문장, 문서를 구성하는 단어들의 vector들의 단순 평균을 문장, 문서 vector로 활용하여 학습 시간을 줄이는 동시에 다양한 task에서 좋은 성능을 보이는 DAN(Deep Averaging Networks)에 관한 논문입니다.
[Abstract]
현존하고 있는 많은 자연어처리 deep learning 모델들은 계산 비용이 많이 들지만 input의 구성을 학습하는 것에 초점을 맞추고 있습니다. 해당 논문에서 제시하는 모델은 syntactically-ignorant한 특성을 지니고 있지만, 모델의 depth를 깊게하고 새로운 방식의 dropout을 사용하여 이전의 bag-of-words 모델에 비해 눈에띄는 성능 향상을 보였습니다. 더 나아가, 해당 논문에서 제시하는 모델은 다양한 문법 형태를 지닌 dataset에서 syntatic 모델들보다 좋은 성능을 보였습니다. 또한 input을 nonlinearly하게 변형시키는 것이 network를 tailoring하는 것보다 단어 순서와 문법을 합칠 때 더욱 중요한 것을 밝혔습니다.
1. Introduction
자연어처리를 위한 Vector space 모델은 단어를 낮은 차원의 vector로 표현하는 embedding으로 대표됩니다. Vector space 모델을 단어를 넘어 문장, 문서 단위에 적용시키기 위해서는 여러개의 단어 vector들을 하나의 vector로 표현할 수 있는 적절한 composition function을 사용해야 합니다.
Composition function은 2가지 class(unordered / syntactic)로 나눌 수 있습니다. Unordered function은 input text를 bags of word embedding으로 표현하는 반면 syntactic function은 단어의 순서와 문장의 구조를 고려합니다. 과거 실험들을 통해 syntactic function이 unordered function에 비해 많은 task에서 좋은 성능을 보이는 것이 밝혀졌습니다.
하지만 syntactic function은 unordered function에 비해 긴 학습 시간이 필요했고, dataset의 크기와 computing 자원의 영향도 많이 받았습니다.
해당 논문은 다양한 형태의 문장과 문서 수준의 task에서 거의 SOTA의 정확도를 보이는 deep unordered model을 소개합니다. deep averaging network(DAN)입니다.

DAN은 평균을 계산하기 전에 몇 개의 단어 embedding을 drop하는 새로운 방식의 dropout-inspired regularizer를 활용하여 성능을 높일 수 있습니다.
2. Unordered vs Syntactic Composition
해당 논문의 목적은 unordered function의 속도와 syntactic function의 정확도를 적절하게 결합시키는 것입니다.
이번 섹션에서 먼저 NBOW(Neural bag-of-words model)을 소개합니다. 그 후 NBOW의 단점을 극복할 수 있는 syntactic 함수들을 살펴본 후 마지막으로 기존의 NBOW 모델에 여러개의 nonlinear layer들을 쌓은 DAN을 소개합니다.
2.1 Neural Bag-of-Words Models
Text classification은 X개의 단어를 k개의 label에 mapping 시킵니다. 먼저, word embedding들에 composition function g를 적용합니다. 그 결과를 z라고 하였을 때, z를 로지스틱 함수의 input으로 사용합니다.

2.2 Considering Syntax for Composition
Syntactic composition function은 계산 효율성을 포기하는 대신, 하나의 단어나 구가 어떻게 다른 단어나 구에 영향을 미치는 지 학습하기 위하여 input의 단어 순서, 구조에 의존합니다.
RecNNs(Recursive Neural Networks)는 자연어의 타고난 구조에 의존하는 syntactic function입니다.
이제 Composition function g는 input 문장의 parse tree에 의존하게 됩니다. binary parse tree의 internal node의 representation은 그들의 child를 input으로 하는 nonliner function으로 계산됩니다. Parse tree의 각 node에서 계산하는 nonlinearity와 matrix/tensor 곱은 모델의 차원이 커질수록 계산 비용이 증가합니다. 또한 RecNNs는 모든 node에서 error가 필요했습니다.
RecNNs는 parse tree에 의존하기 때문에 training set과 test set에서 동일한 문법구조를 지녀야 했기 때문에 out-of-domain data에 대해서는 성능이 좋지 못했습니다.
