은 우선순위의 데이터를 삭제한다고 생각해보자.
힙에서 루트 노드를 삭제하는 것이므로 루트 노드 자체를 삭제하는 것은 어렵지 않지만 삭제 이후에도 힙의 구조를 유지하는 것을 어떻게 할지 고민해야한다.
루트 노드를 삭제한 이후 어떻게 이 부분을 채울 것인가...?
다음 그림과 순서를 보면서 삭제과정에 대해 이해해보자.
| No. | Pic. | Expl. |
|---|---|---|
| 1 |  | 우선순위가 가장 높은 데이터 1이 담긴 노드를 삭제. |
| 2 | 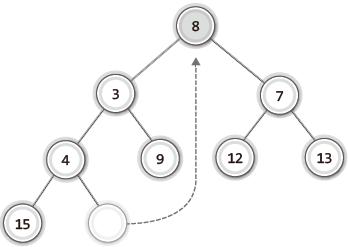 | 빈 루트 노드에 마지막 노드를 옮긴 다음 자식 노드와 비교.⭐ 비교를 통한 제자리 찾는 과정 반복. |
| 3 | 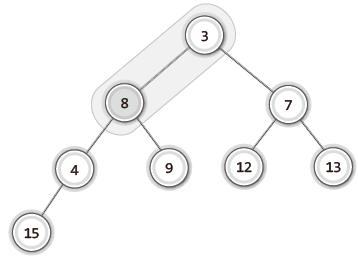 | 두 개의 자식 중 우선순위가 높은 3이 저장된 왼쪽 자식 노드와 8이 저장된 노드 비교 후 교환. 오른쪽 자식 노드의 우선순위가 높다면 오른쪽 자식 노드와 교환. 우선순위가 낮은 자식 노드와 교환하게 될 경우 힙의 기본 조건이 무너짐.⭐ |
| 4 | 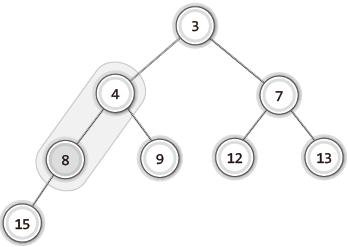 | 숫자 8과 자식 노드를 비교. 4와 9 중에서 우선순위가 높은 4와 비교를 진행. 4가 8보다 우선순위 높으므로 교환 진행. 8과 자식 노드인 15 비교. 8의 우선순위가 더 높으므로 삭제과정 마무리. |
3) 삽입과 삭제의 과정에서 보인 성능 평가
우선순위 큐의 구현에 있어서 단순 배열이나 연결 리스트보다 힙이 더 적합한 이유가 뭘까?
시간 복잡도로 이를 비교해보자.
(최악의 경우를 생각해야 하므로 우선순위가 낮은 데이터를 저장하는 경우를 생각한다.)
- 배열 기반의 우선순위 큐
- 데이터 저장의 시간 복잡도:
배열에 저장된 모든 데이터와의 우선순위 비교과정을 거쳐야한다. - 데이터 삭제의 시간 복잡도:
맨 앞에 저장된 데이터를 삭제하면 된다.
- 데이터 저장의 시간 복잡도:
- 연결 리스트 기반의 우선순위 큐
- 데이터 저장의 시간 복잡도:
저장된 모든 데이터와의 우선순위 비교과정을 거쳐야한다. - 데이터 삭제의 시간 복잡도:
맨 앞에 저장된 데이터를 삭제하면 된다.
- 데이터 저장의 시간 복잡도:
- 힙 기반의 우선순위 큐
- 데이터 저장의 시간 복잡도:
- 데이터 삭제의 시간 복잡도:
힙 기반의 우선순위 큐의 경우 삽입이나 삭제의 경우 동반되는 비교연산은 주로 부모 노드와 자식 노드 사이에 일어나기 때문에 트리의 높이에 해당하는 수만큼만 비교연산을 진행하면 된다.
힙은 완전 이진 트리이므로, 힙에 저장할 수 있는 데이터의 수는 트리의 높이가 하나 늘 때마다 두 배씩 증가한다.
때문에 데이터의 수가 두 배 늘 때마다, 비교연산의 횟수는 1회 증가한다.
시간 복잡도 와 의 차이는 데이터의 수가 많아질수록 그 성능 차이가 크기 때문에 힙 기반의 우선순위 큐가 더 효율적이다라고 할 수 있다.
4) 힙 구현에 어울리는 자료구조
우선순위 큐의 구현에는 힙이 어울리는 것으로 결론이 났다.
힙의 구현방법은 어떨까?
