비지도 방법을 통해 한국어 단어를 추출하는 KR-WordRank 방법을 소개하는 논문입니다. 학습 데이터를 만들 수 없거나 실제 사용되는 형태의 단어 추출이 필요한 경우 유용하게 사용할 수 있는 컨셉입니다.
[Abstract]
WordRank는 중국어와 일본어에서 가장 많이 사용되는 word extraction 알고리즘입니다. 중국어와 일본어에서는 좋은 성능을 보이고 있지만 두 언어와는 언어구조적 차이로 인해 한국어에서는 WordRank 알고리즘 성능이 썩 좋지 않습니다. 해당 논문에서는 한국어에서 WordRank 알고리즘의 성능이 좋지 않은 이유를 다루고 WordRank 알고리즘을 한국어에 사용할 수 있도록 수정한 KR-WordRank 알고리즘을 소개합니다.
1. 서론
빅데이터 환경에서는 정형 데이터보다 텍스트 데이터와 같은 비정형 데이터의 가치가 훨씬 커질 것으로 전망되고 있습니다. 새로운 가치를 창출하기 위한 텍스트 데이터 가공 및 분석 방법론의 개발을 주로 다루는 텍스트마이닝(text mining)에 대한 중요성이 크게 부각되고 있습니다.
텍스트마이닝 기법들의 기저에는 특정 언어에서 사용되는 문법적인 단어의 인식뿐만 아니라 단어의 형태 및 의미 분석이 높은 정확도로 구현할 수 있다는 가정이 내포되어 있습니다. 이를 위해 컴퓨터가 단어에 대한 자동 인식이 가능하도록 어휘 사전이 구축되어 있음을 전제합니다. 연속된 단어들 간의 관계를 파악하기 위한 연어 이해, 문법적 종류를 분류하기 위한 형태소 분석, 문법적 관계를 파악하기 위한 의존성 분석 등을 이용한 다양한 텍스트마이닝 알고리즘들이 실행되고 있습니다. 현재, 텍스트마이닝을 위한 기초 연구는 영어권 국가, 특히 미국의 연구자들에 의해 주도적으로 진행되고 있습니다.
한글 텍스트마이닝 과제를 위해 선결되어야 하는 가장 중요한 이슈는 단어를 인식하는 것 자체가 어려운 경우가 상당히 빈번하다는 것입니다. 끊임 없이 생기는 신조어와 특정 분야에서만 사용되는 전문용어들로인해 사용되는 모든 단어를 예상할 수 없습니다. 이처럼 일반적으로 사용되지 않는 단어들을 인식하기 위해 단어에 관련된 사전 지식이 필요하며, 사전 지식으로 정의되지 않은 단어를 미등록 단어(out-of vocabulary, OOV)라고 합니다. 또한 데이터에 많은 오류들이 있습니다. 철자법 오류, 언어 파괴 현상, 띄어쓰기 오류 등 다양한 오류들로인해 단어 인식이 매우 어려워지고 있습니다.
단어 인식 방법은 지도학습, 비지도학습으로 나눌 수 있습니다. 학습 데이터를 이용하는 지도학습은 언어 오류가 많고 신조어와 같이 예상할 수 없는 단어가 끊임없이 생성되는 분야의 문서를 분석하기에는 적합하지 않습니다. 또한 모든 단어가 학습데이터에 등장하더라도 문맥적 모호성, 도메인 적합성 문제를 해결해야만 합니다. 띄어쓰기 오류에 의하여 모호성이 발생할 수 있으며, 학습데이터와 주어진 문서 집합의 도메인의 차이로인해 도메인 적합성 문제 역시 발생할 수 있습니다.
지도학습의 문제를 해결하기 위해 사전지식에 의존하지 않으며 주어진 문서집합의 통계적 정보를 이용하여 단어를 인식하기 위한 비지도학습 기반 단어 인식방법이 제안되었습니다. 비지도학습 기반 방법은 실제 사용되는 단어를 추출하기 때문에 전문 용어나 신조어와 같이 예상할 수 없는 단어를 인식하는데 효과적이며, 학습데이터 구축이 필요하지 않기 때문에 시간과 비용을 줄일 수 있습니다. 또한, 문서집합이 포함하는 전역정 정보를 이용할 수 있습니다. 비지도학습은 학습데이터를 사용하지 않는 대신 단어의 가설을 반영하는 통계적 기준을 사전에 정의한 뒤 해당 가설을 바탕으로 단어를 인식합니다.
