Contextual Embedding과 관련된 모델, 방법론들을 설명해주는 논문입니다. 전체적인 흐름과 발전과정을 따라가기에 적합한 논문입니다.
[Abstract]
ELMo, BERT로 대표되는 Contextual embedding 방법은 Word2Vec과 같은 대표적인 단어 표현방식을 넘어서 자연어 처리의 많은 분야에서 좋은 성능을 보이고 있습니다. Contextual embedding은 문맥을 바탕으로 각각의 단어를 표현하기 때문에 다양한 문맥에서의 단어 활용법과 서로 다른 언어 간에 지식을 전달해줄 수 있습니다. 해당 논문에서는 존재하는 Contextual embedding 모델들을 살펴봅니다.
1. Introduction
매우 큰 크기의 말뭉치에서 비지도 방법을 통해서 학습되는 Distributional word representation은 현대 자연어 처리 시스템에서 널리 사용되고 있습니다. 하지만 이 방법은 각 단어의 문맥을 고려하지 못한 채 하나의 표현 방식밖에 갖지 못합니다. 이런 전통적 방식과 달리 Contextual embedding는 단어 수준의 의미를 넘어서 입력되는 문장 전체의 함수로서 단어를 표현합니다. 문맥 의존적인(context-dependent) 표현 방식은 다양한 언어적 문맥하에서 단어들의 문법적, 의미적 특성을 잡아낼 수 있습니다. 이전 연구들에서 라벨이 붙지 않은 매우 큰 크기의 말뭉치에서 학습된 Contextual embedding은 다양한 자연어 처리 과제에서 뛰어난 성능을 보인다는 사실이 밝혀졌습니다. 더 나아가 많은 연구들에서 Contextual embedding은 언어 간에서 유용하고 서로 전이되는 지식을 학습한다고 알려지게 되었습니다.
2. Token Embeddings
Distriuted representaion은 각각의 token들이 dense feature 벡터 h와 관련이 있습니다. 전통적인 word embedding은 사전의 크기를 행의 개수로 갖고, 벡터의 차원을 열의 개수로 갖는 word embedding matrix(E)를 학습하는 것을 목표로 합니다. E 행렬의 행벡터는 특정 단어의 embedding 결과입니다. Word2Vec과 Glove가 이와 같은 방식을 사용합니다. 반면에, Contextual embedding는 각각의 token들은 입력 문장 전체의 함수입니다. 이러한 context-dependent 표현방식은 문장 단위의 의미를 포착하기에 더욱 적합합니다.
3. Pre-training Methods for Contextual Embeddings
Contextual embedding은 언어모델(language modeling)으로 대표되는 unsupervised 방법과 기계번역(machine translation), 자연어 추론(natural language inference)로 대표되는 supervised 방법으로 나눌 수 있습니다.
3.1 Unsupervised Pre-training via Language Modeling
언어모델은 token들의 sequence의 확률분포입니다.
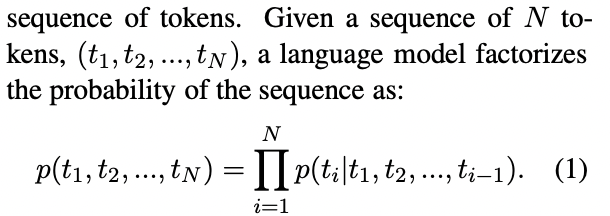
언어모델은 최대우도가능도(MLE)를 사용하며, 때때로 모델의 파라미터를 추정하기 위해 regularization term을 활용하여 페널티를 주기도 합니다. 언어모델은 라벨이 붙지 않은 매우 큰 크기의 말뭉치를 통하여 학습됩니다.
