Context-dependent, 즉 문맥 의미를 담은 word embedding을 얻을 수 있는 ELMo를 소개하는 논문입니다. biLM을 활용하여 biLM의 모든 layer output을 활용하며 각 layer 별 서로 다른 정보를 encode한다는 것을 보였습니다.
[Abstract]
해당 논문에서는 (1) 단어 사용의 복잡한 특성(ex. 문법, 의미) (2) 문맥에서 어떻게 다양하게 사용되는지(ex. 다의어) 2가지 특성을 모두 반영하는 새로운 deep contextualized word representaion을 소개합니다. 해당 논문의 word vector는 매우 큰 말뭉치에서 미리 학습된 deep biLM(bidirectional language model)의 internal state들의 함수로 학습됩니다. 이렇게 얻은 representation은 기존에 존재하는 많은 model에 쉽게 활용할 수 있으며 6가지 NLP task들에서 SOTA 성능을 보였습니다. 또한 해당 논문에서는 미리 학습된 network의 deep internal을 모두 활용하는 것이 중요하다는 것을 보였습니다.
1. Introduction
미리 학습된 word representation은 많은 NLU 모델들의 주된 요소입니다. 하지만 좋은 성능을 갖는 word representation을 학습하는 것은 매우 어렵습니다. 왜냐하면 word representation이 (1) 단어 사용의 복잡한 특성(ex. 문법, 의미) (2) 문맥에서 어떻게 다양하게 사용되는지(ex. 다의어) 2가지 특성을 모두 반영해야하기 때문입니다. 해당 논문에서는 이러한 문제를 해결함과 동시에 기존 모델들에 쉽게 활용할 수 있으며, SOTA 성능을 보인 새로운 deep contextualized word representation을 소개합니다.
논문의 representation은 각 token들이 전체 input sentence의 representation으로 표현된다는 점에서 기존의 word embedding과 다릅니다. 해당 논문에서는 매우 큰 말뭉치에서 한 쌍의 LM을 목적으로 하는 bidirectional LSTM으로부터 얻어지는 vector를 사용합니다. 이러한 이유에서 해당 논문에서는 이를 ELMo(Embedding from Language Models) representation이라 이름붙였습니다.
ELMo representation은 biLM의 모든 internal layer들의 함수이기 때문에 deep하다고 볼 수 있습니다. 더 나아가 해당 논문에서는 각 최종 task를 위한 각각의 input word에서 얻어지는 vector들의 linear combination을 학습하였습니다. 이를 통해 LSTM의 최상단 layer만 사용하는 것보다 더 나은 성능을 얻을 수 있었습니다.
모든 internal states를 합친 이러한 방식은 풍부한 word representation을 얻을 수 있도록 해주었습니다. 평가를 통해 해당 논문에서는 higher-level LSTM은 단어 의미의 context-dependent한 특징을 잡아내고 lower-level LSTM은 syntax적인 특징을 잡아낸다는 것을 발견하였습니다. 동시에 이러한 모든 특징을 활용하는 것이 이점이 크다는 것을 보였습니다.
추가적인 실험을 통해 ELMo representation은 기존 model들에서 쉽게 활용할 수 있다는 것을 보였습니다. 마지막으로 deep representation이 LSTM의 top layer만 사용하는 것보다 더 좋은 성능일 좋다는 것도 알 수 있었습니다.
2. Related work
매우 큰 unlabeled text로부터 단어의 의미적, 문법적 정보를 잡아낼 수 있기때문에 pretrained word vector는 최근의 SOTA NLP 구조의 주된 요소입니다. 하지만 이러한 방식으로는 기존의 방식들로는 각 단어들의 single context-independent한 word vector만 학습할 수 있었습니다.
과거 제안된 몇가지 방식들은 subword information을 활용하거나 각 word sense마다 서로 다른 vector를 학습하여 기존 word vector의 단점들을 극복하고자 했습니다. 해당 논문에서 사용한 방식은 character convolution을 활용하여 subword unit의 이점을 얻을 수 있었고, downstream task에 자연스럽게 multi-sense information을 통합할 수 있었습니다.