트리를 구현하는 방법에 배열 또는 연결 리스트로 구현했기 때문에 둘 중 하나를 선택하면 된다.
앞서 배울 땐 연결 리스트를 기반으로 트리를 구현했으니 힙도 연결 리스트 기반으로 구현될 것이라 생각할 수 있다.
하지만 완전 이진 트리 구조를 갖고 있고 그 구조를 유지해야하기 때문에 '힙'은 '배열'기반으로 구현해야 한다.
연결 리스트를 기반으로 힙을 구현하면 새로운 노드를 힙의 '마지막 위치'에 추가하는 것이 쉽지 않기 때문이다.
5) 배열 기반 힙 구현에 필요한 지식들
Chapter 08에서 배열을 기반으로 트리를 구성하는 방법에 대해 살짝 언급한 적이 있다.
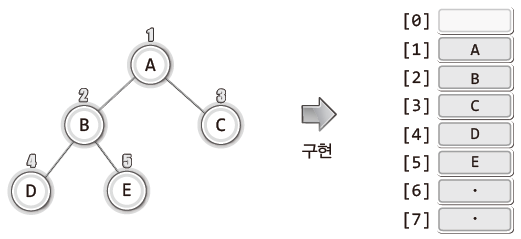
위 그림과 같이 노드에 고유 번호를 부여하여 그 번호가 각 노드의 데이터가 저장 될 배열의 인덱스 값이 되는 것이다.
구현의 편의를 위해서 인덱스가 0인 위치의 배열 요소는 사용하지 않았다.
여기서 배열을 기반으로 힙을 구현하기 위해 더 알아야할 것은 뭘까?
왼쪽 그리고 오른쪽 자식 노드의 인덱스 값을 얻는 방법, 그리고 부모 노드의 인덱스 값을 얻는 방법이다.
자식 노드의 인덱스 값을 얻는 방법은 데이터의 삭제를 위해서,
부모 노드의 인덱스 값을 얻는 방법은 데이터의 추가(저장)을 위해서 필요하다.
다음 식으로 인덱스 값을 얻을 수 있다.
- 왼쪽 자식 노드의 인덱스 값: (부모 노드의 인덱스 값)
- 오른쪽 자식 노드의 인덱스 값: (부모 노드의 인덱스 값)
- 부모 노드의 인덱스 값: (자식 노드의 인덱스 값)
이진 트리는 레벨이 증가함에 따라서 추가할 수 있는 자식 노드의 수가 2배씩 증가하므로 2를 나누고 곱하는 방식으로 부모 노드와 자식 노드의 인덱스 값을 구할 수 있다.
여기서 주의해야할 점은 부모 노드의 인덱스 값을 구하기 위한 나눗셈 연산은 몫 구하기(정수형 나눗셈)이다.
1. 원리 이해 중심의 힙 구현
위에서 이해한 원리를 중심으로 힙을 먼저 알아보자.
그리고 보다 사용하기 좋은, 합리적인 형태로 변경할 예정이다.
1) 헤더파일 정의 (SimpleHeap.h)
#ifndef __SIMPLE_HEAP_H__
#define __SIMPLE_HEAP_H__
#define TRUE 1
#define FALSE 0
#define HEAP_LEN 100
typedef char HData;
typedef int Priority;
typedef struct _heapElem
{
Priority pr; // 값이 작을수록 높은 우선순위
HData data;
} HeapElem;
typedef struct _heap
{
int numOfData;
HeapElem heapArr[HEAP_LEN];
} Heap;
void HeapInit(Heap * ph);
int HIsEmpty(Heap * ph);
void HInsert(Heap * ph, HData data, Priority pr);
HData HDelete(Heap * ph);
#endif위의 헤더파일은 순수한 힙의 구현을 위한 헤더파일이 아닌 우선순위 큐의 구현을 염두에 두고 정의한 헤더파일이다.
이는 HeapElem 구조체의 정의에서 알 수 있다.
힙에 저장될 데이터의 모델을 정의한 구조체로 우선수위 정보를 별도로 담을 수 있도록 정의되어 있다.
이는 우선순위 큐의 구현을 고려했다는 것이다.
따라서 위의 헤더파일에 선언된 HDelete함수는 우선순위 큐와 마찬가지로 데이터의 삽입 순서에 상관없이 우선순위에 근거하여 삭제가 이뤄질 수 있도록 정의할 것이다.
2) 소스파일 정의 (SimpleHeap.c)
헤더파일에 선언된 함수들을 정의해보자.
이에 앞서 힙에 대한 몇 가지 사실들에 대해 정리하고 가자.
- 힙은 완전 이진 트리.