단어를 정의하는 가설은 다양합니다. 응집성이 높은 연속된 글자를 단어로 인식하기 위하여 상호 정보량(mutual inforamtion)을 이용하는 방법이 있습니다. 글자간의 응집성이 단어를 구성하는 글자간의 정보로부터 통계적 정보를 추출하는 내부 경계 값이라면 단어 주변의 다른 글자들로부터 통계적 정보를 추출하는 외부 경계 값을 계산하는 방법도 있습니다. 좌우에 등장하는 글자의 종류가 많은 경우 단어로 인식하는 Accessor Variety와 좌우에 등장하는 글자의 엔트로피를 계산한 뒤 그 값이 큰 경우 단어로 인식하는 Branch Entropy가 제안되었습니다. 베인지안 모델을 이용하여 비지도 학습 방법으로 단어를 인식하는 방법 또한 제안되었습니다. WordRank는 그래프 구조를 이용한 단어 추출 방법의 하나로 단어 후보를 그래프의 마디로 구성한 뒤 mutual reinforcing relationship 방법을 이용하여 네트워크상에서 중심성이 높은 후보 마디를 단어로 추출합니다. WordRank는 복잡한 계산을 필요로하지 않으며, 사전지식 없이 단어를 인식할 수 있습니다.
WordRank 방법은 중국어와 일본어의 단어 이식에 대해 복잡한 계산을 하지 않으면서 상당히 높은 정확도를 보였습니다. 하지만 한글에 WordRank를 적용할 경우, 다의적인 1음절 글자의 존재로 인해 단어 인식 성능이 저하되는 문제점이 발생하였습니다. 한글 단어 인식에서 WordRank가 갖는 문제점을 해결하기 위해 해당 논문에서는 부분 글자의 위치정보를 고려하는 KR-WordRank 방법을 제안합니다. KR-WordRank는 비지도학습 기반의 단어 인식 기법으로서 학습데이터를 사용하지 않기 떄문에 사전 지식에 의존적이지 않으며 다양한 데이터 원천으로부터 수집되어 띄어쓰기와 같은 오류가 많은 문서 집합에서도 효과적으로 단어를 인식할 수 있다고 기대됩니다.
2. WordRank
WordRank는 외부 경계값(EBV)과 내부 경계값(IBV)을 모두 이용하여 단어를 인식하는 비지도학습 방법입니다. 외부 경계값이란 주어진 단어의 좌우 주변에 다른 단어가 나타날 가능성을 의미하며, 내부 경계값이란 주어진 단어를 이루는 연속적인 글자의 응집성을 의미합니다. WordRank의 외부 경계값은 웹 페이지의 중요도를 의미하는 authority가 높은 웹페이지로부터 유입되는 링크가 많은 웹 페이지의 authority가 높다고 가정하는 방법인 mutual reinforction relationship을 이용하여 계산합니다. WordRank에서는 올바른 단어의 좌우 경계에는 다른 올바른 단어가 존재할 것이라고 가정한 뒤, 각 단어의 외부 경계값인 authority를 주위의 올바른 단어들의 authority에 의하여 강화하는 방식입니다. WordRank에서는 외부 경계값이 높은 단어 후보들이 인접한 다른 후보들의 외부 경계값을 높임으로서 서로 외부 경계값을 상호 강화합니다. 단어 후보 마디는 왼쪽 경계의 authority인 left boundary value(LBV)와 오른쪽 경계의 authority인 right boundary value(RBV) 두 종류의 외부 경계값을 갖습니다. 해당 두 경계값을 바탕으로 authority 값이 높은 단어 후보를 단어로 추출합니다.
WordRank에서 단어 후보 그래프는 식 (1)에서 나타난 바와 같이 각 마디(단어 후보)는 좌/우 방향 외부 경계값을 가지고, 각 마디 간의 관계는 왼쪽 이웃 관계를 나타내는 호(E_LN)와 오른쪽 이웃을 나타내는 호(E_RN)로 구성되어 있습니다.
