CNN을 활용하여 document embedding을 수행하여 이를 PMF에 활용하여 추천 시스템에 활용하는 ConvMF를 소개하는 논문입니다.
[Abstract]
사용자-제품 평가 data의 희소성은 추천 시스템의 질을 낮추는 주된 원인입니다. document modeling-based 방법은 리뷰, 요약, 줄거리 등 문서 data를 추가적으로 활용함으로써 정확도를 높였습니다.
해당 논문은 context-aware recommendataion model인 ConvMF(convolutional matrix factorization)을 소개합니다. 이는 CNN(Convolutional neural network)와 PMF(Probabilistic matrix factorization)을 통합한 모델입니다. 결과적으로 ConvMF는 문서의 문맥정보를 잡아낼 수 있었고, 더 나아가 평가 예측 정확도를 높여주었습니다.
1. Introduction
사용자와 제품의 수가 비약적으로 증가함에 따라 사용자-제품 평가 정보는 희소해지게 되었고, 이는 전통 collaborative filtering 방법의 예측 정확도를 낮추는 주된 원인이 되었습니다. 정확도를 높이기 위해, 평가 정보뿐만 아니라 사용자 인구정보, social network, 제품 설명서와 같은 부가 정보를 사용하는 추천 기법이 제안되었습니다.
제품 설명서, 리뷰 등의 문서 정보를 추가 정보로 활용하기 위하여 LDA(Latent Dirichlet Allocation), SDAE(Stacked Denoising AutoEncoder)와 같은 document modeling 방법들을 기반으로 한 접근법들이 제안되기도 하였습니다. LDA와 collaborative filtering을 합한 CTR(Collaborative topic regression), SDAE와 PMF(Probabilisitc matrix fatoriation)을 합친 CDL(Collaborative deep learing) 등의 방법들 역시 소개되었습니다.
하지만 현재 존재하는 방법들로는 문서의 문맥정보를 고려하지 않는 bag-of-words 모델을 가정하기 때문에 문서 정보를 온전하게 포착하는 것이 불가능합니다.
이런 문제를 해결하기 위해 해당 논문에서는 CNN을 활용하였습니다. CNN은 문서와 이미지에서 local feature를 효율적으로 잡아낸다고 알려져 있습니다. 그렇기에 CNN의 사용은 문서를 깊게 이해할 수 있게해주고, LDA나 SDAE보다 더 나은 latent model을 만들어낼 수 있습니다. 더 나아가 Glove와 같이 이미 학습된 word embedding을 CNN에 활용하여 문서 정보를 더욱 잘 이해할 수 있습니다.
CNN의 근본적인 목적이 추천의 목적과 다르기 때문에 CNN은 추천 영역에서는 적합하지 않습니다. 전통적인 CNN은 단어, 구, 절의 label을 예측하는 분류문제에 특화되어 있습니다. 하지만 추천의 목적은 분류보다는 점수를 예측하기 때문에 회귀에 가깝습니다.
이런 문제를 해결하기 위해, 해당 논문에서는 문서의 문맥을 이해하는 추천 모델인 ConvMF(Convolutional matrix factorization)을 소개합니다. ConvMF는 CNN을 활용하여 제품 소개문서와 같은 문맥 정보를 잡아내어 평점 예측 정확도 향상에 도움을 주었습니다. ConvMF는 CNN과 PMF를 통합하여 collaborative 정보와 문맥 정보를 모두 잘 활용하게 되었습니다. 결과적으로 ConvMF는 평가 데이터가 거의 존재하지 않더라고 평점을 잘 예측할 수 있습니다.