- 힙의 구현은 배열 기반으로 하며 인덱스가 0인 요소 비워두기.
- 힙에 저장된 노드의 개수와 마지막 노드의 고유번호는 일치.
- 노드의 고유번호가 노드가 저장되는 배열의 인덱스 값.
- 우선순위를 나타내는 정수 값이 작을수록 높은 우선순위. (가정)
그리고 소스파일은 다음과 같이 정의된다.
#include "SimpleHeap.h"
// 힙의 초기화
void HeapInit(Heap * ph)
{
ph->numOfData = 0;
}
// 힙이 비었는지 확인
int HIsEmpty(Heap * ph)
{
if(ph->numOfData == 0)
return TRUE;
else
return FALSE;
}
// 부모 노드의 인덱스 값 반환
int GetParentIDX(int idx)
{
return idx/2;
}
// 왼쪽 자식 노드의 인덱스 값 반환
int GetLChildIDX(int idx)
{
return idx*2;
}
// 오른쪽 자식 노드의 인덱스 값 반환
int GetRChildIDX(int idx)
{
return GetLChildIDX(idx)+1;
}
// 두 개의 자식 노드 중 높은 우선순위의 자식 노드 인덱스 값 반환
int GetHiPriChildIDX(Heap * ph, int idx)
{
if(GetLChildIDX(idx) > ph->numOfData)
return 0;
else if(GetLChildIDX(idx) == ph->numOfData)
return GetLChildIDX(idx);
else
{
if(ph->heapArr[GetLChildIDX(idx)].pr > ph->heapArr[GetRChildIDX(idx)].pr)
return GetRChildIDX(idx);
else
return GetLChildIDX(idx);
}
}
// 힙에 데이터 저장
void HInsert(Heap * ph, HData data, Priority pr)
{
int idx = ph->numOfData+1;
HeapElem nelem = {pr, data};
while(idx != 1)
{
if(pr < (ph->heapArr[GetParentIDX(idx)].pr))
{
ph->heapArr[idx] = ph->heapArr[GetParentIDX(idx)];
idx = GetParentIDX(idx);
}
else
break;
}
ph->heapArr[idx] = nelem;
ph->numOfData += 1;
}
// 힙에서 데이터 삭제
HData HDelete(Heap * ph)
{
HData retData = (ph->heapArr[1].data);
HeapElem lastElem = ph->heapArr[ph->numOfData];
int parentIdx = 1;
int childIdx;
while(childIdx = GetHiPriChildIDX(ph, parentIdx))
{
if(lastElem.pr <= ph->heapArr[childIdx].pr)
break;
ph->heapArr[parentIdx] = ph->heapArr[childIdx];
parentIdx = childIdx;
}
ph->heapArr[parentIdx] = lastElem;
ph->numOfData -= 1;
return retData;
}힙에서 데이터를 저장하고 삭제하는 함수를 설명하기 이전에 GetHiPriChildIDX 함수 구현에 대해 먼저 자세히 살펴보자.
int GetHiPriChildIDX(Heap * ph, int idx)
{
if(GetLChildIDX(idx) > ph->numOfData)
return 0;
else if(GetLChildIDX(idx) == ph->numOfData)
return GetLChildIDX(idx);
else
{
if(ph->heapArr[GetLChildIDX(idx)].pr > ph->heapArr[GetRChildIDX(idx)].pr)
return GetRChildIDX(idx);
else
return GetLChildIDX(idx);
}
}이 함수에 노드의 인덱스 값을 전달하면, 이 노드의 두 자식 노드 중에서 우선순위가 높은 것의 인덱스 값을 반환한다. (else문에 해당하는 부분)
이 함수는 인자로 전달된 노드에 자식 노드가 없으면 0을 반환하고 자식 노드가 하나인 경우에는 그 노드의 인덱스 값을 반환한다. (if와 else if문에 해당하는 부분)
위의 함수에서는 자식 노드가 하나도 존재하지 않는 상황을 ph->numOfData와 비교한 연산문을 통해 확인하고 있는데 이 부분이 이해가 잘 안 갈 수 있다.
힙은 완전 이진 트리이므로 오른쪽 자식 노드만 있는 상황이 발생하지 않는다.
따라서 왼쪽 자식 노드가 없다면 자식 노드가 존재하지 않는 것으로 판단하는 것이다.
자식 노드가 하나도 없는 노드는 단말 노드가 되고 단말 노드의 왼쪽 자식 노드의 인덱스 값은 힙에 저장된 노드의 수를 넘어선다.
따라서 ph->numOfData가 더 크다면 단말 노드가 되는 것이다.