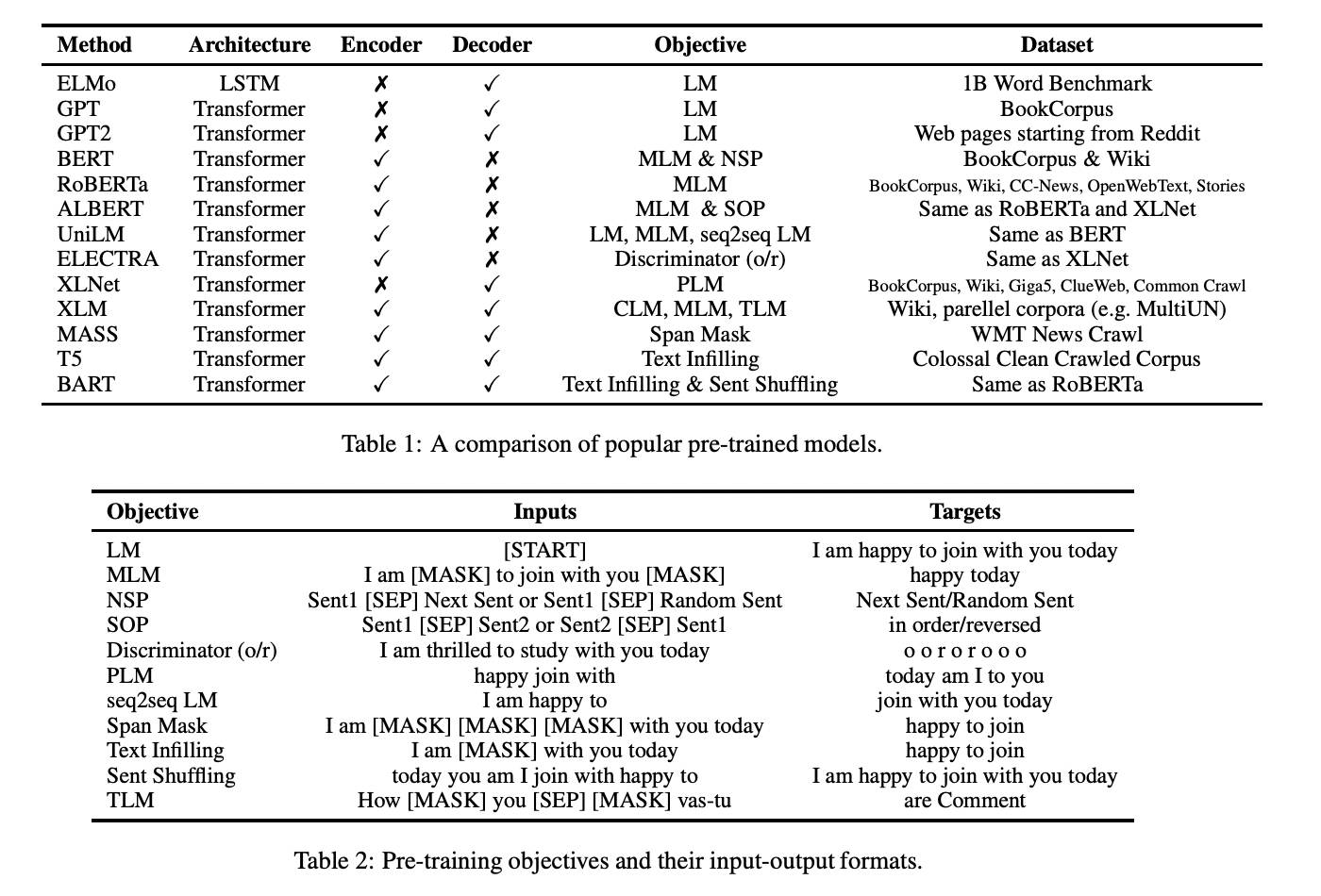
Precursor Models
언어모델을 처음 활용했다고 여겨지는 연구는 recurrent networks와 sequence autoencoder를 함께 사용했습니다. 이 모델이 현대 Contextual embedding 방법의 precursor model로 여겨집니다. 그 후 seq2seq 모델의 성능을 높이기 위해 pre-training 방법이 제안되었습니다. seq2seq의 encoder와 decoder는 두 언어모델의 pre-trained 가중치로 초기화되었습니다.