2. Preliminary
2.1 Matrix Fatorization
전통적인 collaborative filtering 방식은 memory-based(ex. nearest neighborhood), model-based(ex. latent factor model) 2가지로 나눌 수 있습니다. 일반적으로 model-based 방식이 더 좋은 추천 결과를 보인다고 알려져 있습니다. 그렇기에 널리 알려진 model-based 방식인 MF를 소개하고자 합니다.
MF의 목적은 동일한 latent space에서 사용자와 제품의 latent vector를 찾는 것입니다. 사용자와 제품의 latent vector는 내적을 통해서 사용자-제품 관계를 잘 나타낼 수 있어야합니다. 사용자 i가 제품 j에 준 평점 r_ij는 사용자 i의 latent vector와 제품 j의 latent vector의 내적으로 근사될 수 있습니다. Latent model을 학습하는 일반적인 방식은 loss function을 최소화 하는 것이며 loss function은 실제 평점값과 예측 평점값의 최소제곱항과 over-fitting을 방지하기 위한 L2 regularity 항으로 이루어져 있습니다.
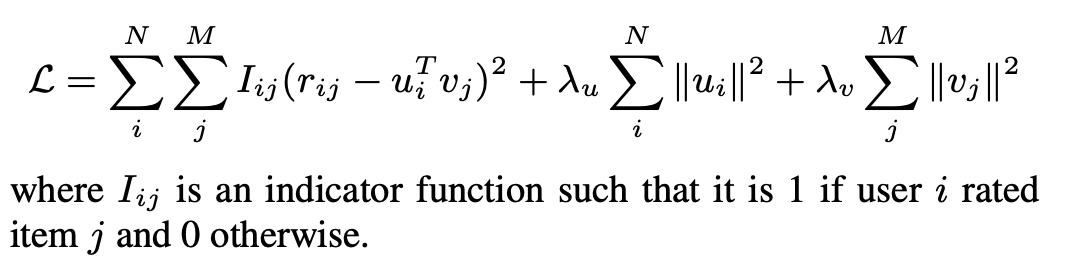
2.2 Convolutional Neural Network
CNN은 feed-forward 신경망의 변형입니다. CNN은 아래와 같은 구성요소를 지니고 있습니다.
- convolutional layer : local feature를 생성
- pooling(sub-sampling) layer : data를 좀 더 축약하여 표현
CNN은 비전 영역에서 발전하였지만 CNN의 주 아이디어는 정보검색과 search query retrieval, sentence modeling과 같은 NLP에서도 활발하게 적용되고 있습니다. NLP task를 위한 CNN은 CNN 구조에 많은 수정이 필요하지만 다양한 NLP task에서 좋은 성능을 보이고 있습니다.
3. Convolutional Matrix Factorization
해당 section에서는 ConvMF를 3단계로 소개합니다.
3.1 Probabilistic Model of ConvMF
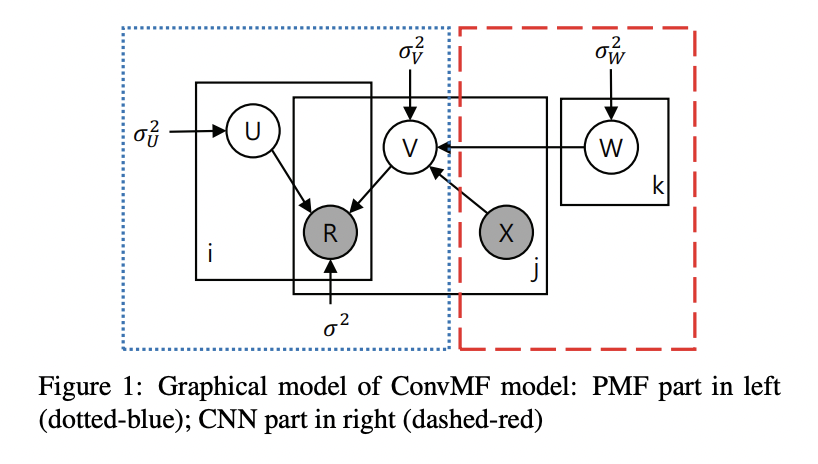
위 그림은 CNN과 PMF를 합친 ConvMF 모델의 도식입니다.
N명의 사용자와 M개의 제품이 있고, 관측 가능한 평점 정보는 R 행렬(NxM)으로 표현됩니다. 목표는 user latent model 행렬 U(kxN)과 item latent model 행렬 V(kxM)을 찾고 (U^T)V가 R행렬과 유사해지도록 만드는 것입니다. Probabilistic point에서 관측되는 평점의 조건부 분포는 아래와 같습니다.