그 다음 else if 문의 연산문에서 자식 노드가 하나일 경우 힙은 완전 이진 트리이므로 그 자식 노드는 왼쪽 자식 노드가 되고 힙의 마지막 노드가 된다.
그 다음 데이터 저장보다 데이터 삭제 함수(HDelete)함수에 대해 먼저 알아보자.
데이터 삭제과정은 "힙의 마지막 노드를 루트 노드의 위치에 올린 다음 자식 노드와의 비교과정을 거쳐 자신의 위치를 찾을 때까지 내린다."이다.
여기서 루트 노드로 올려진 마지막 노드는 자신의 위치를 찾을 때까지 아래로 이동하면서 자신의 위치를 찾아가는데 이러한 빈번한 이동을 코드에 그대로 담을 필요가 없다.
최종 목적지가 결정되면 그 곳으로 한번에 옮기면 되는 것이다.
따라서 위에서 그림과 함께 설명했던 것과 코드 구현에서 살짝 다른 점이 있지만 개념은 동일하다.
코드에 주석을 추가하여 다시 한번 자세히 살펴보자.
HData HDelete(Heap * ph)
{
HData retData = (ph->heapArr[1].data); // 반환을 위한 삭제할 데이터 저장
HeapElem lastElem = ph->heapArr[ph->numOfData]; // 힙의 마지막 노드 저장
// 아래의 변수 parentIdx에는 마지막 노드가 저장될 위치 정보가 저장됨.
int parentIdx = 1; // 루트 노드가 위치해야 할 인덱스 값 저장 (시작)
int childIdx;
// 루트 노드의 우선순위가 높은 자식 노드를 시작으로 반복문 시작
while(childIdx = GetHiPriChildIDX(ph, parentIdx))
{
if(lastElem.pr <= ph->heapArr[childIdx].pr) // 마지막 노드와 우선순위 비교
break; // 마지막 노드의 우선순위가 높은 경우 반복문 탈출
// 마지막 노드보다 우선수위 높으니 비교대상 노드의 위치를 한 레벨 올리기
ph->heapArr[parentIdx] = ph->heapArr[childIdx];
// 마지막 노드가 저장될 위치 정보는 한 레벨 내리기
parentIdx = childIdx;
} // 반복문을 탈출하면 parentIdx에는 마지막 노드의 위치 정보가 저장됨
ph->heapArr[parentIdx] = lastElem; // 마지막 노드 최종 저장
ph->numOfData -= 1; // 노드 갯수 하나 삭제
return retData; // 삭제된 노드 반환
}따라서 함수 HDelete에서는 마지막 노드가 있어야 할 위치를 parentIdx에 저장된 인덱스 값을 갱신해가며 찾아가고 있다.
HDelete함수가 호출되면서 변수 parentIdx는 1로 초기화된다.
1은 루트 노드의 인덱스 값이므로 변수 parentIdxfmf 1로 초기화한 것은 마지막 노드를 루트 노드로 옮긴 상황으로 이해할 수 있다.
그리고 while문의 if문 다음에 위치한 두 문장의 실행은, 루트 노드로 옮겨진 마지막 노드와 우선순위가 높은 자식 노드와의 교환이 이뤄지는 상황으로 이해할 수 있다.
마지막으로 데이터 저장과정을 다룬 함수 HInsert에 대해 알아보자.
힙에서의 데이터 저장은 새로운 데이터는 우선순위가 가장 낮다는 가정하에 마지막 위치에 저장하고 부모 노드와의 우선순위 비교를 통해 자신의 위치를 찾을 때까지 위로 올린다.
HDelete함수 구현과 마찬가지로 HInsert함수 구현에서는 새로운 데이터가 담긴 노드를 매과정 옮길 필요가 없다.
코드에 주석을 추가하여 다시 한번 자세히 살펴보자.
void HInsert(Heap * ph, HData data, Priority pr)
{
int idx = ph->numOfData+1; // 새 노드가 저장될 인덱스 값을 idx에 저장
HeapElem nelem = {pr, data}; // 새 노드의 생성 및 초기화
// 새 노드가 저장될 위치가 루트 노드의 위치가 아니라면 while문 반복
while(idx != 1)
{
// 새 노드와 부모 노드의 우선순위 비교
if(pr < (ph->heapArr[GetParentIDX(idx)].pr)) // 새 노드의 우선순위가 높다면
{
// 부모 노드를 한 레벨 내리기
ph->heapArr[idx] = ph->heapArr[GetParentIDX(idx)];
// 새 노드를 한 레벨 올리기
idx = GetParentIDX(idx);
}
else // 새 노드의 우선순위가 높지 않다면
break;
}
ph->heapArr[idx] = nelem; // 새 노드를 배열에 저장
ph->numOfData += 1;
}위 함수에서도 새로운 노드가 저장되어야 할 위치 정보를 변수 idx를 통해서 계속 갱신해 나가고 있다.
