LSTM과 GRU보다 나은 성능을 보이는 architecture를 찾으며, LSTM의 각 gate들의 중요도를 평가하고 LSTM의 forget gate bias로 1을 사용할 때 LSTM의 성능이 향상됨을 보이는 논문입니다.
[Abstarct]
RNN(Recurrent Neural Network)는 때로 학습하기에는 어렵지만 매우 강력한 sequence model입니다. LSTM(Long Short-Term Memory)는 수월한 학습을 위한 RNN architecture의 특별한 버전입니다. LSTM architecture는 ad-hoc으로 보여 해당 구조가 정말 최적인지 LSTM의 개별 component들이 정말 중요한지 명확하지 않습니다.
해당 논문에서는 LSTM architecture가 정말 최적인지 아니면 더 나은 architecture가 있는지 확인합니다. 해당 논문에서는 architecture search를 수행하며 LSTM과 GRU(Gated Recurrent Unit)보다 몇몇 task에서 더 나은 성능을 보이는 architecture를 찾았습니다. 또한, 해당 논문에서는 LSTM의 forget gate에 bias로 1을 더해주었을 때, LSTM과 GRU 간의 성능 차이를 줄일 수 있다는 것을 발견하였습니다.
1. Introduction
DNN(Deep Nueral Network)는 복잡한 vector-to-vector mapping을 학습할 수 있는 강력한 expressive model입니다. RNN은 sequence data에 특화된 DNN이며 따라서 RNN 역시 매우 강력한 expressiv model입니다. RNN은 각 timestep마다 activation vector를 보존합니다. RNN의 깊이가 깊어짐에 따라 exploding and vanishing gradient 문제가 발생하여 RNN 학습을 어렵게 만듭니다.
Vanishing gradients는 LSTM을 통해 해결할 수 있습니다. LSTM은 사용하기 쉬워 vanishing gradient 문제를 해결하는 일반적인 방법이 되었습니다. Vanishing gradient 문제를 해결할 수 있는 또 다른 방법은 second-order optimization algorithm을 사용하여 RNN의 가중치에 제한을 걸어 gradient가 vanishing되는 것을 방지합니다. 또는 recurrent weight가 동시에 학습되는 걸 포기하거나 RNN parameter의 초기값 설정에 공을 들입니다. Vanishing gradient 문제에비해 exploding gradient 문제는 gradient의 norm에 강력한 제한사항을 걸어 좀 더 쉽게 해결할 수 있다고 알려져있습니다.
LSTM의 주된 비판점은 ad-hoc이고 목적이 불분명한 많은 수의 component들이 있다는 점입니다. 결과적으로 LSTM이 정말 최적의 architecture인지 혹은 더 나은 architecture가 존재하는지 불분명합니다.
이런 비판에 영감을 받아, 해당 논문에서는 LSTM이 정말 최적인지 architecture search 방법을 활용하여 발견합니다. 해당 논문에서는 GRU와 유사한 구조를 갖고서 LSTM과 GRU보다 대부분의 task에서 좋은 성능을 보인 architecture를 발견하였습니다. 이뿐만 아니라, LSTM의 forget gate에 bias 1를 더해주는 방법을 통해 LSTM과 더 나은 architecture 사이의 성능 차이를 줄일 수 있었습니다. 따라서 해당 논문에서는 복잡한 방식을 사용하는 것보다 먼저 forget gate의 bias 값을 늘리는 것을 추천합니다.
이 뿐만 아니라 해당 논문에서는 LSTM의 많은 component들의 중요도를 측정하였습니다. Input gate는 중요하며, output gate는 중요도가 떨어지고 forget gate는 language modeling을 제외한 모든 문제에서 가장 중요한 역할을 하였습니다.
2. Long Short-Term Memory
일반 RNN은 exploding and vanishing gradinet 문제를 갖고 있습니다. 두 문제 모두 RNN의 반복 특성때문에 발생합니다.
Exploding gradient 문제는 gradient의 norm값이 특정 기준치를 넘을 때 gradient를 shrinking해주는 gradient clipping을 활용하여 상대적으로 쉽게 해결할 수 있습니다.