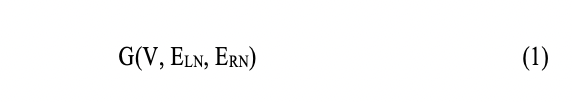
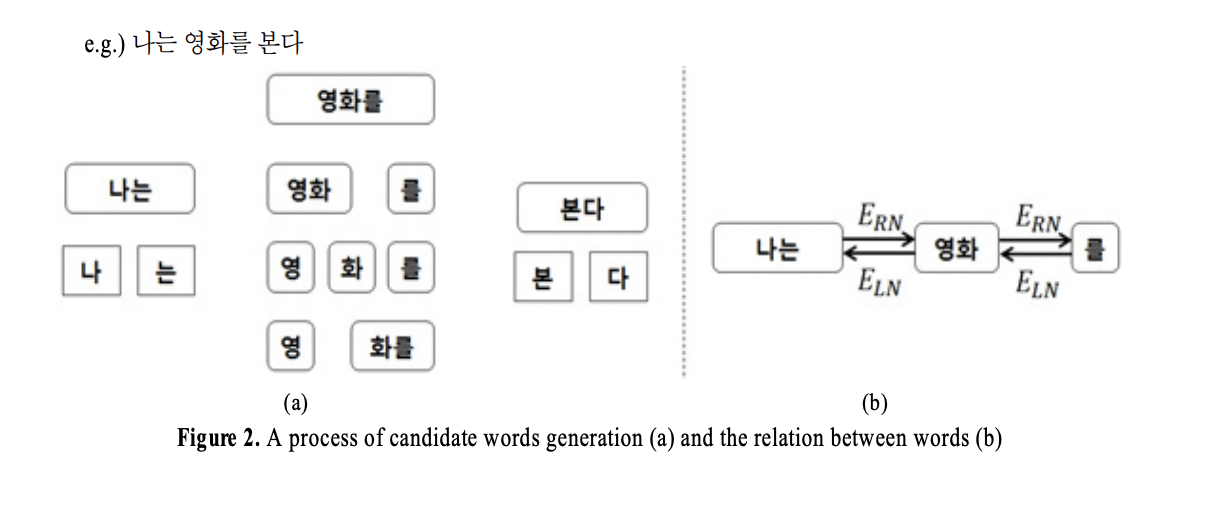
단어 후보의 RBV는 오른쪽에 등장한 단어 후보의 LBV의 합으로, LBV는 왼쪽에 등장한 단어 후보의 RBV의 합으로 정의됩니다. 두 단어 후보가 같은 단어 경계에 대하여 각각 다른 종류의 단어 경계값을 공유하기 떄문에 이와 같이 됩니다. 각 단어 후보는 다른 단어 후보의 외부 경계값을 상호 강화시키기 위하여 식 (2) 및 식 (3)과 같은 식을 사용합니다.
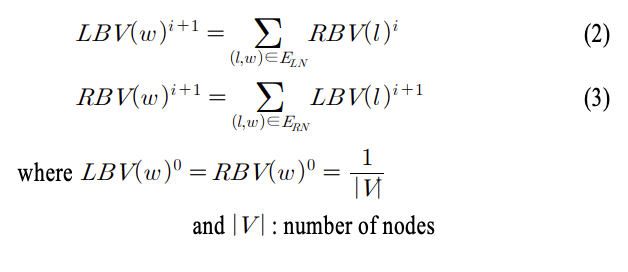
i는 mutual reinforction의 반복 계산 횟수를 의미하는 인덱스로 사전에 정의된 반복 횟수 k까지 식 (2)와 식 (3)을 차례로 반복합니다. 각 단어 후보의 LBV는 좌측에 인접한 다른 단어 후보들의 RBV의 합이기 때문에 E_LN으로 연결되어 있는 단어 l의 RBV 합을 w의 LBV 값으로 업데이트 합니다. 상호 관계 방법은 각 반복 단계마다 외부 경계값의 합이 증가하기 때문에 업데이트 후 외부 경계 값의 합이 일정하도록 식 (2)와 식 (3)의 계산을 한 번 수행한 뒤 정규화 과정을 거칩니다.