따라서 앞서 그림을 통해서 설명한 노드의 삽입과정을 그대로 코드로 옮긴 것으로 볼 수 있다.
3) 실행파일 정의 (SimpleHeapMain.c) + 리뷰
위에서 구현한 힙의 테스트를 위해 실행파일을 정의해보자.
그리고 개선해야 할 부분에 대해 알아보자.
#include <stdio.h>
#include "SimpleHeap.h"
int main()
{
Heap heap;
HeapInit(&heap); // 힙의 초기화
HInsert(&heap, 'A', 1); // 문자 'A'를 우선순위 1로 저장
HInsert(&heap, 'B', 2); // 문자 'B'를 우선순위 2로 저장
HInsert(&heap, 'C', 3); // 문자 'C'를 우선순위 3로 저장
printf("%c \n", HDelete(&heap));
HInsert(&heap, 'A', 1); // 문자 'A' 한번 더 저장
HInsert(&heap, 'B', 2); // 문자 'B' 한번 더 저장
HInsert(&heap, 'C', 3); // 문자 'C' 한번 더 저장
printf("%c \n", HDelete(&heap));
while(!HIsEmpty(&heap))
printf("%c \n", HDelete(&heap));
return 0;
}
> gcc .\SimpleHeap.c .\SimpleHeapMain.c
> .\a.exe
> 출력
A
A
B
B
C
C실행 결과, 우선순위가 높은 문자들이 먼저 꺼내져서 구현한 힙이 잘 작동되고 있다고 생각할 수 있다.
다만, 약간의 부족한 점이 있다.
typedef struct _heapElem
{
Priority pr; // typedef int Priority
HData data; // typedef char HData
}위 구조체는 힙을 이루는 노드에 관한 것인데 구조체의 멤버로 우선순위 정보를 담는 변수가 선언되어 있다. 이것이 문제가 될 수 있다.
예를 들어 데이터 저장을 위한 함수 HInsert에서 void HInsert(Heap * ph, HData data, Priority pr);라는 함수 선언을 보면 데이터의 우선순위 정보도 넘겨줌으로써 작동되는 거을 볼 수 있다.
데이터를 입력하기 전에 프로그래머가 알아서 우선순위를 결정하고 그 값을 전달해줘야 한다는 것이다.
우선순위라는 것은 데이터를 기준으로 결정되는 것이 대부분인데 우선순위의 결정 기준을 세우는 것이 아니고 일일이 프로그래머가 우선순위를 매기는 것은 데이터 양이 많아질수록 효율이 떨어지고 불편할 것이다.
이 부분을 develop할 필요가 있다.
2. 사용 가능 수준의 힙 구현
앞서 구현한 힙의 부족한 점을 해결해보자.
프로그래머가 우선순위의 판단 기준을 힙에 설정해야한다.
이는 힙의 적용 범위와 활용 방법이 넓어짐을 의미한다.
앞서 힙의 구현을 위한 구조체는 다음과 같았다.
typedef struct _heapElem
{
Priority pr;
HData data;
} HeapElem;
typedef struct _heap
{
int numOfData;
HeapElem heapArr[HEAP_LEN];
} Heap;우선순위의 판단 기준을 힙에 설정할 수 있어야한다는 요구사항을 만족하기 위해서는
다음과 같이 하나의 구조체로 정의하면 된다.
typedef struct _heap
{
PriorityComp * comp; // typedef int (*ProirityComp)(HData dq, HData d2);
int numOfData;
HData heapArr[HEAP_LEN]; // typedef char HData;
} Heap;HeapElem이라는 구조체가 사라지고 우선순위의 높고 낮음을 판단할 수 있는 함수 포인터 변수를 Heap구조체 안에 넣었다.
두 개의 데이터를 대상으로 우선순위의 높고 낮음을 판단할 수 있는 함수를 등록할 예정이다.
그리고 여기에 등록할 함수는 프로그래머가 직접 정의해야 ㅎ한다.
예시로 아래 가이드라인대로 함수를 작성할 것이다.
- PriorityComp의 typedef 선언
typedef int (PriorityComp)(HData d1, HData d2);- 첫 번째 인자의 우선순위가 높다면 0보다 큰 값 반환
- 두 번째 인자의 우선순위가 높다면 0보다 작은 값 반환
- 첫 번째, 두 번째 인자의 우선순위가 동일하다면 0이 반환
위 가이드라인을 근거로 데이터간 우선순위의 비교에 사용될 함수를 정의해서 힙에 등록해야 한다.