ELMo
ELMo는 양방향 언어모델을 활용하여 context-dependent representation을 도출하여 전통적인 word embedding 방식을 일반화하였습니다. L개의 층을 가진 정방향 LSTM과 L개의 층을 가진 역방향 LSTM이 각각 왼쪽 문맥, 오른쪽 문맥을 encoding하는 역할을 합니다. 각각의 층에서, 전체 문맥은 왼쪽에서 오른쪽 문맥과 오른쪽에서 왼쪽 문맥을 표현하는 벡터를 이어붙인(concatenate) 벡터를 활용하여 나타냅니다.

pre-trained ELMo가 주어졌을 때, 성능을 높이기 위해 해당 모델을 task-specific 구조에 활용할 수 있습니다.
GPT, GPT2 and Grover
GPT는 2단계의 학습 패러다임을 사용합니다. 첫 번째는 언어 모델을 활용한 비지도 pre-training. 두 번째는 지도 fine-tuning입니다. 다양한 task에서 활용할 수 있는 보편적인 표현방식을 학습하는 것이 목표입니다. GPT는 전반적인 의존도(global dependecies)를 잘 잡아낸다고 알려진 Transformer 구조를 사용합니다.
GPT2는 GPT의 구조를 활용하여 더 크고 다양하며 많은 domain이 포함된 data를 활용하여 학습합니다. 라벨이 없는 매우 큰 크기의 말뭉치를 통해 학습된 언어모델은 질의 응답, 기계 번역, 요약과 같은 일반적인 supervised NLP task의 내용들을 스스로 학습합니다. GPT2는 사용하는 언어사전을 만들기 위해 BPE(Byte Pair Encoding)을 사용하여 text를 분리하기 때문에 GPT2의 좋은 성능이 모델 덕분인지 새로운 input representation 때문인지 밝혀지지는 않았습니다.
Grover는 뉴스 dataset을 만들어내고, 실제처럼 보이는 가짜 뉴스를 만들어내는 언어모델을 학습합니다.
BERT
ELMo는 정방향, 역방향 LSTM을 왼쪽, 오른쪽 문맥의 상호작용을 고려하지 않은 채 이어붙인 표현방식을 사용합니다. GPT와 GPT2는 왼쪽에서 오른쪽 방향의 encoder만 사용하기 때문에 오직 왼쪽에서 오는 문맥만 사용할 수 있습니다. 이와 같은 방식들은 문장 단위 task의 일부에만 잘 작동됩니다. 그렇기 때문에 양방향 문맥을 모두 고려할 수 있는 방법의 중요성이 대두되었습니다.
BERT는 문장의 특정 단어를 masking하고 주변 단어를 통해 masking된 단어를 예측하는 방식을 활용하는 masked 언어모델(MLM) 방식을 제안했습니다. BERT는 pre-training을 하는 동안 양방향 문맥을 포함시키기 위해 Transformer 구조를 적용했습니다. 이 뿐만 아니라 BERT는 두 문장이 주어졌을 때 두 번째 문장이 첫 번째 문장 다음에 오는 것이 맞는지를 판단하는 next-sentence prediction(NSP) 역시 활용하였습니다. NSP task를 통해 질의응답, 자연어추론과 같은 task에 높은 성능을 가질 수 있도록 하였습니다.
BERT variants
BERT의 변형으로 ERNIE, ERNIE2.0, SpanBERT, SturctBERT, RoBERTa, ALBERT 등이 있습니다.
XLNet
XLNet 모델은 BERT의 2가지 단점을 지적했습니다.
첫째, BERT는 token들의 conditional indepedence를 가정하고 있다는 점입니다.
둘째, BERT가 pre-training동안 사용하는 special token들이 실제 data에서는 등장하지 않는다는 점입니다.
XLNet은 새로운 auto-regressiv model을 제안합니다.