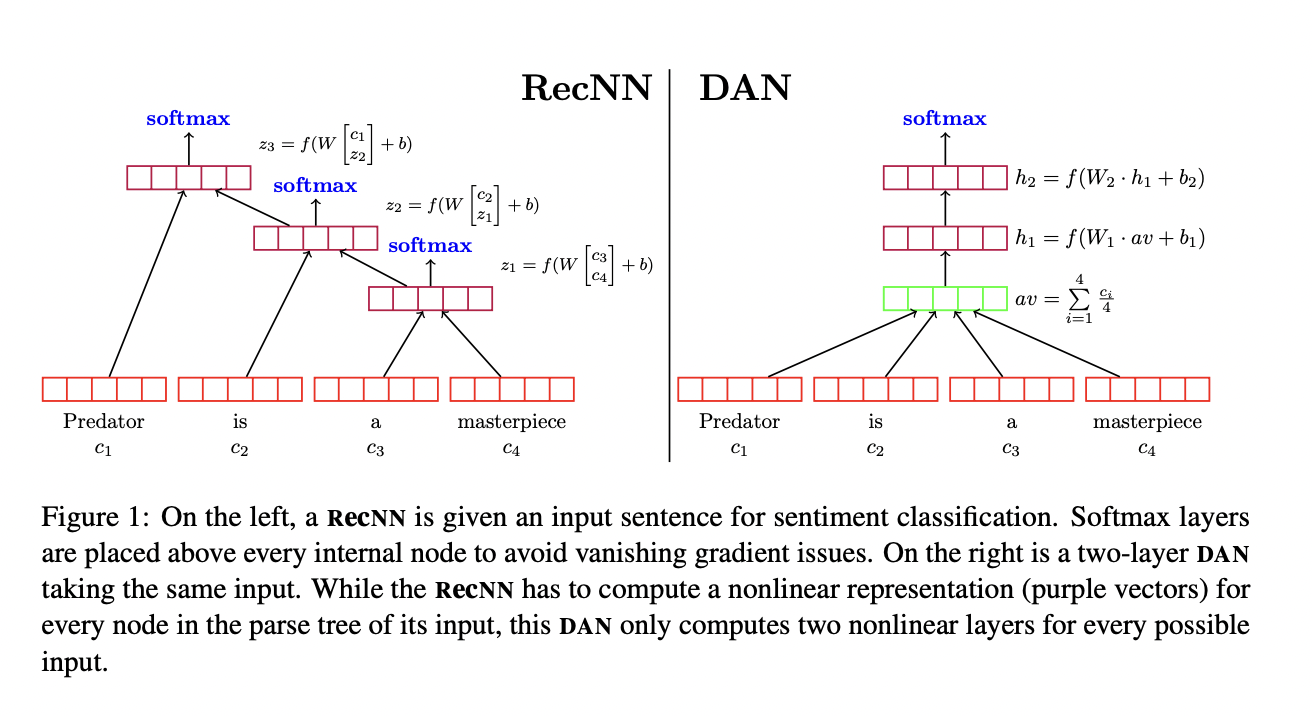
3. Deep Averagin Networks
Deep feed-forward neural networks의 포함된 직관은 각 layer 층들이 이전 층에 비해 input의 추상적인 representation을 학습한다는 것입니다. 해당 논문에서는 2.1에서 소개한 NBOW에 이러한 개념을 적용하여 word embedding의 평균에서 작지만 의미적으로 큰 차이가 점점 더 부각될 수 있는 것을 기대하였습니다.
이는 앞서 언급한 z를 바로 output layer로 보내는 것이 아닌, softmax 적용 전 다양한 layer를 적용시켜 구현하였습니다. 그 후 최종적으로 얻게 되는 z_n을 softmax layer의 input으로 활용하였습니다.
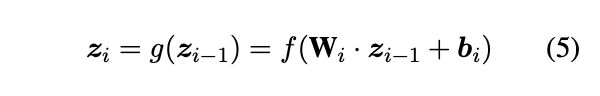
DAN(Deep Averaging netword)로 불리는 모델은 여전히 unordered하지만, 기존의 NBOW 모델에 비해 여러개의 layer층을 활용하여 input들의 사소한 차이를 잡아낼 수 있습니다. 각 layer에서는 하나의 행렬 곱만 계산하면되기 때문에 parse tree node들의 계산보다는 효율적입니다. 따라서 shallow NBOW 모델과 DAN의 학습 시간에는 큰 차이를 보이지 않았습니다.