따라서 힙의 초기화 함수는 다음과 같이 수정된다.
void HeapInit(Heap * ph, PriorityComp pc)
{
ph->numOfData = 0;
ph->comp = pc; // 우선순위 비교에 사용되는 함수 등록
}더불어 HInsert함수를 호출하면서 우선순위 정보를 직접 전달하지 않기 때문에 이 함수도 다음과 같이 수정되어야 한다.
void HInsert(Heap * ph, HData data);
이렇게 변경되면 프로그래머는 우선순위 값을 직접 계산할 필요가 없고 우선순위를 비교할 수 있는 기준이 되는 함수만 정의해서 등록하면 된다.
1) 헤더파일 정의 (UsefulHeap.h)
위에서 수정한 내용을 바탕으로 나머지 부분을 마저 수정해보자.
수정해야 하는 함수는 다음과 같다.
int GetHiPriChildIDX(Heap * hp, int idx);void HInsert(Heap * ph, HData data);HData HDelete(Heap * ph);
변경 포인트는 우선순위의 비교를 위해 사용된 대소 비교 연산자가 존재하는 문장들이다.
수정된 헤더파일은 다음과 같다.
#ifndef __USEFUL_HEAP_H__
#define __USEFUL_HEAP_H__
#define TRUE 1
#define FALSE 0
#define HEAP_LEN 100
typedef char HData;
typedef int (*PriorityComp)(HData d1, HData d2);
typedef struct _heap
{
PriorityComp comp; // 포인터 변수로 정의 X
int numOfData;
HData heapArr[HEAP_LEN];
} Heap;
void HeapInit(Heap * ph, PriorityComp pc);
int HIsEmpty(Heap * ph);
void HInsert(Heap * ph, HData data);
HData HDelete(Heap * ph);
#endif여기서 typedef int (PrioirityComp)(HData d1, HData d2);그리고 구조체 안에서 PriorityComp * comp; 로 포인터의 위치를 바꿔서 선언해도 제대로 동작한다.
두 코드 모두 동일한 것을 의미한다.
2) 소스파일 정의 (UsefulHeap.c)
헤더파일 수정 및 구조체의 변경에 따른 수정된 소스파일은 다음과 같다.
#include "UsefulHeap.h"
// 힙의 초기화 (수정)
void HeapInit(Heap * ph, PriorityComp pc)
{
ph->numOfData = 0;
ph->comp = pc;
}
// 힙이 비었는지 확인
int HIsEmpty(Heap * ph)
{
if(ph->numOfData == 0)
return TRUE;
else
return FALSE;
}
// 부모 노드의 인덱스 값 반환
int GetParentIDX(int idx)
{
return idx/2;
}
// 왼쪽 자식 노드의 인덱스 값 반환
int GetLChildIDX(int idx)
{
return idx*2;
}
// 오른쪽 자식 노드의 인덱스 값 반환
int GetRChildIDX(int idx)
{
return GetLChildIDX(idx)+1;
}
// 두 개의 자식 노드 중 높은 우선순위의 자식 노드 인덱스 값 반환 (수정)
int GetHiPriChildIDX(Heap * ph, int idx)
{
if(GetLChildIDX(idx) > ph->numOfData)
return 0;
else if(GetLChildIDX(idx) == ph->numOfData)
return GetLChildIDX(idx);
else
{
// 수정
if(ph->comp(ph->heapArr[GetLChildIDX(idx)], ph->heapArr[GetRChildIDX(idx)]) < 0)
return GetRChildIDX(idx);
else
return GetLChildIDX(idx);
}
}
// 힙에 데이터 저장 (수정)
void HInsert(Heap * ph, HData data)
{
// 수정
int idx = ph->numOfData+1;
while(idx != 1)
{
// 수정
if(ph->comp(data, ph->heapArr[GetParentIDX(idx)]) > 0)
{
ph->heapArr[idx] = ph->heapArr[GetParentIDX(idx)];
idx = GetParentIDX(idx);
}
else
break;
}
ph->heapArr[idx] = data;
ph->numOfData += 1;
}
// 힙에서 데이터 삭제 (수정)
HData HDelete(Heap * ph)
{
// 수정
HData retData = ph->heapArr[1];
HData lastElem = ph->heapArr[ph->numOfData];
int parentIdx = 1;
int childIdx;
// 수정
while(childIdx = GetHiPriChildIDX(ph, parentIdx))
{
if(ph->comp(lastElem, ph->heapArr[childIdx]) >=0)
break;
ph->heapArr[parentIdx] = ph->heapArr[childIdx];
parentIdx = childIdx;
}
ph->heapArr[parentIdx] = lastElem;
ph->numOfData -= 1;
return retData;
}3) 실행파일 정의 (UsefulHeapMain.c)
막으로 위에서 수정한 헤더파일과 소스파일을 바탕으로 잘 작동하는지 확인해볼 수 있는 실행파일 정의다.