User latent model의 generative model을 위해 Gaussian priori를 활용합니다.

기존의 PMF와 달리 해당 논문에서는 item latent model을 3가지 변수로 이루어졌다고 가정합니다. 1) CNN의 internal weight W 2) 제품 j의 문서를 표현하는 X_j 3) Gaussian noise인 epsilon
이를 활용하였을 때 item latent model은 아래와 같습니다.

X는 제품의 문서 집합입니다. CNN으로부터 얻어지는 document latent vector는 평균으로 활용되고, 제품의 gaussian noise는 분산으로 활용되어 CNN과 PMF를 연결하는 중요한 역할을 하게됩니다.
3.2 CNN Architecture of ConvMF
ConvMF에서 CNN의 역할은 제품 문서로부터 document latent vector를 만들어내는 것입니다. Document latent vector는 epsilon variable과 함께 item latent vector를 구성합니다.
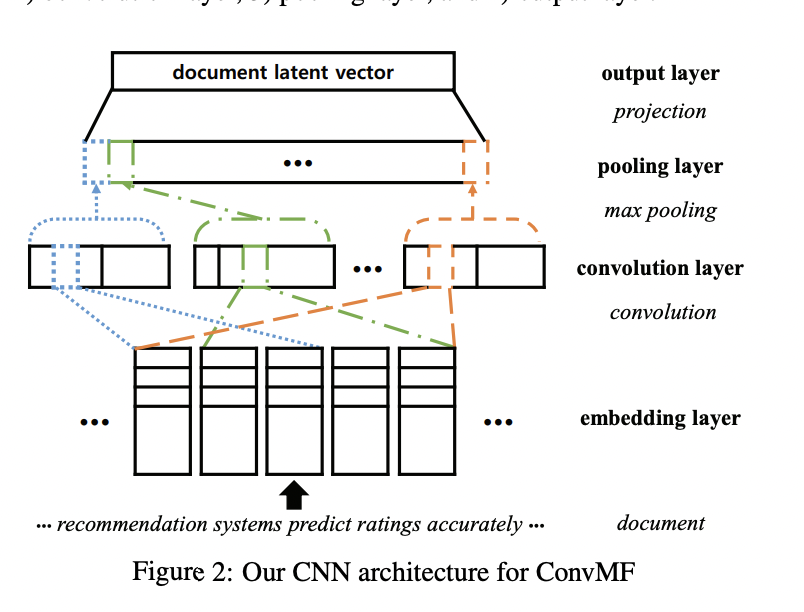
위 그림처럼 CNN은 4종류의 layer로 이루어져 있습니다. 1) embedding layer 2) convolution layer 3) pooling layer 4) output layer
Embedding layer
Embedding layer는 문서 원본을 convolution layer의 input으로 사용할 수 있도록 numeric dense vector로 변환하는 역할을 합니다. 자세히 보면, 문서가 l개의 단어로 이루어져 있을때, 문서 vector는 문서 내의 모든 단어 vector들을 이어붙인 행렬로 생각할 수 있습니다. 단어 vector는 임의로 초기화 되거나, Glove와 같이 이미 학습된 vector를 활용할 수도 있습니다. 단어 vector는 최적화 과정을 통해 지속적으로 학습이 됩니다.

Convolution layer
Convolution layer는 contextual feature를 뽑아냅니다. 앞서 언급했듯이 문서는 신호, 이미지와는 근본적으로 다른 문맥 정보를 지니고 있습니다. 그렇기에 문서를 적절하게 분석할 수 있는 convolution 구조를 활용해야만 했습니다.