또 다른 최근 연구에는 context-dependent representation에 집중하였습니다. Context2Vec은 bidirectional LSTM을 활용하여 pivot word의 문맥을 encode하였습니다. CoVe에서는 contextual embedding을 학습하기 위해 pivot word 자체를 representation에 포함시키고 supervised neural machince translation system을 통해 계산되었습니다.
과거 연구에서는 또한 deep biRNNs에서 각 layer들이 서로 다른 정보를 encode한다는 것을 보였습니다. 해당 논문에서는 ELMo representation의 modified language model objective를 통해 유사한 현상을 볼 수 있었고, 서로 다른 특징을 섞어서 downstream task model을 학습할 때 이점을 얻을 수 있었습니다.
해당 논문에서는 biLM을 unlabeled data를 통해 pretrain한 후 weight를 고정한채로 task-specific model을 추가하여 biLM representation의 일반적이고 풍부한 특징을 사용하고자 했습니다.
3. ELMo: Embeddings from Language Models
ELMo word representation은 모든 input sentence들의 함수입니다. ELMO word representation은 character convloution을 활용하여 internal networ state들의 linear function으로서 two-layer biLM으로 계산됩니다. 많은 data로부터 biLM을 pretrain하여 semi-supervised learning을 활용할 수 있게 해주었고, 기존에 존재하는 neural NLP 구조에 손쉽게 활용할 수 있었습니다.
3.1 Bidirectional language models
N개 token들의 sequence가 (t1 ~ t_N)으로 주어졌을 때, forward language model은 (t_1 ~ t(k-1))이 주어졌을 때 t_k의 등장 확률을 계산합니다.
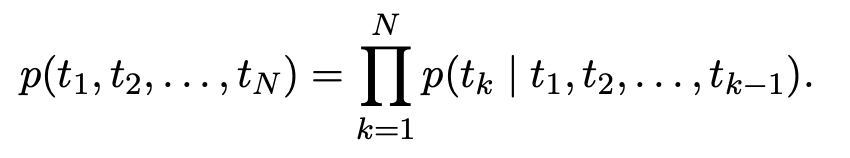
최근 SOTA neural language model들은 context-independent token representation (xk)^LM을 token embedding이나 character CNN을 통해 얻은 후 이를 L-layer forward LSTM에 넣어줍니다. 각 position k마다 LSTM layer는 context-dependent representation (h_k,j)^LM을 output으로 만들어냅니다. LSTM의 최상단 layer는 (h_k,L)^LM을 output으로 가지며 이는 Softmax layer를 통해 다음 token t(k+1)을 예측하는데 사용됩니다.
backward LM은 forward LM과 유사하지만 sequence를 반대방향으로 활용합니다. 즉, 미래의 context를 통해 과거 token을 예측합니다.

biLM은 foward LM과 back LM 2가지를 결합합니다. 해당 논문에서는 아래 식과 같이 forward와 backward 모두의 log likelihood를 jointly하게 최대화합니다.
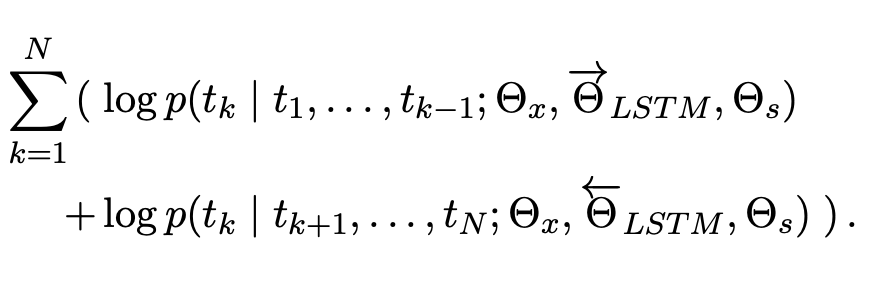
해당 논문에서는 forward와 backward에서 동일한 toke represenation parameter(theta_x)와 softmax layer parameter(theta_s)를 사용하였지만 각 방향의 LSTM parameter는 다르게 두었습니다.
3.2 ELMo
ELMo는 biLM의 모든 intermediate layer representation의 combination입니다. 각 token t_k마다 L-layer biLM은 2L+1(각 LM마다 L개의 result * 2개의 LM + 1개의 token embedding)개의 representaion을 계산합니다.

