한국어 자연어 처리를 위해 사용할 수 있는 Tokenization 전략들을 소개하고 기계 번역, NLU task에 다양한 tokenization을 사용한 결과를 비교하여 가장 좋은 성능을 보이는 tokenization을 확인하는 논문입니다.
[Abstract]
Tokenization은 자연어처리 task의 대다수에서 시작을 담당합니다. token은 text의 문맥 정보를 담고있는 최소단위이기 때문에, token을 어떻게 정의하는 방법에따라 model의 성능에 영향을 줍니다.
Byte Pair Encoding(BPE)는 간편함과 보편성덕분에 tokenization 방법의 대표격으로 사용되고 있지만, BPE가 모든 언어와 task에 가장 최선의 방법인가에 대한 의문이 있습니다. 해당 논문은 한국어 자연어처리 task에 있어서 가장 좋은 성능을 보이는 tokenization 전략이 무엇인지 찾는 것을 목표로 합니다.
실험결과를 통해 BPE를 뒤에 형태학적(morphological) segmentation을 적용하는 hybrid 방법론이 영/한, 한/영 기계번역 task와 NLU task에서 가장 좋은 성능을 보이는 것을 밝혔습니다.
1. Introduction
Tokenization은 대다수의 자연어처리에서 첫 단계입니다. 많은 연구를 통해서 다양한 NLP task의 좋은 성능을 보이는 tokenization을 찾기 위한 노력이 있었습니다. 최근 몇 년간, BPE는 tokenization의 대표격이 되었습니다. BPE는 기계번역 task에 있어서 좋은 성능을 보였을뿐만 아니라, BPE는 data-driven statistical 알고리즘이기 때문에 언어에 의존적이지 않기 때문에 유명세를 얻게 되었습니다. 하지만 여전히 BPE가 task에 관계없이, 모든 언어에 가장 좋은 성능을 보이는가에 대한 의문이 존재합니다. 해당 논문은 한국어 자연어처리를 위한 다양한 tokenization에 대한 연구입니다. 한/영 번역, 영/한 번역, NLU, NLI, 감성분석 등과 같은 다양한 task를 통해 한국어에서 가장 좋은 성능을 보이는 tokenization을 찾는 실험을 합니다.
2. Background
2.1 MeCab-ko: A Korean Morphological Analyzer
MeCab은 Conditional Random Fields(CRF)를 기반으로 하는 오픈소스 morphological 분석기입니다. MeCab은 일본어 분석을 위해 만들어졌지만 다른 언어들에서도 사용되고 있습니다. MeCab의 한국어 버전인 MeCab-ko는 일본어와 한국어의 morphology와 문법 차원에서 유사도가 높기 때문에 쉽게 만들어질 수 있었습니다. MeCab-ko는 세종 말뭉치를 통해 학습되었습니다.
2.2 Byte Pair Encoding
Byte Pair Encoding(BPE)는 text에서 자주 등장하는 byte들의 쌍을 순차적으로 하나 혹은 사용되지 않는 byte들로 치환하며 data를 압축하는 방법입니다. BPE는 신경망 기계 번역에서 좋은 성능을 보였으며, 그 덕분에 tokenization의 표준으로 유명세를 얻게 되었습니다.
한국어에서도 BPE는 널리 사용되었으며, 한국어 언어모델(ex. KoBERT)에서도 학습 text를 tokenize하기 위해 BPE를 사용합니다.
3. Related Work
몇몇 논문에서 linguistically informed segmentaion과 BPE나 unigram language modeling과 같은 data-driven 방법을 혼합하여 사용하는 것이 non-English 언어에서 가장 좋은 성능을 보인다고 주장했습니다. 해당 논문과 가장 유사한 다른 논문과의 차이는 타 논문은 신경망 기계 번역을 위한 전처리 기술에 집중을 했다면 해당 논문은 tokenization 전략 자체에 집중을 하고 있다는 점입니다.