WordRank에서는 단어 후보 선별 과정에서 다음과 같은 경험적 방법이 도움이 될 수 있습니다. 첫째, 문서 집합에서 단어 후보의 출현 빈도수가 사전에 정의한 기준보다 작을 경우 후보에서 제외할 수 있습니다. 둘째, 동일한 정볼르 가지고 있는 단어 후보를 그래프에서 제외할 수 있습니다. 셋째, 언어적 사전 지식을 이용하여 단어 후보를 선별할 수 있습니다.
WordRank는 단어의 내부 경계값을 계산하기 위하여 mutual information(MI)을 사용합니다. MI는 두 글자가 연속적으로 등장할 가능성을 수치화한 방법으로 식 (4)와 같습니다.
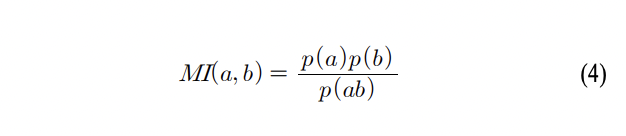
WordRank에서는 단어 후보의 길이가 L일 경우 L-1개의 연속된 글자 조합의 MI를 계산한 뒤, 최소값을 단어를 구성하는 글자의 응집성으로 판단합니다.
단어는 다른 단어오 경계를 잘 나눌 수 있고, 글자간의 응집성이 높아야하므로 WordRank로부터 계산된 단어 가능성 점수 WR(w)는 식 (5)와 같이 외부 경계값과 내부 경계값의 곱으로 표현됩니다.

f(x)는 내부 경계값과 외부 경계값의 가중치를 조절하기 위한 함수로 사용됩니다.
3. KR-WordRank
3.1 WordRank의 한국어 적용 및 한계: 다의적인 1음절 글자로 인한 단어 추출 성능 저하