여기서 주목해야할 부분은 우선순위 비교에 사용되는 함수를 직접 정의하고 이를 힙에 등록하는 부분이다.
#include <stdio.h>
#include "UsefulHeap.h"
int DataPriorityComp(char ch1, char ch2) // 우선순위 비교함수
{
return ch2-ch1;
// return ch1-ch2;
}
int main()
{
Heap heap;
HeapInit(&heap, DataPriorityComp); // 우선순위 비교함수 등록
HInsert(&heap, 'A');
HInsert(&heap, 'B');
HInsert(&heap, 'C');
printf("%c \n", HDelete(&heap));
HInsert(&heap, 'A');
HInsert(&heap, 'B');
HInsert(&heap, 'C');
printf("%c \n", HDelete(&heap));
while(!HIsEmpty(&heap))
printf("%c \n", HDelete(&heap));
return 0;
}
> gcc .\UsefulHeap.c .\UsefulHeapMain.c
> .\a.exe
> 출력
A
A
B
B
C
C실행파일에서 우선순위 비교함수로 정의되어 있는 DataPriorityComp함수를 살펴보자.
int DataPriorityComp(char ch1, char ch2) // 우선순위 비교함수
{
return ch2-ch1;
// return ch1-ch2;
}이 함수는 첫 번째 인자로 전달된 문자의 아스키 코드 값이 작을 때 0보다 큰 값을 반환하도록 정의되었다.
그런데 이 함수를 정의하는 기준을 앞서 다음과 같이 결정하였다.
- 첫 번째 인자의 우선순위가 높다면 0보다 큰 값을 반환
- 두 번째 인자의 우선순위가 높다면 0보다 작은 값을 반환
- 두 인자의 우선순위가 같다면 0이 반환
따라서 위 함수의 우선순위 판단 기준은 아스키 코드 값이 작은 문자의 우선순위가 더 높다는 것을 알 수 있다.
3. 우선순위 큐 구현 - 사용 가능 수준의 힙 이용
힙을 완성했으니 이번 Chapter의 목표인 우선순위 큐를 구현할 차례다.
우선순위 큐를 고려해서 힙을 구현했기 때문에 사실상 우선순위 큐를 거의 다 구현한 것이나 마찬가지다.
실제로 힙의 HInsert와 HDelete 함수의 호출 결과는 우선순위 큐의 enqueue와 dequeue 연산결과와 일치한다.
그래도 우선순위 큐의 구현까지 해서 끝까지 마무리 지어보자~!
우선 우선순위 큐의 ADT를 정의하고 앞서 구현한 힙을 활용하여 우선순위 큐를 완성해보자.
1) ADT 정의
✅Operations:
-
void PQueueInit(PQueue * ppq, PriorityComp pc);
- 우선순위 큐의 초기화를 진행
- 우선순위 큐 생성 후 제일 먼저 호출되는 함수
-
int PQIsEmpty(PQueue * ppq);
- 우선순위 큐가 빈 경우 TRUE(1), 그렇지 않은 경우 FALSE(0) 반환
-
void PEnqueue(PQueue * ppq, PQData data);
- 우선순위 큐에 데이터 저장. 매개변수 data로 전달된 값 저장
-
PQData PDequeue(PQueue * ppq);
- 우선순위가 가장 높은 데이터 삭제
- 삭제된 데이터 반환
- 본 함수의 호출을 위해서는 데이터가 하나 이상 존재함이 보장 필요
※ 참고로 힙 기반의 우선순위 큐이기 때문에 아래 파일들과 위에서 구현한 UsefulHeap 헤더파일과 소스파일이 같은 폴더내에 있어야하며 함께 컴파일 해야한다.