4. Tokenization Strategies
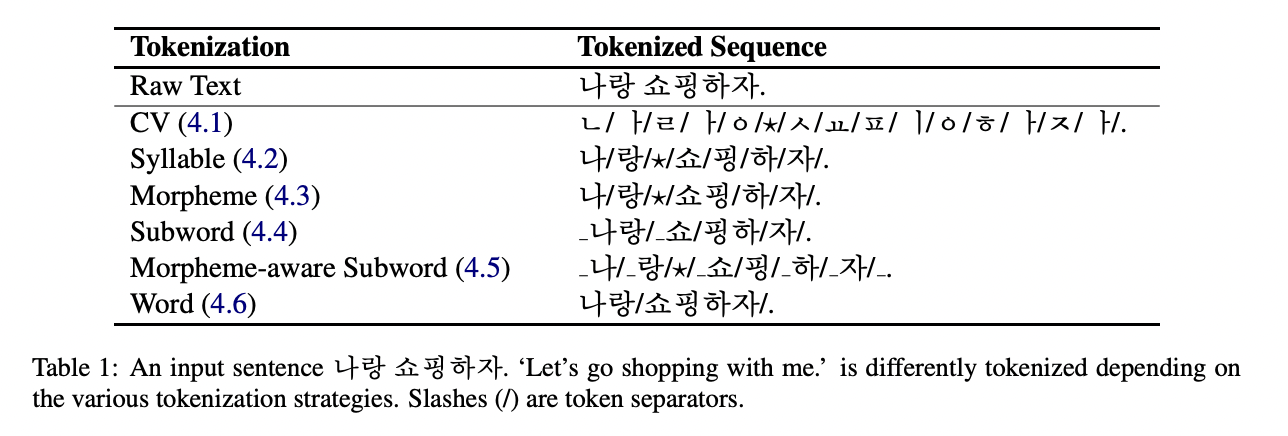
한국어 tokenization 전략을 단위가 작은 순서대로 소개합니다.
4.1 Consonant and Vowel(CV)
한국어는 자음과 모음(자모)으로 음절을 만듭니다. 한국어에 익숙하지 않은 독자를 위해 음절을 분자에 자모를 원자에 비유하여 자모와 음절의 차이를 설명합니다.
4.2 Syllable
문장을 음절 단위로도 tokenize할 수 있습니다.
4.3 Morpheme
문장을 형태소 단위로 tokenize하게 되면 원본 text로 복원이 불가능한 경우가 발생합니다.
4.4 Subword
SentencePiece를 사용하면 BPE를 적용할 수 있습니다. 그러면 문장을 subword 단위로 tokenize할 수 있습니다.
4.5 Morpheme-aware Subword
data-driven 방식과 linguistically-driven 방식을 혼합하여 사용하는 방법에서 착안하여 MeCab-ko와 BPE를 순서대로 적용하여 형태소 정보를 포함하는 subword로 tokenize할 수 있습니다. 형태소로 이미 분리된 input text를 BPE에 적용하기 때문에 다수의 형태소에 걸쳐져 있는 token이 생기는 경우가 없어집니다.
4.6 Word
공백 단위로 text를 나누어 간단히 단어 기준으로 tokenize 할 수 있습니다.
5. Experiments
5.1 Korean to/from English Machine Translation
5.1.1 Dataset
한영 기계 번역을 위한 오픈소스 benchmark dataset은 거의 존재하지 않습니다. 해당 논문에서는 AI Hub에서 공개한 뉴스 data 800K개의 문장을 train/dev/test로 나누어 사용합니다.
5.1.2 BPE Modeling
학습 전에 BPE 학습을 위해 사용할 dataset을 결정하기 위해 사전 실험을 진행했습니다.