'단어 후보'와 '글자'는 아직 단어인지 확인할 수 없는 연속된 글자를 의미하고, '단어'는 실제로 단어로 확인된 글자를 의미합니다. 단어 추출 방법은 단어 후보 중에서 단어를 고르는 문제이고, 단어 가능성은 각 단어 후보 중에서 단어일 가능성입니다.
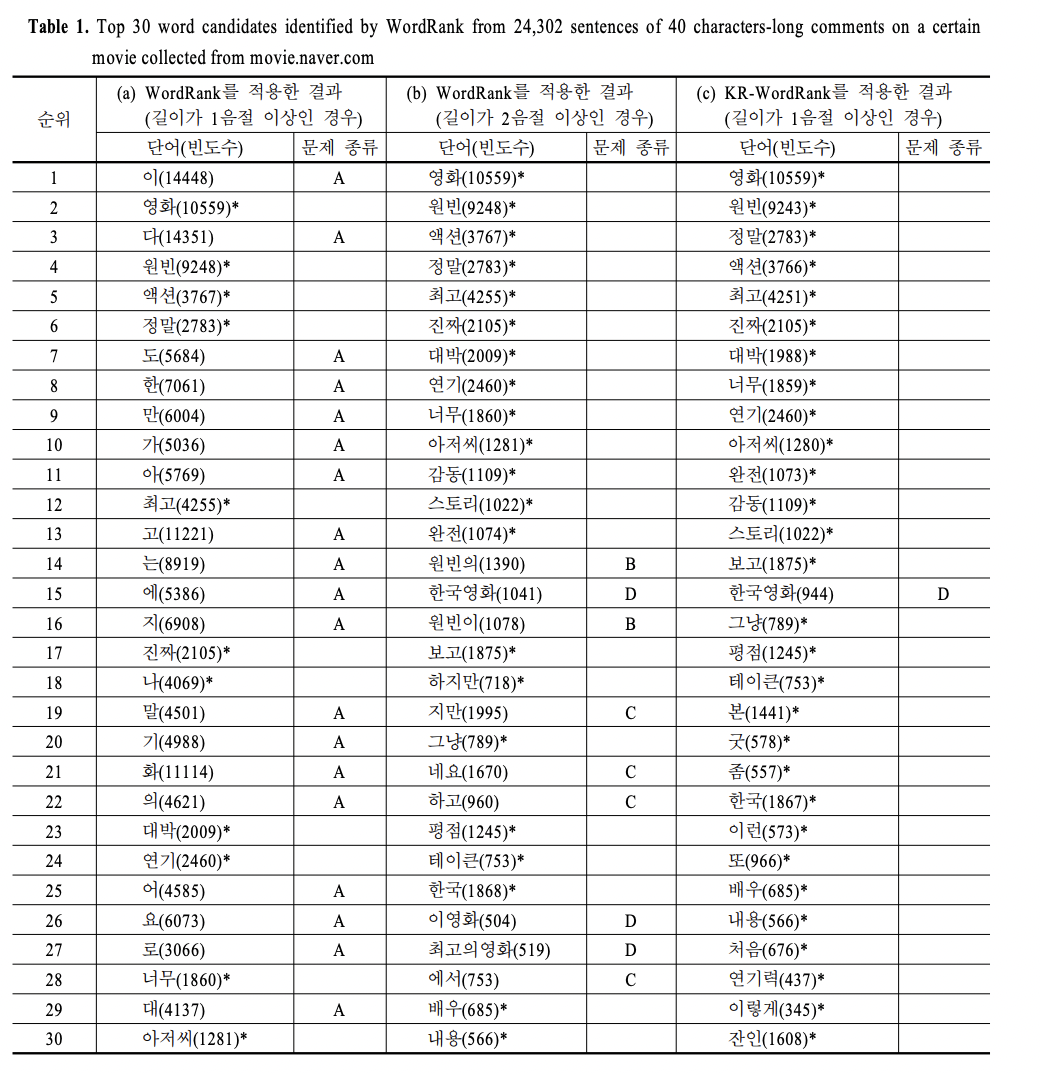
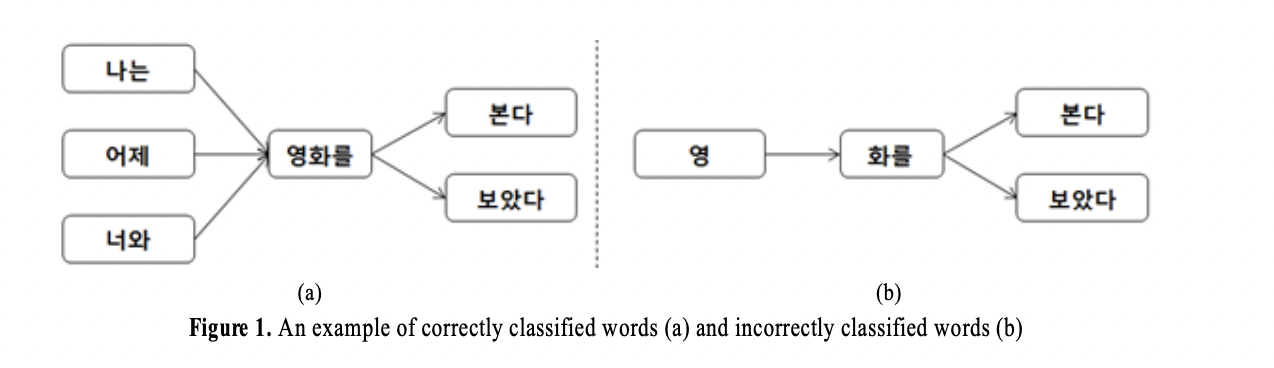
WordRank의 적용 결과를 보면 의미가 없거나 해석이 어려운 1음절 글자들의 단어 가능성이 높게 계산되는 것을 확인할 수 있습니다. 사용된 데이터에서 길이가 1음절인 글자의 좌우에 다양한 글자들이 나타났기 때문에 이와 같은 결과가 나오게 됩니다. 즉, 단어가 될 수 없는 불필요한 마디들 간의 연결 때문에 WordRank의 단어 추출 성능이 저하되는 결과가 나타납니다. 이로부터 WordRank를 한국어의 단어 추출 문제에 적용하기 위해서는 불필요한 단어 후보 마디를 효과적으로 줄일 필요가 있음을 할 수 있습니다.
단어 후보 그래프의 허브 마디들은 단어 가능성이 높을 뿐 아니라 문서 집합에서 자주 언급되거나 다른 여러 중요한 단어 주변에 등장하는 단어이기때문에 문서 집합의 키워드로 생각할 수 있습니다. TextRank는 단어가 인식된 상황에서 각 단어 간의 관계를 그래프로 표현한 뒤 키워드를 추출하지만, WordRank는 단어를 추출함과 동시에 주어진 문서집합에서의 키워드를 추출합니다.