Vanishing gradient 문제는 gardient 값 자체가 작아지지 않기 때문에 해결하기가 까다롭습니다. 하지만 gradient가 long-term 방향일 때 매우 작아지고 short-term일 때는 큽니다. 결과적으로 RNN은 short-term에서는 쉽게 학습할 수 있지만 long-term에 대해서는 제대로 학습하지 못하게 됩니다.
LSTM은 RNN을 reparameterizing하여 vanishing gradient 문제를 다룹니다. LSTM은 representational 이점을 가지고 있지 않지만 gradient는 vanishing하지 않습니다. RNN architecture의 hidden state를 St라고 합시다. LSTM의 주된 아이디어는 S(t-1)로부터 St를 구하는 것이 아닌 S_t를 S(t-1)에서 delta(S(t))를 더해 구합니다. S_t를 구하는 방식에 있어서 큰 차이점이 있는 것은 아니지만 delta(S(t))를 구하여 더해주는 방식이 gradient가 vanishing하지 않았습니다.
Full LSTM의 정의는 delta(S_(t))를 계산하는 circuitry과 S_t로부터 정보를 decoding하는 circuitry를 포함합니다. 해당 논문에서는 아래 식과 같이 LSTM architecture를 정의하여 사용합니다.

LSTM의 hidden state는 concatenation (h_t, c_t)입니다. c_t는 slow state로 vanishing gradient 문제를 해결하기 위해 사용되고, h_t는 fast state로 LSTM이 짧은 기간 안에 복잡한 결정을 내릴수 있도록 해줍니다. n memory cell을 가진 LSTM은 2n 차원의 hidden state를 가진다고 생각할 수 있습니다.
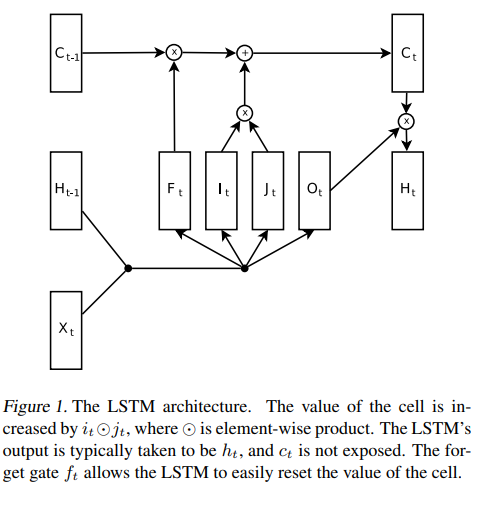
2.1 Arguments Against Attractors
RNN의 state는 information을 stable attractor를 통해 저장합니다. Attractor view는 RNN이 정해지지 않은 시간동안 information을 저장할 수 있도록하기 때문에 매력적으로 보입니다. 이는 information processing system에서 매우 필수적인 특징이기 때문입니다.
(Bengio et al., 1994)에서는 stable attractor에 information을 저장하는 RNN은 반드시 vanishing gradient 문제를 보이게 된다고 하였습니다. (Bengio et al., 1994)의 Theorem 4는 model architecture의 가정을 하고 있지 않기 때문에 LSTM 역시 attractor를 통해 information을 저장한다면 vanishing gradient 문제가 일어났어야 합니다. 하지만 LSTM은 이런 문제를 갖고 있지 않기 때문에 LSTM은 attractor-based memory system 이라고 볼 수 없습니다.
2.2 Forget Gates Bias
LSTM에 관해 이야기를 할 때 거의 언급되지 않는 증요한 기술적 detail은 forget gate bias b_f의 초기화에 관한 내용입니다. 일반적으로 forget gate는 0.5로 초기화됩니다. 이는 매 timestep마다 0.5 factor로 vanishing gradient를 일으키며 long term dependency가 심할 때 문제가 발생하게 됩니다.
이와 같은 문제는 forget gates b_f를 1과 2와 같은 좀 더 큰 값으로 초기화하여 해결할 수 있습니다. 1에 유사한 값으로 forget gate가 초기화되면 gradient flow가 가능해집니다.
만약 forget gate bias가 제대로 초기화되지 않는다면 LSTM이 long-range dependency 문제를 해결하기에 적절하지 않다는 잘못된 결론을 내리게 됩니다.
2.3 LSTM Alternatives
LSTM의 cell은 vanishing gradient 문제를 막아주는 역할에 필수적입니다. 하지만 LSTM은 정당화하기 힘든 너무 많은 component들이 있고, 좋은 결과를 위해 이들을 반드시 필요로 하지 않을 수도 있습니다.