AI Hub에서 제공하는 dataset과 Wiki와 같은 대용량의 오픈 소스 text 2가지 선택지가 있습니다. AI Hub 학습 data는 크기는 작지만 test data와 출처가 동일하기 때문에 lexical distribution이 test data와 유사하다는 장점이 있습니다. Wiki 학습 data는 크기는 크지만 뉴스 data가 아니기 때문에 AI Hub data에 적용하기에는 무리가 있습니다.
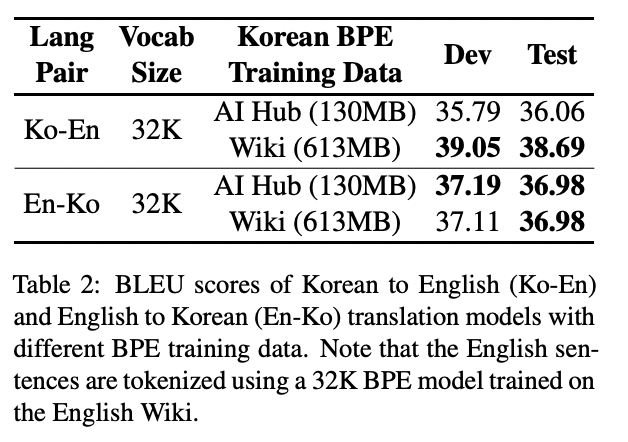
해당 실험결과를 바탕으로 Wiki-based BPE 모델을 사용하기로 결정합니다.
5.1.3 Training
Section 4에서 소개한 다양한 tokenization 전략들을 AI Hub 뉴스 dataset을 활용하여 test합니다.
5.1.4 Results
training 단계가 끝나면, 결과가 가장 좋은 것을 찾기 위해 각 모델의 saved checkpoint를 활용하여 dev set에 적용하여 평가를 진행합니다.
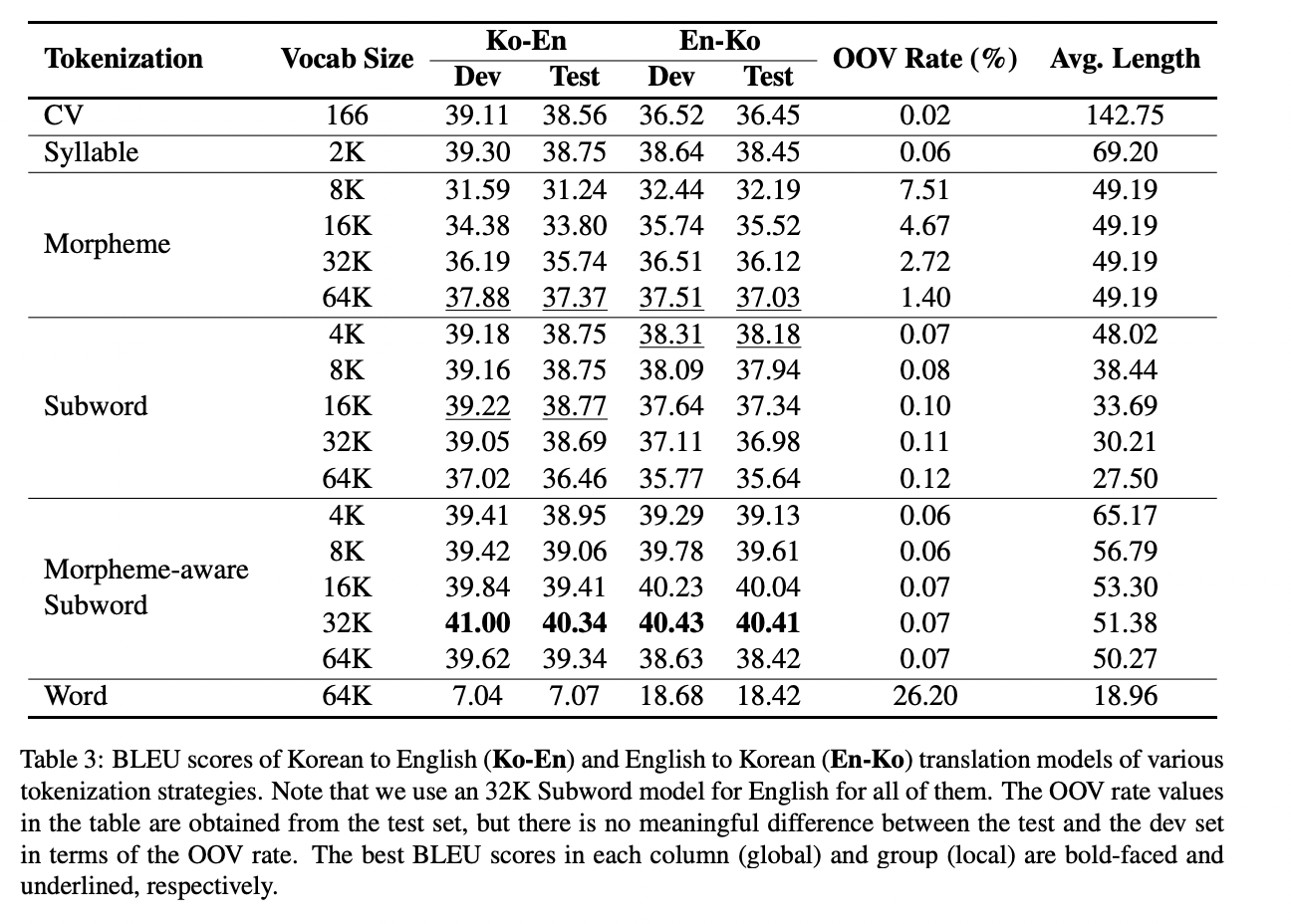
subword 모델과 syllable 모델 모두 morpheme 모델이나 word 모델보다 높은 성능을 보였습니다. 마찬 가지로 OOV rate 역시 subword 모델과 syllable 모델에서 낮은 값을 보였습니다. BPE가 자주 등장하지 않는 단어를 subword로 나눈 반면에 MeCab-ko는 언어적 지식을 기반으로 단어를 나눕니다. CV model은 사전의 크기가 tiny해서 낮은 OOV rate를 보였습니다. 하지만 subword 모델이나 syllable 모델만큼의 성능은 보여주지 못했습니다. Morpheme-aware subword 모델은 가장 좋은 결과를 보였습니다.
요약하자면, 한국어 기계 번역에서는 언어적 지식과 통계적 정보를 모두 활용하는 morpheme-aware subword tokenization이 가장 좋은 성능을 보였습니다.
5.2 Korean Natural Language Understanding Tasks
다양한 tokenization 전략을 활용하여 BERT 모델을 pre-train한 후 5개의 한국어 NLU task에 fine-tune 합니다.
5.2.1 Machine Reading Comprehension: KorQuAD 1.0 Dataset
한국어 reading comprehension dataset입니다.
5.2.2 Natural Language Inference: KorNLI Dataset
한국어 NLI dataset입니다.
5.2.3 Semantic Textual Similarity: KorSTS Dataset
한국어 STS dataset입니다.
5.2.4 Sentiment Analysis: NSMC Dataset
네이버 영화에서 수집된 영화 리뷰 dataset으로 감성분석에 활용됩니다.
5.2.5 Paraphrase Identification: PAWS-X Dataset
한국어를 포함한 6개 언어들의 paraphrase identification을 파악하기 위한 dataset입니다.
