기본적인 Word Embedding과 관련 연구들을 소개하는 Survey 논문 입니다. Word Embedding의 기본이 되는 prediction-based model, count-based model의 개념과 관련 연구들을 파악하기에 적합한 논문입니다.
[Abstract]
해당 논문은 분포 가정(distributional hypothesis) 하에서 단어를 주어진 길이(fixed-length), 밀집(dense) 표현방식을 만들어내는 방법에 관해 다룹니다. 위와 같은 방식을 Word embeddings 라고 부릅니다. 더 나아가 단어를 구조적, 의미적으로 잘 표현할 수 있는 방법을 사용한다면 다양한 NLP 작업들에서 유용하다는 것이 밝혀졌습니다.
1. Introduction
단어 혹은 문서를 표현하는 task는 NLP(자연어 처리) task에서 전부라고는 할 수 없지만 특정 부분을 차지합니다. 일반적으로, 단어나 문서를 벡터로 표현하게 된다면 직관적으로 해석하기 쉬워지며, 덧셈, 뺄셈, 거리 측정과 같은 계산이 가능해지고, 많은 ML 알고리즘에 사용할 수 있기 때문에 유용하다고 알려져 있습니다.
Vector Space Model(VSM)은 단어와 문서를 벡터로 embedding 하는 성공적이고 효과적인 방법으로 알려져 있습니다.
또 다른 방식으로는 Language model을 활용하는 것입니다. Language model은 언어 사용의 statistical model로 볼 수 있습니다. 주로 이전 단어를 통해 다음 단어 예측하는 방식을 활용합니다.
Vector Space Model과 Language model은 각각 독립적이라고 생각할 수 있겠지만 최근 연구들에서는 위 둘을 신경망을 활용해 큰 크기의 language model을 만드는 Neural Network Language Models(NNLMs)로 묶어 설명합니다.
위의 아이디어를 통해 비지도 학습 문제를 해결할 수 있게되어 널리 알려지게 되었습니다. 핵심적인 아이디어는 신경망의 다른 층에 feed 하기 전에 embedding layer 에 단어를 어떻게 사영시킬 것인지에 대한 방법입니다. 유명해진 또 다른 이유 중 하나는 차원의 저주를 완화시키고 일반화에 도움을 줄 수 있었기때문입니다.
Word embedding은 그 자체만으로 NLP 연구 주제 중 하나로 다뤄지게 되었습니다. 최근들어서는 embedding을 위해 신경망이나 embedding layer에 의존하는 것이 아닌 단어의 벡터 표현을 위해 word-context matrix를 활용하기도 합니다.
결국 두 종류의 방법 모두 공통적으로 유사한 의미를 가진 단어는 유사하게 표현되어야 한다고 했습니다. 이러한 가정을 Distributional hypothesis라고 합니다.
Word embeddingds are dense, distributed, fixed-length word vectors, built using word co-occurence statistics as per the distributional hypothesis
신경망을 활용하는 embedding model은 문맥을 통해 단어를 예측하는 방식을 활용하기 때문에 prediction-based 모델이라고 불리며, 단어들이 함께 등장하는 횟수를 포함하는 행렬 기반의 방식을 활용하는 모델을 count-based 모델이라고 합니다.
2. Background: The Vector Space Model and Statistical Language Modelling
word embedding의 등장과 발전을 제대로 이해하기 위해서는 vector space model과 statistical modelling을 제대로 이해해야 합니다.
2.1 The Vector Space Model
Text data를 분석 방법에 적용할 때 직면하는 첫번째 문제는 유사도와 같은 계산을 위해 어떻게 text data를 표현하는 방식과 관련된 것이다. Information Retrieval(IR) 분야에서는 문서들의 집합에서 각각의 문서들은 t-dimensioanl 벡터로 표현되고 벡터의 원소들은 문서 내의 단어들을 의미합니다. 이러한 vector space 를 통해 문서 내적과 같은 방식들 활용하여 벡터들간의 유사도를 계산하는 것들이 가능해졌습니다.
2.2 Statistical Language Modelling
Statistical language modelling은 단어 분포들의 확률적인 모델입니다. 예를들면 직전 단어가 주어졌을 때 다음에 나올 단어의 likelihood를 계산하기 위해 활용될 수 있습니다.

모든 단어들을 사용해서 계산을 하게 된다면 비용이 너무 많이 들기 때문에 주변 n개의 단어만을 활용하여 계산을 하는 방식을 사용합니다. 주변 몇개의 단어로 이루어진 문맥이 주어진다면 해당 문맥 다음에 등장하는 단어는 MLE를 계산하여 예측하게 됩니다.