Pooling layer
Pooling layer는 convolution layer로부터 대표적인 feature를 뽑아내고, pooing을 통해 다양한 길이의 문서를 고정된 개수의 feature vector로 다룰 수 있도록 해줍니다. Convolution layer 이후 문서는 n_c contextual feature vector들로 표현되며 각 contextual feature vector는 다양한 길이를 갖고 있습니다. 이는 2가지 문제를 일으킵니다.
- 너무 많은 contextual features c_i는 성능 향상에 큰 도움이 되지 않습니다.
- 고정되지 않은 길이의 contextual feature vector는 후에 나올 layer를 구성하는 것을 어렵게 합니다.
그러므로 max-pooling을 활용하여 고정된 n_c 길이의 vector로 문서를 표현합니다. n_c 길이의 vector의 각 원소는 contextual feature vector들에서 최대값만 뽑아낸 값입니다.
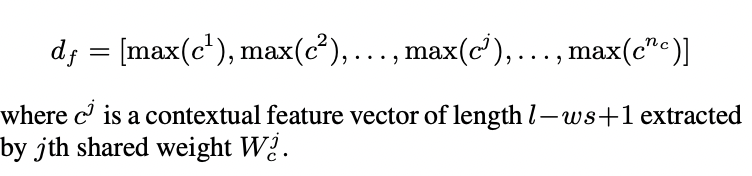
Output layer
일반적으로 output layer에서는 직전 layer에서 얻은 feature를 특정 task를 수행할 수 있도록 바꿔줍니다. 해당 논문에서는 d_f vector를 추천 task를 수행하기 위해 user와 item latent model이 존재하는 k-차원의 공간으로 projection 시켜줍니다. 결과적으로 conventional nonlinear projection을 통해 document latent vector를 만들게 됩니다.

3.3 Optimization Methodology
각 변수들을 최적화하기 위해(학습을 위해) 해당 논문에서는 MAP(Maximum A Posteriori) estimation을 활용하였습니다.
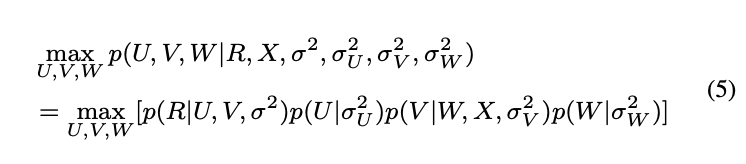
위 식은 아래와 같이 다시 쓸 수 있습니다.
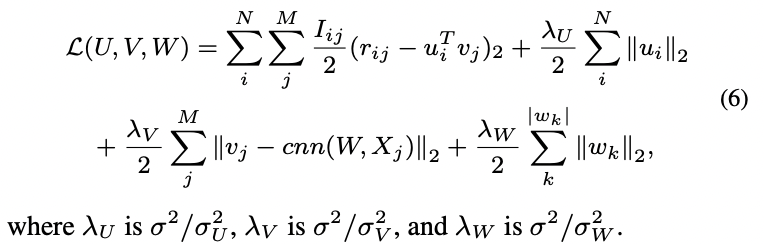
해당 논문에서는 다른 변수들은 고정시킨 채 하나의 변수를 최적화하는 과정을 반복하는 coordinate descent를 활용하였습니다.


4. Experiment
4.1 Experimental Setting
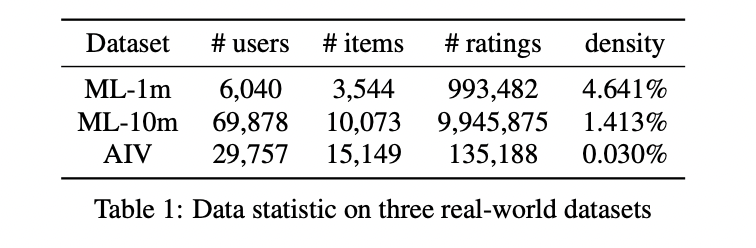
Datasets
Competitors and Parameter setting

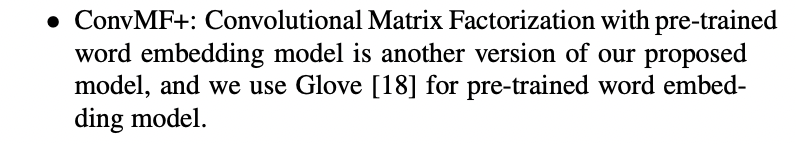
Implementation Detail
Evaluation Protocol