(Cho et al., 2014)에서 GRU를 소개하였고, GRU는 특정 task에서 LSTM보다 나은 성능을 보인다고 (Chung et al., 2014)에서 소개되었습니다. GRU는 아래 식과 같이 정의됩니다.

해당 논문에서는 GRU와 LSTM, 그들의 변형을 비교하고 GRU가 LSTM보다 단순한 초기화 과정이 있었을 때는 language modeling을 제외한 모든 task에서 더 좋은 성능을 갖는다는 것을 찾았습니다. 하지만 LSTM의 forget gate의 bias를 1로 설정하였을 때 LSTM과 GRU의 성능 차이는 거의 없었습니다.
3. Methods
해당 논문의 주된 실험은 extensive architecture search입니다. 해당 논문의 목표는 3가지 task에서 LSTM보다 더 나은 성능을 갖는 single architecture를 찾는 것입니다. 해당 논문에서는 LSTM보다 모든 task에서 더 나은 성능을 갖는 architecture를 찾는 것에 성공하였습니다. 해당 모델은 GRU보다 모든 task에서 근소한 성능 우위를 보였습니다. GRU보다 더 큰 성능 우위를 위해서는 task마다 다른 architecture를 사용해야만 했습니다.
3.1 The Search Procedure
100개의 best architecture들을 유지하고 각 architecture마다 현재 상태에서 최상의 성능을 보일 수 있는 hyperparameter setting에서 성능을 측정합니다. top-100 list는 오직 LSTM과 GRU로 initialize됩니다.


3.2 Mutation Generation
Candidate architecture는 computation graph로 표현됩니다. 각 layer들은 node로 표현되고 모든 node들은 동일한 차원을 갖습니다. 각 architecture들은 M+1 node들을 input으로 받고 M node들을 output으로 갖습니다. 따라서 앞의 M개의 input은 RNN의 hidden state이고 M+1번째 input은 RNN의 external input입니다. LSTM architecture는 (x, h, c) 3개의 input을 받고 (h, c) 2개의 output을 갖습니다.
해당 논문에서는 0과 1 사이에서 uniformly하게 확률 p를 뽑아 주어진 architecture를 변형시키고 graph의 각 node에 확률 p로 선택된 transformation을 독립적으로 적용합니다. p 값은 변형시키는 정도를 결정합니다. 이 방법으로 변형의 대부분은 작지만 일부는 매우 크게 변형됩니다.


3.3 Hyperparameter Selection for New Architecture
만약 parent architecture가 420개 이상의 서로 다른 hyperparameter가 있다면, child의 hyperparameter의 80%는 parent의 best 100 hyperparameter setting에서 오고 나머지 20%는 임의로 생성됩니다. 만약 parenet architecture가 420개 미만의 hyperparameter를 갖는다면 33%는 임의로 만들어지고 33%는 LSTM과 GRU의 best 100 hyperparameter setting에서 오고 나머지 33%는 parent architecture에서 옵니다.
3.4 Some statistics
- 10,000 different architectures
- 각 architecture들은 평균 220개의 hyperparameter setting에서 평가를 수행. 이는 모든 architecture들이 가장 좋은 성능을 보일 충분한 기회를 제공받았다고 생각할 수 있습니다.
3.5 The problems
해당 논문에서는 아래 3개의 task에서 좋은 성능을 보이는 architecture를 찾습니다.
- Arithmetic : 2개의 숫자의 합이나 차를 구합니다.
- XML modeling : synthetic XML dataset의 다음 문자를 예측합니다.
- Peen Tree-Bank(PTB) : 단어 수준의 language modeling task
일반화 정도를 측정하기 위해 Music task 역시 수행해줍니다.
minibatch size는 20을 사용하고 unrolled RNN은 35 timestep을 갖습니다.
3.6 The RNN Training Procedure
모델들은 고정된 learning rate로 학습되고 validation error가 증가하지 않는다면 constant factor를 활용하여 learning rate를 줄입니다.