텍스트 데이터를 벡터로 만드는 경우에는 명사나 어근이 어미나 조사보다 중요한 역할을 합니다. 이를 위해 벡터화 과정에서 품사 태깅을 이용하여 불필요한 품사를 제거하기도 합니다. 품사 정보를 사용하기 어려운 상황에서는 단어 가능성이 높은 글자들을 {명사, 어근}와 같이 의미를 지니는 단어 집홥과 {어미, 조사}와 같이 문법적 기능을 하는 단어 집합으로 분류할 수 있어야 합니다. {명사, 어른, 동사}는 새로운 단어들이 나타나기 쉬운 열린 집합에 속합니다. 기능적 역할을 하는 {어미, 조사}는 새로운 단어가 나타날 가능성이 낮은 닫힌 집합에 속해 새로운 단어들이 만들어질 가능성이 낮아 규칙을 이용하여 제거가 가능합니다. 하지만 규칙기반 방법은 불확실하고 애매한 상황을 인식할 수 없다는 문제점을 안고 있습니다. 그렇기 때문에 규칙이 아닌 데이터로부터 {명사, 어근} 등의 의미를 지니는 단어 집합과 {어미, 조사}와 같이 문법적 기능을 하는 단어 집합을 구분할 수 있는 방법이 필요합니다.
3.2 KR-WordRank: 부분 글자의 위치 정보를 이용한 단어 추출 능력 향상
한국어는 각 글자가 대부분 의미를 지니기 때문에 사실상 표의문자에 가깝습니다. 왜냐하면 한자의 음을 글자로 옮겼기 때문입니다. 또한 한국어의 경우 띄어쓰기 오류가 있더라도 일부 주어진 띄어쓰기 정보는 단어 추출의 중요한 힌트가 될 수 있습니다. 그렇기 때문에 일부 주어진 띄어쓰기 정보를 함께 사용하는 방법은 한국어의 단어 추출 방법에 큰 도움이 될 수 있습니다.
KR-WordRank의 특징은 {명사, 어근} 집합과 {어미, 조사} 집합을 분류하기 위하여 각 단어 후보의 위치 정보를 이용한다는 점입니다. 명사나 어근은 띄어쓰기를 기준으로 나눈 토큰의 왼쪽에 위치하고, 어미나 조사는 오른쪽에 위치합니다. KR-WordRank는 단어 후보를 토큰의 왼쪽에 등장하는 후보 집합 L과 토큰의 오른쪽에 등장하는 후보 집합 R로 분리합니다. L은 명사나 어근의 후보집합이고, R은 어미나 조사의 후보집합입니다. 토큰 자체가 단어 후보인 경우에는 L집합의 원소로 취급합니다.
집합 R에 해당하는 상위 k개의 단어는 대부분 조사와 어미에 해당되므로 이를 조사와 어미로 추출하는 방식을 사용합니다. 추출된 조사와 어미를 이용하여 (Figure5)에 나타난 방법으로 L집합에서 명사와 어근 추출 방법을 보완합니다.

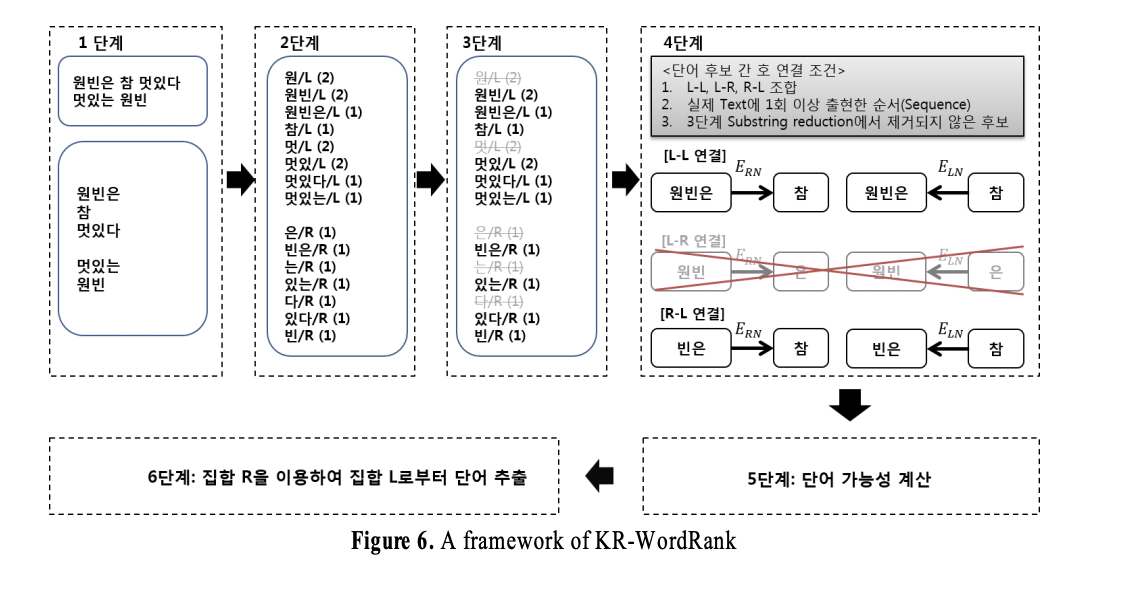
KR-WordRank는 (Figure6)에 나타난 여섯 단계의 절차를 통해 한글 단어를 추출합니다.