5.2.6 Results
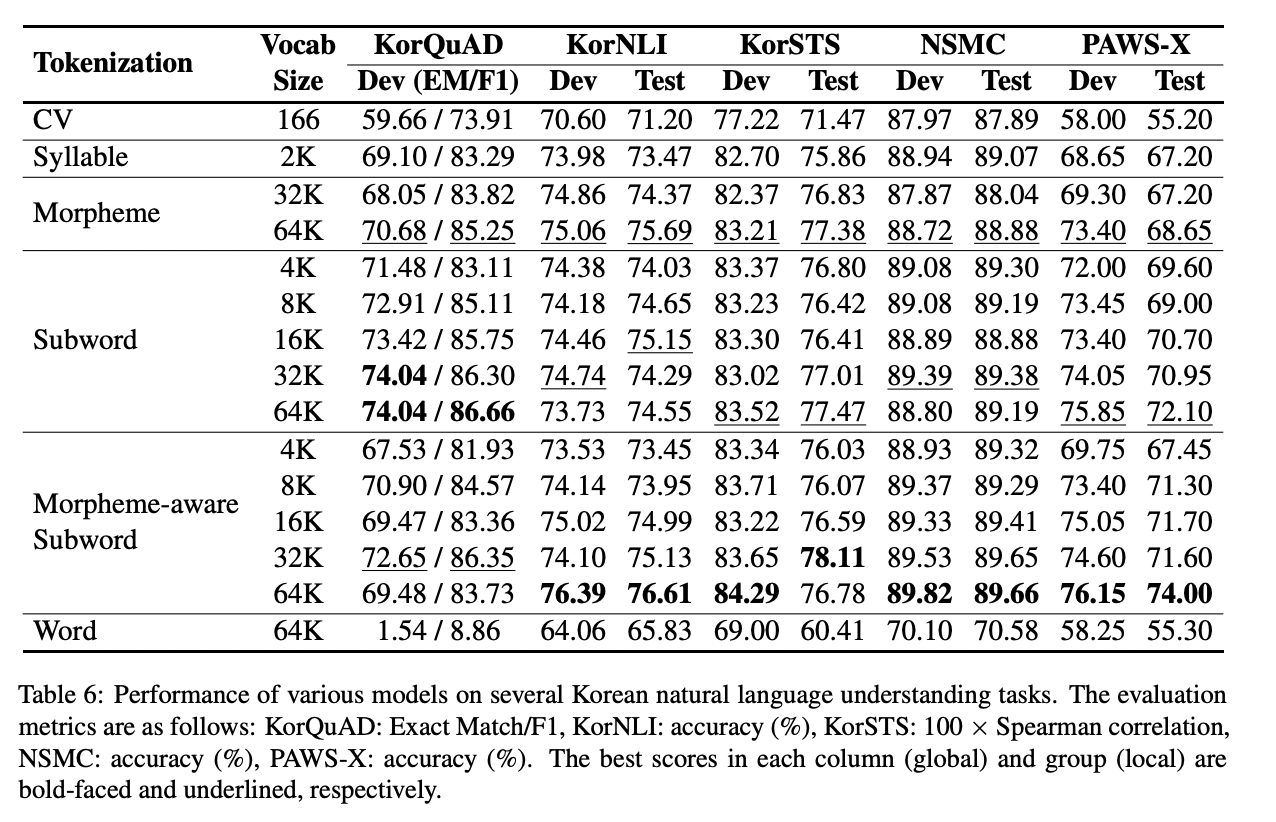
Morpheme-aware subword 64K 모델이 거의 대부분의 task에서 가장 좋은 성능을 보였습니다. 사전의 크기가 커질수록 성능 역시 좋아지는 결과 또한 확인할 수 있습니다.
6. Discussion
6.1 Token Length
tokenization은 text를 더욱 짧은 단위로 나누는 과정을 포함하고 있기 때문에 각 단위마다 포함하고 있는 정보의 양을 밝히는 것이 중요하다는 것을 발견했습니다. text길이가 길수록 더 많은 정보를 담고 있을 것이라는 가정하에 번역 test 결과를 plot 한 결과입니다.