3.7 Hyperparameter Ranges
- Initialization scale : {0.3, 0.7, 1, 1.4, 2, 2.8}
- Learning rate : {0.1, 0.2, 0.3, 0.5, 1, 2, 5}
- Maximal permissible norm of the gradient : {1, 2.5, 5, 10, 20}
- Number of layers : {1, 2, 3, 4}
4. Results
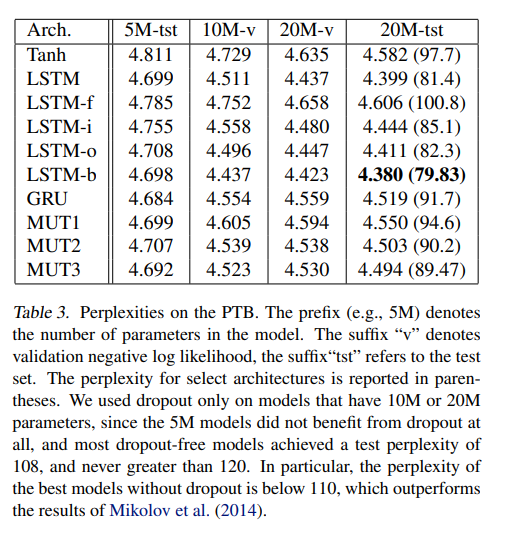
해당 논문에서는 아래와 같이 3가지 best architecture를 제안했습니다.

- GRU는 language modeling을 제외한 모든 task에서 LSTM보다 성능이 좋습니다.
- MUT1은 GRU와 language modeling에서는 성능이 비슷하지만 다른 task에서는 성능을 뛰어넘었습니다.
- LSTM은 dropout을 사용하였을 때 PTB language modeling task에서 가장 좋은 성능을 보였습니다.
- LSTM의 forget bias를 사용하였을 때 일반 LSTM과 GRU보다 모든 task에서 좋은 성능을 보였습니다.
- MUT1이 2개의 music dataset에서 가장 좋은 성능을 보였지만 dropout이 사용되었을 때는 LSTM-i와 LSTM-o가 가장 좋은 성능을 보였습니다.
해당 논문의 결과는 LSTM gate의 중요성을 보였습니다. Forget gate는 가장 중요도가 높았습니다. Foreget gate를 없앴을 때 LSTM은 ARITH와 XML task에서 눈에 띄게 성능 저하가 있었습니다. 하지만 language modeling에서는 그렇지 않았습니다. 2번째로 중요한 gate는 input gate였습니다. Output gate는 LSTM의 성능에서 가장 덜 중요했습니다.
하지만 가장 중요한 것은 forget gate의 적당히 큰 bias 값을 더해주었을 때 LSTM의 성능을 쉽게 향상시킬 수 있었다는 점입니다. 따라서 LSTM을 수행하는 모든 단계에서 forget gate bias로 큰 값을 더하는 것을 추천합니다.
5. Discussion and Related Work
(Bayer et al., 2009)에서 RNN의 Architecture search를 수행하였었습니다. (Bayer et al., 2009)에서는 동일한 문제를 다루었지만 매우 적은 실험만 수행하였고 5 unit의 작은 모델을 대상으로 하였습니다. (Bayer et al., 2009)에서는 synthetic problems with long term dependency만 고려하였고 해당 task에서 LSTM보다 나은 성능을 갖는 architecture를 찾을 뿐이었습니다.
해당 논문에서는 다양한 RNN 변형 architecture들을 평가하여 LSTM보다 늘 좋은 성능을 갖는 architecture를 찾고자 했습니다. LSTM보다 몇 task에서는 나은 성능을 갖는 architecture를 찾을 수는 있었지만 모든 실험 조건에서 LSTM과 GRU보다 나은 architecture를 찾을 수는 없었습니다.
해당 논문에서는 LSTM, GRU와는 획기적으로 다른 architecture를 찾을 수는 없었습니다. 좋은 성능을 보이는 3개의 모델 역시 GRU와 매우 유사했습니다. 더 다양한 architecture를 찾기 위해 더 많은 search procedure를 수행할 수는 있지만 비용이 많이 들어 효용이 떨어집니다.
중요하게는 LSTM의 forget gate bias로 크기 1을 활용함으로써 LSTM의 성능을 쉽게 높일 수 있었습니다. 따라서 해당 논문에서는 LSTM을 적용하는 모든 순간에 forget gate의 bias로 1을 사용하는 것을 추천합니다.