1단계 : 띄어쓰기를 이용하여 문장을 여러 개의 글자 집합인 토큰(token)으로 구분 - 띄어쓰기로 구분된 각 토큰에서의 부분 글자만을 고려합니다. 띄어쓰기가 완벽히 된 단어의 경우에는 불필요한 단어 후보를 고려하지 않을 수 있습니다.
2단계 : 각 부분 글자의 위치 확인 - 부분 글자에 대하여 (L, R)의 위치 태그를 부여하여 단어 후보를 만든 뒤 각 단어 후보의 빈도수를 계산합니다.
3단계 : 2단계로부터 얻어진 부분 글자 집합에 대하여 Sub-string Reduction 수행 - 부분 글자 A가 다른 부분글자 B의 진부분집합이며 A의 출현 빈도와 B의 출현 빈도가 같을 경우 A를 단어 후보에서 제외합니다.
4단계 : 각 단어 후보 간의 호 생성 - 이론적으로 단어 후보 간 호는 L-L, L-R, R-L, R-R 네 가지 조합을 통해 생성할 수 있습니다. 하지만 하나의 토큰을 L 집합에 속하는 것으로 가정할 경우, R-R 조합은 생성될 수 없으므로 해당 조합은 고려 대상에서 제외합니다. 실제 텍스트에 1회 이상 출현한 순서에 대해서만 호를 연결합니다. 호 연결은 3단계에서 제거되지 않은 단어 후보들만을 고려합니다.
5단계 : mutually reinforcement relationship을 이용하여 단어 가능성 계산
6단계 : 집합 R로부터 상위 k개의 단어 후보를 추출하여 집합 L로부터 '명사+조사', '어근+어미'의 결합 단어를 제거하여 최종적인 단어 추출 - KR-WordRank는 한글의 문법적인 형태보다는 실제로 사람들이 빈번하게 사용하는 형태를 단어로 인식하기 위한 알고리즘입니다.
2단계와 4단계를 통하여 토큰의 중간에 위치한 무의미한 부분 글자를 단어 후보에 포함시키지 않음으로써 의미 있는 단어 후보를 걸러내는 역할을 합니다. 또한 6단계를 통하여 조사나 어미의 결합으로 인한 중복적인 단어를 부분적으로 제거할 수 있습니다.
4. KR-WordRank 성능 검증
4.1 실험 설정
(1) 데이터 및 변수 설정
세종 말뭉치의 문어 문서 279개에 포함되어 있는 837,805개의 문장으로부터 자동으로 단어를 추출하였습니다.
WordRank와 KR-WordRank가 곹오으로 사용하는 변수는 동일하게 설정하였습니다. 7음절 이하 글자들은 단어의 후보로 고려하였으며, 50번 이하로 등장하는 모든 글자는 단어 후보에서 제외하였습니다.
(2) 평가 지표
WordRank와 KR-WordRank는 각 단어의 형태소를 분리하기 위한 방법이 아니라 의미 있는 단어를 추출하기 위한 방법이기 때문에 품사 태깅과 다른 평가 방법을 사용하였습니다. WordRank와 KR-WordRank에서 추출해야하는 대상은 해석이 가능한 의미를 지니는 체언, 용언, 관형사, 부사, 감탄사, 독립적으로 사용가능한 복합형태소 입니다. 이를 고려하여 단어의 정확도를 계산하는 함수는 식 (6)과 같습니다.