4.2 Experimental Results
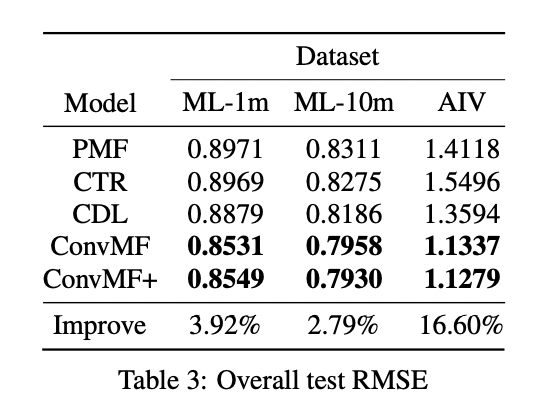
1) Quantitative Results on MovieLens and Amazon Datasets

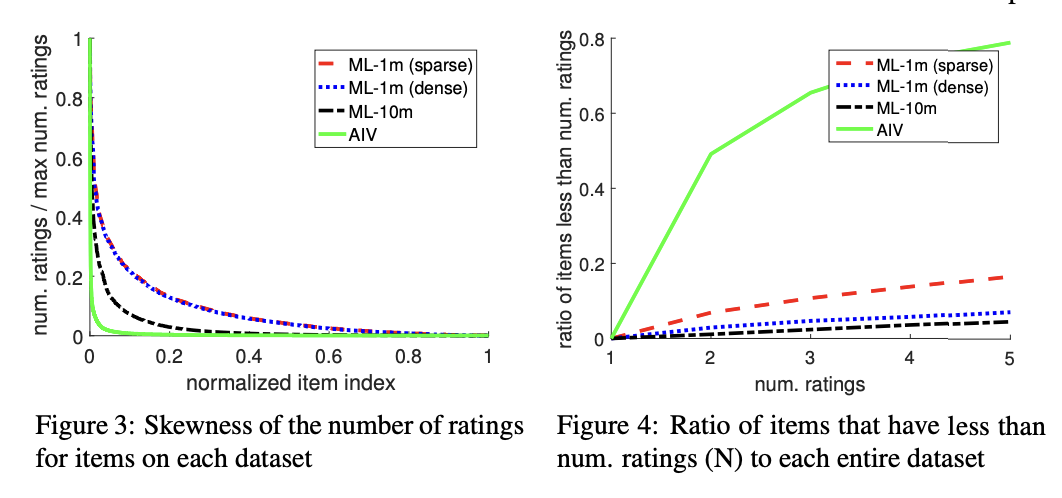
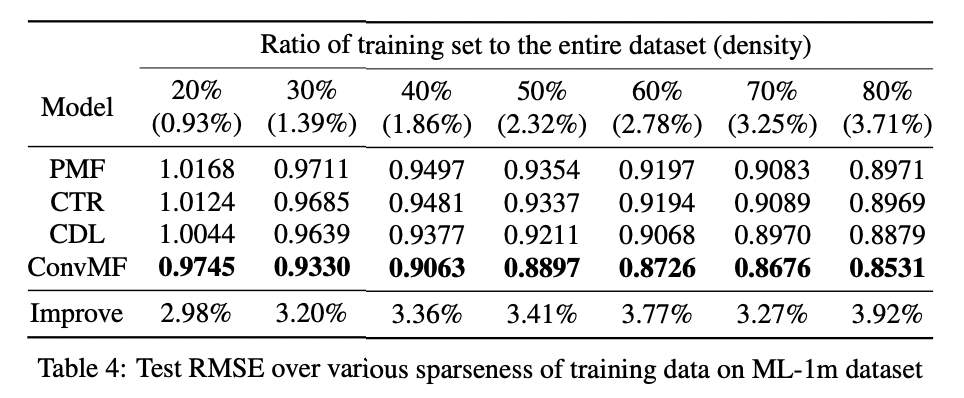
2) Quantitative Results Over Various Sparseness on ML-1m

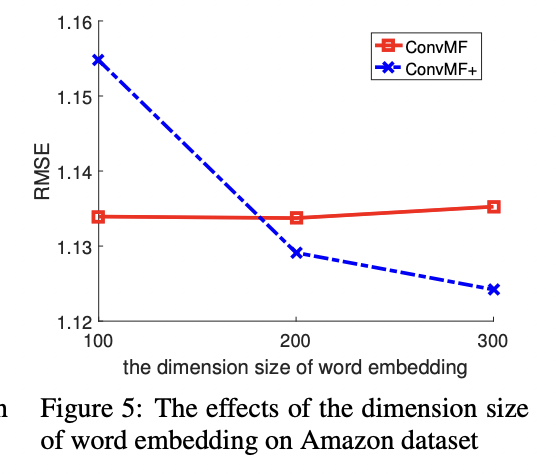
3) Impact of Pre-trained Word Embedding Model