3. Word Embeddings
Word embedding은 단어를 주어진 길이의 벡터로 표현하는 방식을 의미합니다. Word embedding을 학습하는 다양한 방식들이 존재합니다. Word embedding은 크게 앞서 설명한 신경망을 활용하는 prediction-based 모델을 활용하거나 빈도수를 활용하는 count-based 모델을 활용하는 2가지로 나눌 수 있습니다.
3.1 Prediction-based Models
Prediction-based model은 neural language model(NNLM) 발전과 관계가 깊습니다. Word embedding은 단지 embedding layer라고 불리는 첫번째 layer에 단어를 사영시키는 것입니다.
Prediction-based 모델의 역사는 아래의 표를 참고하면 됩니다.
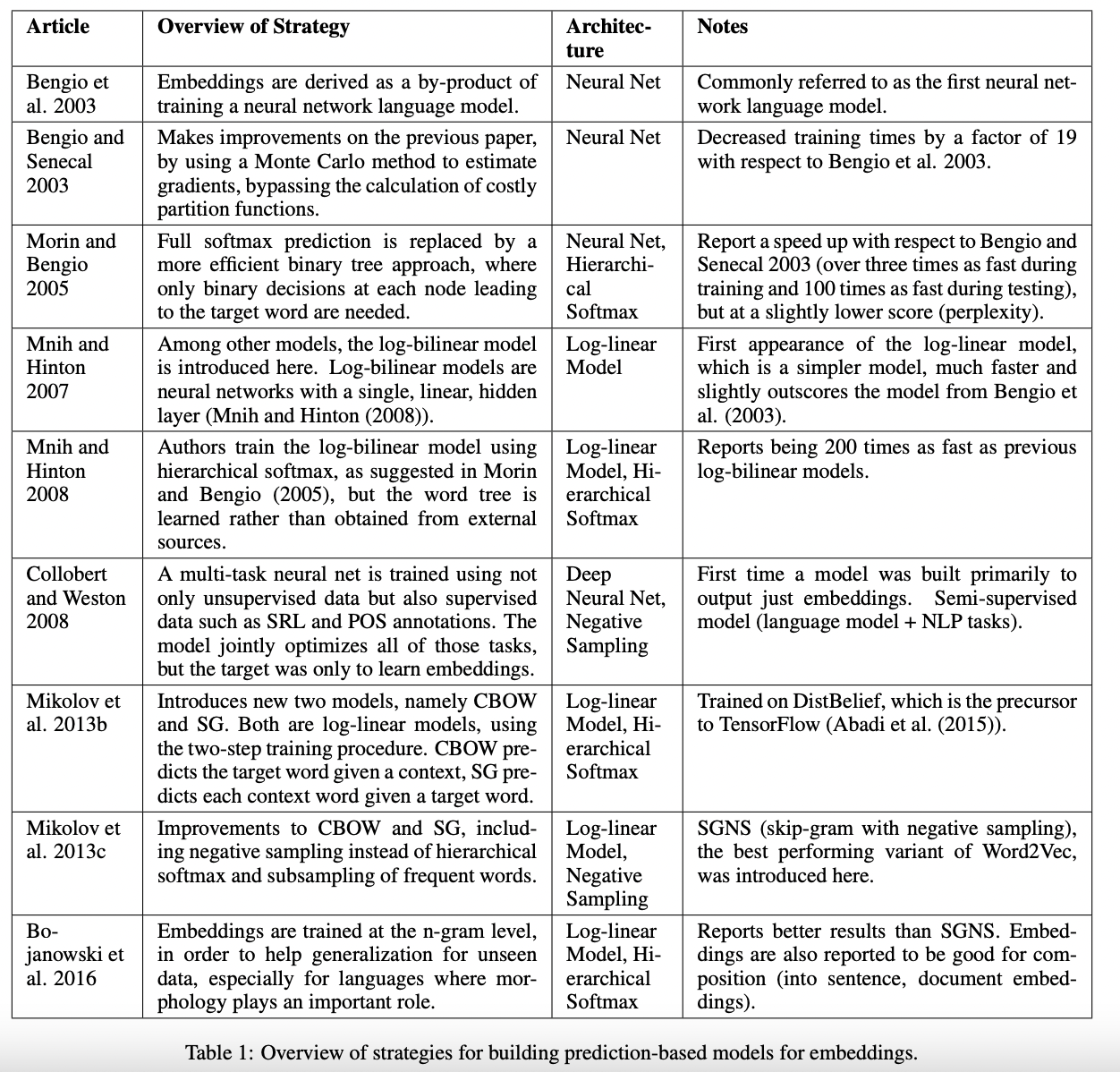
위의 방법들 중 Word2Vec으로 잘 알려진 CBOW(Continuous bag of words),Skip-gram 2가지와 skip-gram 모델에서 더 나아간 FastText 정도는 깊게 공부해볼 필요가 있습니다.