4.2 실험 결과
한국어의 경우 의미를 해석할 수 있는 단어나 복합형태소는 토큰의 왼쪽에 등장하고 문법적 기능을 하는 단어나 복합형태소는 토큰의 오른쪽에 등장합니다.
4.3 토의
KR-WordRank는 실제로 자주 사용되는 표현을 단어로 추출합니다. 즉, KR-WordRank에서 추출하는 대상을 정리하면 '의미를 지니며 실제로 자주 사용되는 독립적인 단어 혹은 복합형태소' 입니다. KR-WordRank는 언어학적으로 형태소라는 것으로 정의되는 단어가 아닌 실제로 사람들이 사용하는 표현으로 단어를 추출합니다.
KR-WordRank가 단어 추출을 잘 하기 위해서는 충분한 수의 문서가 제공되어야 하지만, 직관적으로 해석할 수 있는 키워드를 추출하기 위해서는 주어진 문서 집합에 포함된 주제의 종류가 적을수록 성능이 우수합니다. 즉, KR-WordRank를 이용하여 단어 추출 및 키워드 추출을 함께 하기 위해서는 비슷한 주제의 문서들을 사전에 분류함으로써 그 성능을 높일 수 있을 것으로 기대합니다.
KR-WordRank는 같은 형태의 글자에 대하여 위치 정보를 이용하여 집합 L과 R로 분리하기 때문에 그래프를 구성하는 마디의 수를 늘릴 수 있습니다. 하지만 토큰의 중간에 위치하는 부분 글자들을 단어 후보로 포함하지 않기 때문에 그래프의 마디의 수를 줄이는 효과 역시 있습니다.
KR-WordRank나 WordRank뿐 아니라 Accessor Variety나 Batch Entropy 방법의 공통된 한계점은 자주 등장하지 않는 단어의 경우 정상적으로 추출된 가능성이 낮다는 점입니다. 자주 등장하지 않는 단어에 대해서도 추출을 하려면 다른 단어 추출 방법을 함께 사용해야 할 필요가 있습니다. 또 다른 KR-WordRank의 한계점은 용언의 활용이 일어난 경우 이를 인식하지 못한다는 점입니다. 마지막으로 KR-WordRank는 사용자가 경험적으로 정하는 변수에 의하여 단어 추출 성능이 좌우 될 수 있습니다. 그렇기 때문에 최적 값의 변수를 찾는 연구 역시 필요합니다.
5. 결론
WordRank의 경우 한국어 단어 추출에 대해서는 몇 가지 한계점이 있습니다. 표의문자에 가까운 한국어의 경우 1음절 글자들이 단어로 추출되는 경우가 많으며, 어미나 조사의 경우 독립적으로 단어로 사용되는 경우 역시 많습니다. 문서 집합으로 추출되어야 하는 대상은 조사나 어미와 같은 문법적 기능을 하는 단어가 아니라 명사나 어근과 같이 의미를 지니는 단어일 경우가 많습니다. 그렇기 때문에 한국어 단어 추출 문제의 경우 문법적 기능을 하는 단어는 추출 대상에서 제외할 수 있어야 합니다.
KR-WordRank는 언어학적으로 정의되는 단어가 아닌, 주어진 문서집합에서 실제로 자주 사용되는 형태로 단어를 추출하는 특징이 있음을 실험을 통하여 알 수 있습니다. 즉, KR-WordRank가 추출하는 대상은 '의미를 지니며 실제로 자주 사용되는 독립적인 단어 혹은 복합형태소'입니다.
KR-WordRank가 가질 수 있는 장점으로 기대되는 것은 다음과 같습니다. 첫째, 주어진 문서 집합 내에 포함되어 있는 주제의 종류가 적을수록, 즉 문서 집합의 내용이 이질적이지 않을수록 문서 내부의 단어 및 키워드를 잘 추출할 수 있습니다. 둘째, 실제로 사용되는 형태의 표현을 단어로 추출하기 때문에 신조어나 오탈자 등의 영향을 적게 받습니다. 셋째, 학습데이터를 사전에 구축하지 않고도 단어를 인식할 수 있습니다.