2) 헤더파일 정의 (PriorityQueue.h)
#ifndef __PRIORITY_QUEUE_H__
#define __PRIORITY_QUEUE_H
#include "UsefulHeap.h"
typedef Heap PQueue;
typedef HData PQData;
void PQueueInit(PQueue * ppq, PriorityComp pc);
int PQIsEmpty(PQueue * ppq);
void PEnqueue(PQueue * ppq, PQData data);
PQData PDequeue(PQueue * ppq);
#endif3) 소스파일 정의 (PriorityQueue.c)
#include "PriorityQueue.h"
#include "UsefulHeap.h"
void PQueueInit(PQueue * ppq, PriorityComp pc)
{
HeapInit(ppq, pc);
}
int PQIsEmpty(PQueue * ppq)
{
return HIsEmpty(ppq);
}
void PEnqueue(PQueue * ppq, PQData data)
{
HInsert(ppq, data);
}
PQData PDequeue(PQueue * ppq)
{
return HDelete(ppq);
}사실상 다 구현해 놓은 힙을 가져다가 사용하는 것이기 때문에 간단하다.
4) 실행파일 정의 (PriorityQueueMain.c)
#include <stdio.h>
#include "PriorityQueue.h"
int DataPriorityComp(char ch1, char ch2)
{
return ch2-ch1;
}
int main()
{
PQueue pq;
PQueueInit(&pq, DataPriorityComp);
PEnqueue(&pq, 'A');
PEnqueue(&pq, 'B');
PEnqueue(&pq, 'C');
printf("%c \n", PDequeue(&pq));
PEnqueue(&pq, 'A');
PEnqueue(&pq, 'B');
PEnqueue(&pq, 'C');
printf("%c \n", PDequeue(&pq));
while(!PQIsEmpty(&pq))
printf("%c \n", PDequeue(&pq));
return 0;
}
> gcc .\PriorityQueue.c .\PriorityQueueMain.c .\UsefulHeap.c
> .\a.exe
> 출력
A
A
B
B
C
C+) 우선순위 큐의 활용
우선순위 큐를 이용해서 다수의 문자열을 저장하고, 저장된 문자열을 꺼내어 출력하는 프로그램을 작성해보자.
단, 힙에 저장되는 문자열은 길이가 짧을수록 우선순위가 높다고 가정하자.
이 문제를 해결하기 위해서는 우선순위 비교함수를 수정하면 된다.
미리 구현해놓은 UsefulHeap.h, UsefulHeap.c, PriorityQueue.h, PriorityQueue.c 파일을 사용하자.
추가로 우선순위 큐의 저장 대상이 문자열인 관계로 헤더파일 UsefulHeap.h의 typedef 선언을 typedef char HData; → typedef char *HData;로 변경해야 한다.
따라서 변경된 실행파일은 다음과 같다.
// q1.c
#include <stdio.h>
#include <string.h>
#include "PriorityQueue.h"
int DataPriorityComp(char * str1, char * str2)
{
return strlen(str2) - strlen(str1);
}
int main()
{
PQueue pq;
PQueueInit(&pq, DataPriorityComp);
PEnqueue(&pq, "Apple");
PEnqueue(&pq, "Banana");
PEnqueue(&pq, "Cherry");
PEnqueue(&pq, "Grape");
PEnqueue(&pq, "Orange");
PEnqueue(&pq, "Kiwi");
PEnqueue(&pq, "Mango");
PEnqueue(&pq, "Pineapple");
PEnqueue(&pq, "Strawberry");
PEnqueue(&pq, "Watermelon");
while(!PQIsEmpty(&pq))
printf("%s \n", PDequeue(&pq));
return 0;
}
> gcc .\PriorityQueue.c .\q1.c .\UsefulHeap.c
> .\a.exe
> 출력
Kiwi
Grape
Apple
Mango
Banana
Orange
Cherry
Pineapple
Strawberry
Watermelon 여기서 더 develop 시키고 싶다면 데이터를 입력하는 것이 아닌 입력 받아 보는 방법도 있다.
<Review>
드디어 나의 100번째 벨로그다~!
우선순위 큐는 힙을 구현하면 거의 다 구현한 것이기 때문에 힙에 대한 이해가 중요했다.
힙은 트리란 자료구조를 이해해야했고, 트리는 기존에 연결 리스트 기반으로 구현한 방법 이 외에 배열로 구현한 방법에 대한 이해가 필요했다.
앞에 배운 내용을 총망라하여 다뤘다는 느낌을 받았다.
그리고 자료구조를 서로 이용하는데 각 자료구조의 특징을 이용해서 다른 자료구조를 구현한다는 점이 매력적으로 다가왔다.
앞으로 정렬, 탐색, 테이블과 해쉬, 그래프 등이 남았는데 포기하지 말고 앞에 내용을 잘 되새기며 파이썬으로 학습했을 때보다 보다 더 자료구조에 대해, 알고리즘에 대해 이해할 수 있었음 좋겠다.
화이팅~!