3.1 Word Dropout Improves Robustness
Dropout은 p의 확률로 랜덤하게 hidden and/or input units를 0으로 만들어 신경망을 regularize합니다. Dropout은 parameter를 공유하는 서로 다른 2^n개의 앙상블을 만들어 overfitting을 방지합니다. DAN에서는 word embedding 전체를 평균구하기 전에 drop 시킵니다. 이러한 방식을 word dropout이라고 합니다.

Out label을 예측하는 데 중요하게 활용되는 단어의 수는 그렇지 않은 단어의 수에 비해 작기 때문에 이러한 방식은 성능 향상에 도움이 됩니다. 이론적으로 Word dropout은 다른 neural netword-based 방식에 사용될 수 있습니다.
4. Experiments
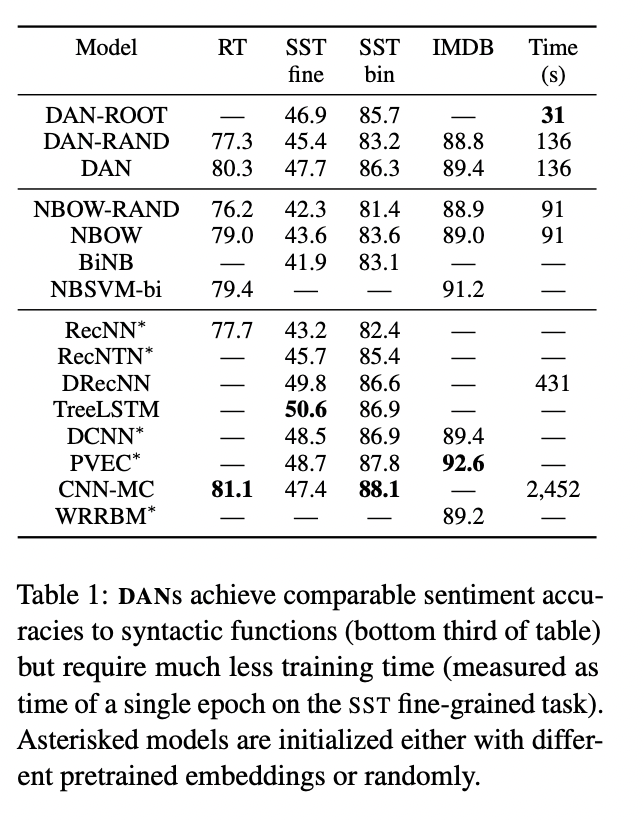
DAN을 shallow NBOW 뿐만 아니라 다양한 더욱 복잡한 syntactic model들과 성능 비교를 진행합니다. 실험을 통해서 DAN은 적은 학습시간만으로도 bag-of-words 모델들과 많은 syntactic 모델들의 성능을 뛰어넘었습니다.