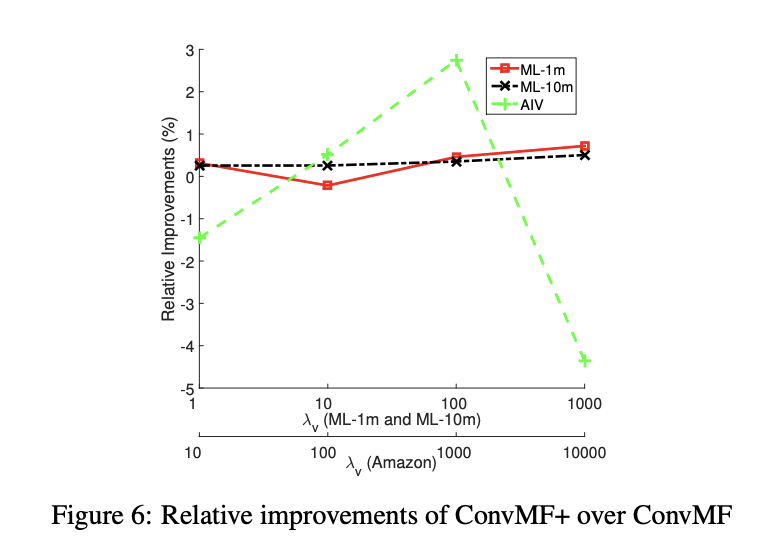
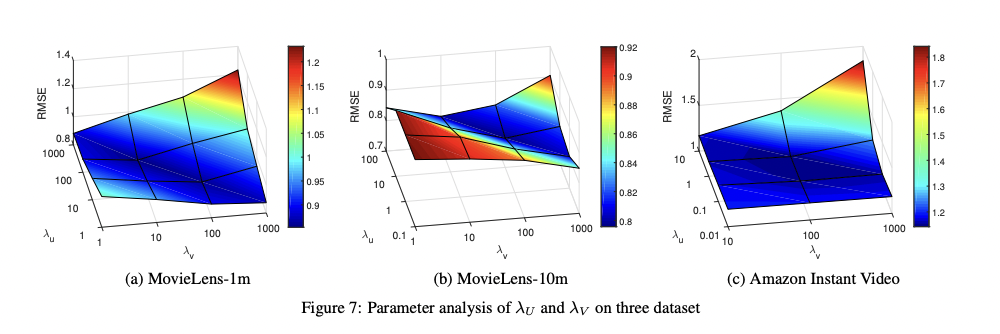
4) Parameter Analysis

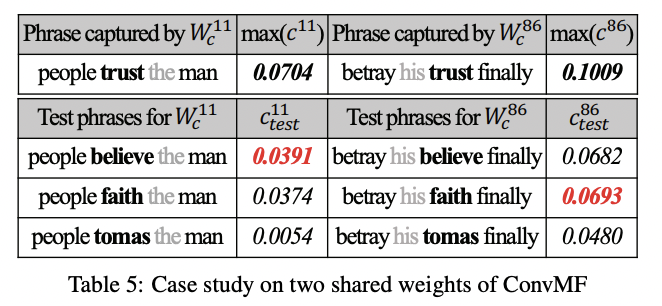
5) Qualitative Evaluation

5. Conclusion and Future work
해당 논문에서는 문서의 주변단어 혹은 단어 순서와 같은 문맥적 정보를 고려하여 문서를 더 잘 이해할 수 있도록 하고, 문맥을 고려하는 추천 모델인 ConvMF를 소개하였습니다. ConvMF는 CNN과 PMF를 통합하여 문맥 정보를 포착하여 평점을 잘 예측할 수 있도록 하였습니다.