UniLM
언어 모델, masked 언어 모델, seq2seq 언어 모델
ELECTA
효율적인 pre-training 방법을 사용합니다.
T5
T5(Text-to-Text Transfer Transformer)는 자연어이해(NLU)와 자연어생성(NLG)를 합치는 방법을 제안합니다.
BART
BART는 MLM을 넘어서는 noise 방법을 사용합니다. 입력값은 임의의 noising function에 의해 오염됩니다. BART는 noising function을 평가합니다.
3.2 Supervised Objectives
컴퓨터 vision 영역에서의 성공에 영감을 받아, 몇몇 연구에서는 transferable representation을 학습하는 NLP task를 진행하였습니다.
CoVe는 기계번역에서 학습한 결과를 다른 곳에 적용할 수 있다는 것을 밝혔습니다. CoVe는 contextual embedding을 얻기 위해 기계번역을 활용하여 학습된 seq2seq 모델의 deep LSTM encoder를 사용합니다.
4. Cross-lingual Polyglot Pre-training for Contextual Embeddings
Cross-lingual polyglot pre-training은 multi-lingual representaion을 영어와 같이 data가 많은 언어에서의 지식을 Romanian과 같이 data가 적은 언어에 전이하기 위해 학습하는 것을 목표로 합니다.
BERT의 저자들은 100개 이상의 언어들의 wiki data를 활용하여 multi-lingual BERT를 개발하였습니다.
5. Downstream Learning
학습이 된다면 contextual embedding은 다양한 분야의 문제를 해결하기 위해 사용될 수 있습니다.
5.1 Ways to User Contextual Embeddings Downstream
Feature-based
Feature-based의 한 예시는 ELMo를 사용하는 것이다. ELMo는 pre-trained contextual embedding 모델의 가중치를 고정시킨 후 internal representation의 선형 결합을 만들어낸다. 이렇게 만들어진 선형 결합 representation은 task-specific 구조의 feature로써 활용된다. feature-based model의 이점은 특정 task에 있어 매우 뛰어난 성능을 갖는다는 것이다.
Fine-tuning
Fine-tuning은 먼저, pre-trained contextual embedding 모델의 가중치로 시작하여 특정 task에 맞추어 약간의 미세 조정을 해준다. 대표적인 방법은 pre-trained model의 가장 위에 새로운 층 하나를 추가하는 것이다.
Adapters
Adapters는 다양한 task learning setting 학습을 위한 pre-trained model의 층 사이에 추가되는 작은 module들이다.
5.2 Countering Catastrophic Forgetting
downstream task를 학습하면 pre-trained model의 정보를 덮어쓰게 되는데 이를 catastrophic forgetting이라고 한다.
Frezzing layers
학습을 하는 특정 층을 제외한 나머지 층을 고정하는 방법을 통해 fine-tuning 동안의 forgetting을 줄일 수 있다.
Adaptive learning rates
pre-trained models의 lower layer가 general한 지식을 포착한다고 알려져 있다. 그렇기 때문에 lower layer를 위해 fine-tuning을 할 때 lower learning rates를 활용한다.
Regularization
Regularization은 fine-tuned parameter를 pre-trained parameter와 근사해지도록 한다.
5.3 Multi-task Fine-tuning
Multi-task learning은 general representation을 얻는다.
6. Model Compression
Low rank approximation
low rank approximation을 학습하는 방법은 full-rank model의 가중치 행렬을 low rank 행렬로 축소시켜 모델 parameter의 효과적인 수를 줄여준다.
Knowledge distillation
konwledge distillation은 teacher network에서 encoded된 지식을 student network에 전달해주는 것을 의미한다.
Weight quantization
quantization 방법은 가중치의 값을 버림 등과 같은 방법을 통해 대략적인 수치로 나타내는 것을 의미한다.
7. Analyzing Contextual Embeddings
Probe classifiers
Visualization
8. Current Challenges
Better pre-training objectives
Understanding the knowledge encoded in pre-trained models
Model robustness
Controlled generation of sequences