4.1 Sentiment Analysis
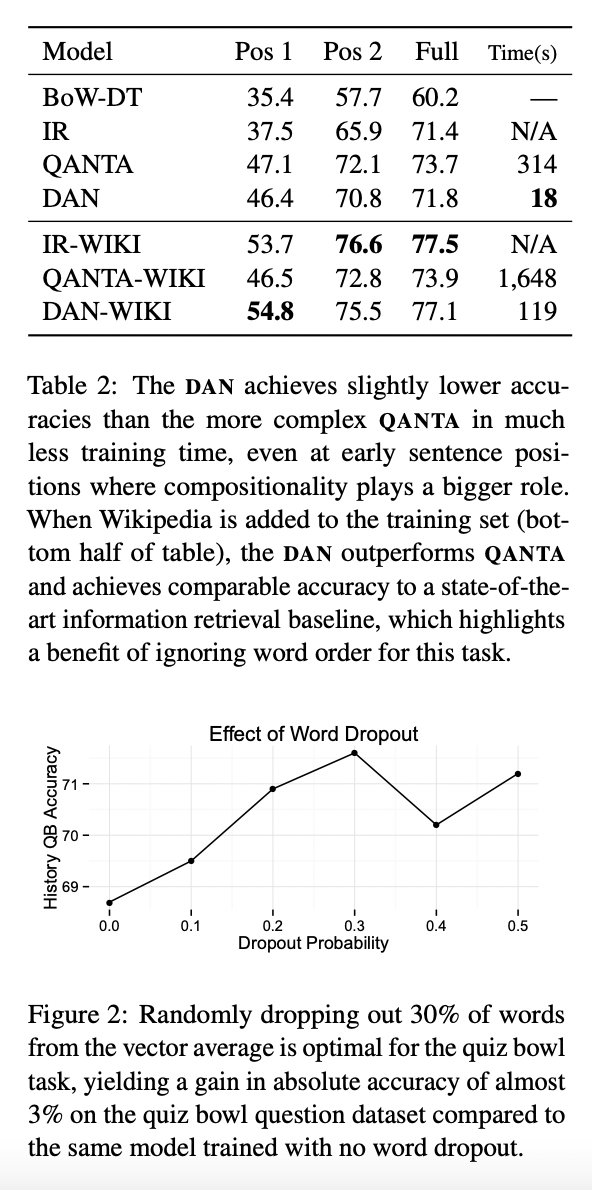
4.2 Factoid Question Answering
5. How Do DANs Work?
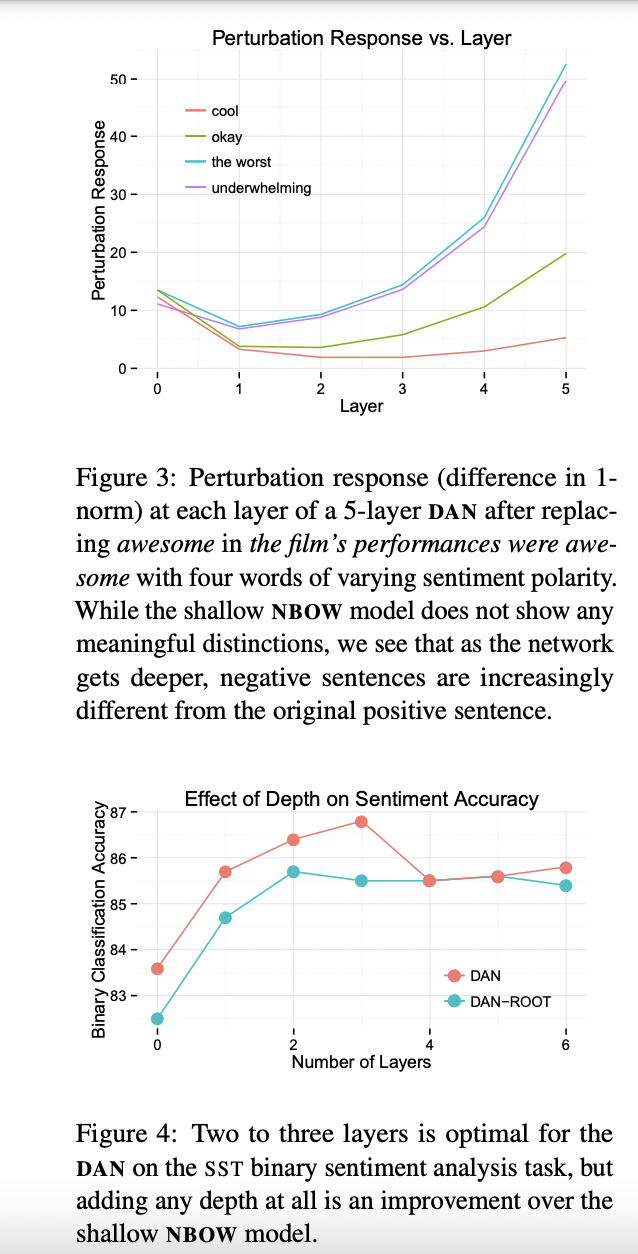

6. Related Work
DAN 모델은 단순한 vector 연산과 compositionality를 위한 network-based model 모든 측면에서 성공을 보였습니다.
DAN에서는 embedding의 평균을 구했지만, 또 다른 deep neural network를 사용할 수도 있을 것입니다.
7. Future Work
8. Conclusion
해당 논문에서는 최종 분류 layer 이전에 여러개의 layer의 input으로 word vector들의 단순평균 vector를 활용하는 DAN을 소개하였습니다. DAN은 복잡한 neural network들과 견줄만한 성능을 보였습니다. DAN은 input redundancy를 줄이는 word dropout을 통해 성능을 높일 수 있습니다.