3.2 Count-based Models
Count-based 모델은 word embedding을 만들어내기 위해 다음 단어를 예측하는 알고리즘을 학습하는 것이 아닌 말뭉치 내에서 단어의 동시등장 횟수와 같은 counts 정보를 사용합니다.
Count-based 모델의 역사는 아래의 표를 참고하면 됩니다.
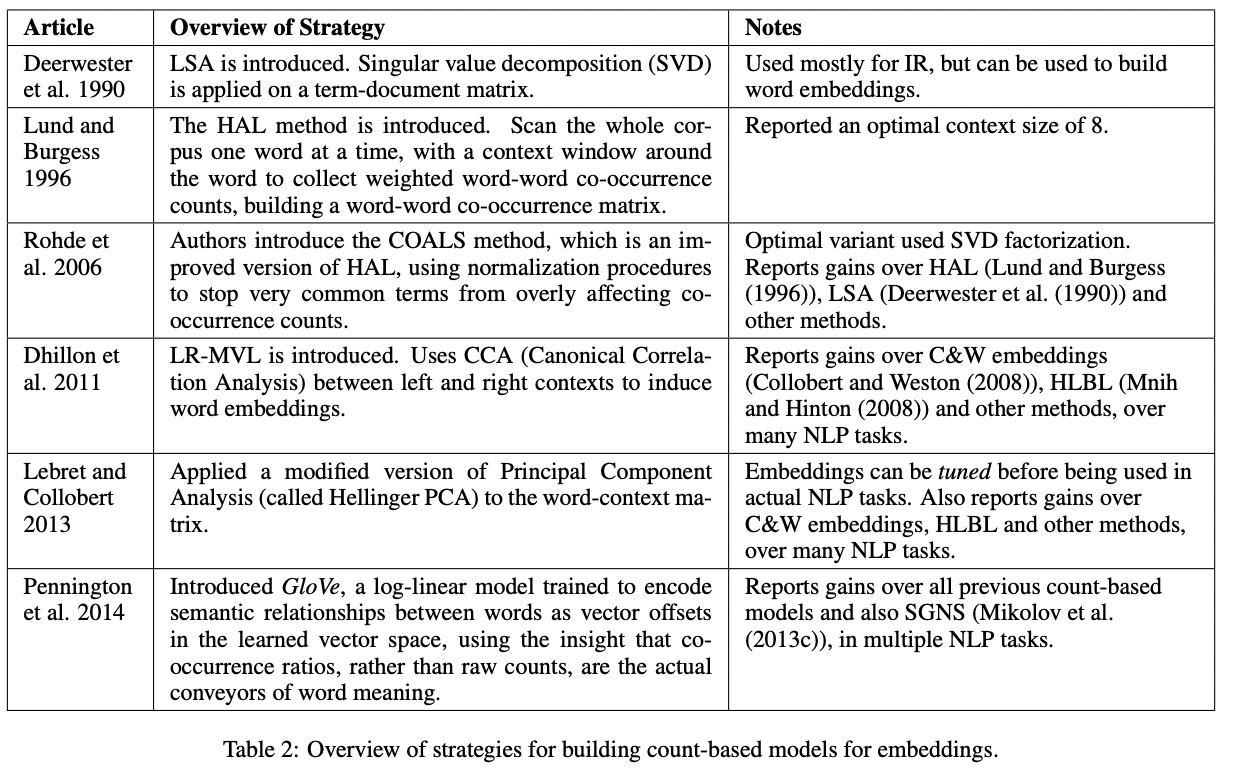
위의 방법들 중 Glove로 잘 알려진 방법은 깊게 공부해볼 필요가 있습니다.
4. Conclusion
Word embedding은 다양한 NLP task에서 유용하다고 밝혀졌습니다. 해당 논문에서는 Word embedding을 위해 사용되는 다음 단어를 예측하는 방식을 사용하는 prediction-based 모델과 단어 간의 동시등장 통계량을 활용하는 count-based 모델 2가지 모델의 개요와 관련 연구들을 소개했습니다.
Word2Vec, gensim, FastText, Glove와 관련 내용들은 자주 사용되기 때문에 깊게 공부해봐도 좋은 주제들입니다.