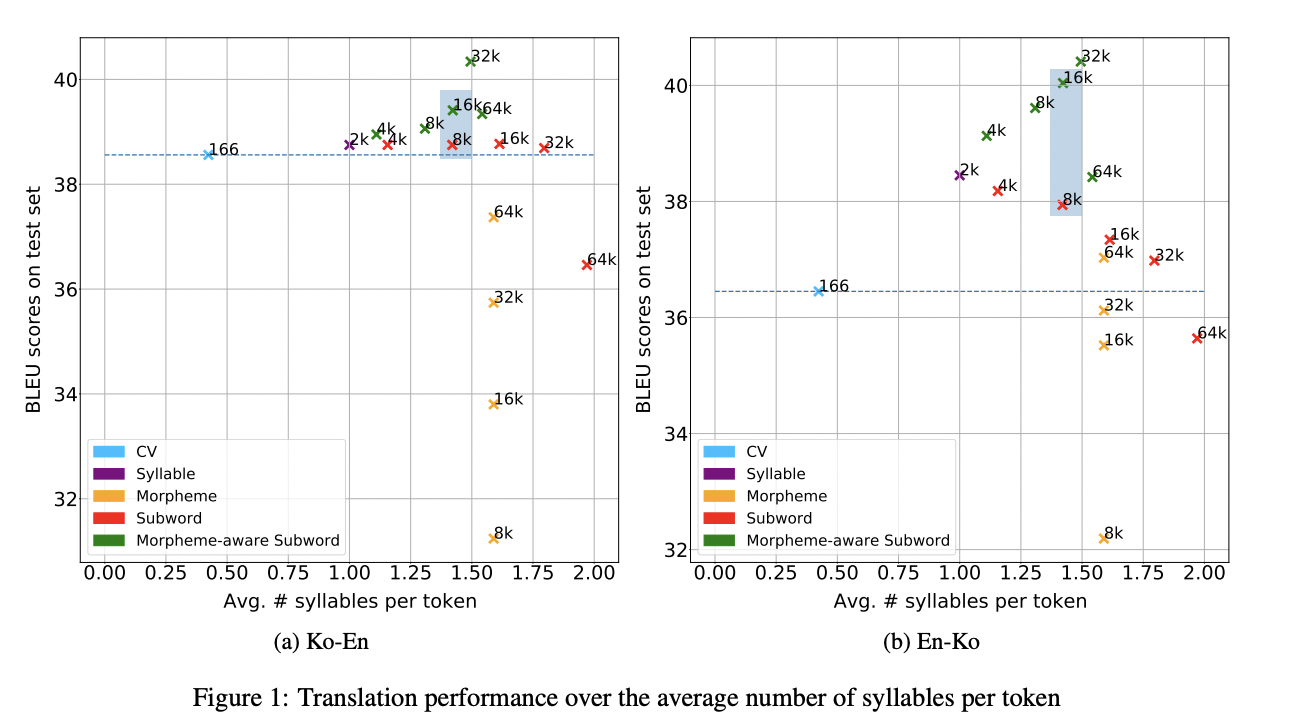
6.2 Linguistic
token의 길이가 tokenization 전략의 유일한 주된 요인은 아닙니다. 언어적 이해력(linguistic awareness)는 한국어 tokenization 전략의 중요한 요인이라고 저자들은 생각합니다.
6.3 Under-trained Tokens
높은 OOV rates는 morpheme 모델의 성능을 낮춘다고 지적했습니다.
7. Conclusion
해당 논문에서는 다양한 한국어 tokenization 전략을 소개하고 기계 번역과 5개의 NLU task를 수행합니다. 기계 번역에서는 한/영, 영/한 모두에서 morpheme-aware subword 모델이 가장 좋은 성능을 보였습니다. 하지만 NLU task에서는 하나의 가장 좋은 성능을 보이는 모델이 없었습니다. Subword 64k 모델이 KorQuAD에서 가장 좋은 성능을 보였고 나머지 4개 task에서는 morpheme-aware subword 64K 모델이 가장 좋은 성능을 보였습니다.