Downstream model에 사용할 수 있도록 ELMo는 모든 layer를 합하여 single vector로 만들어줍니다. ELMO_k = E(R_k;theta_e) 가장 단순한 case는 ELMo를 top layer out으로 활용하는 것입니다. E(R_k) = (h_k,L)^LM
하지만 일반적으로 모든 biLM layer들을 weight를 활용하여 계산합니다.


각 biLM layer들의 activation들이 모두 다른 분포를 가질 수 있기 때문에, biLM layer들을 weighting 하기 전에 layer normalization을 사용하는 것이 도움이 될 수 있습니다.
3.3 Using biLMs for supervised NLP tasks
pre-trained biLM과 특정 task의 NLP구조가 주어진다면 task model의 성능을 높이기 위해 biLM을 사용하는 것은 단순합니다. 해당 논문에서는 biLM을 수행하여 각 단어에서 얻어지는 모든 layer들의 representation을 기록하였습니다. 그 후 최종 task model에서 이러한 representation의 linear combination을 학습하도록 하였습니다.
첫째, biLM이 없는 supervised model의 최하단 layer를 생각해봅시다. 대부분의 supervised NLP model들에서 최하단 layer에서 유사한 구조를 보입니다. 이는 곧, ELMo를 일정하고 동일한 방식으로 추가할 수 있도록 해줍니다. (t_1 ~ t_N) token sequence가 주어졌을 때, pre-trained word embedding과 선택적으로 character-based representation을 사용하여 각 token의 context-independent token representation x_k를 만드는 것이 일반적입니다. 그 후 model은 context-sensitive representation h_k를 bidirectional RNN, CNN, feed forward network를 활용하여 얻습니다.
Supervised model에 ELMo를 추가하기 위해 해당 논문에서는 먼저 biLM의 weight들을 고정시킨 후 ELMo vector (ELMo_k)^task를 x_k와 concate한 후 concate된 ELMo enhanced representation (x_k;(ELMo_k)^task)를 task RNN에 넣어줍니다.
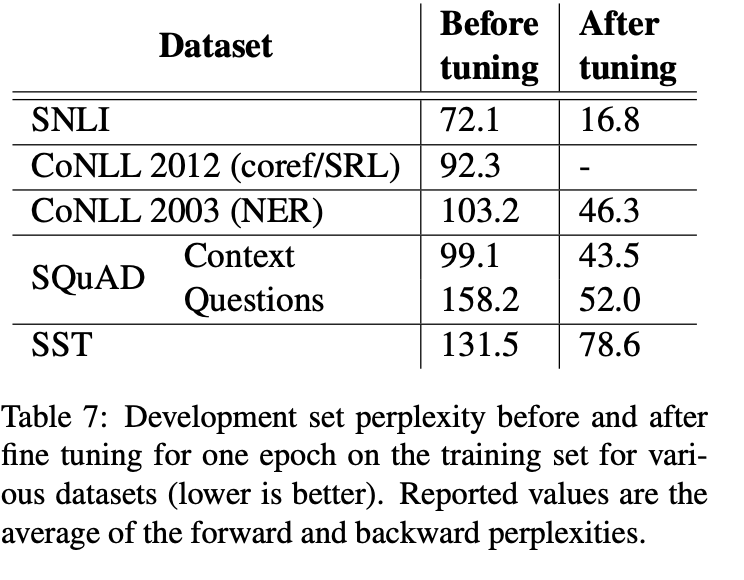
마지막으로, 해당 논문에서는 ELMo에 적당한 dropuout을 추가하는 것이 도움 된다는 것을 알아냈습니다. 또한 몇몇 경우 ELMo weight에 L2 regularization을 추가하는 것 역시 도움이 되었습니다.
3.4 Pre-trained bidirectional language model architecture
최종 model은 4096개 unit과 512 dimension projection을 갖는 L=2 biLSTM layer를 활용하였고 첫번재와 두번째 layer 사이에 residual connection을 활용했습니다. Context nisensitive type representaion은 2048 character n-gram convolutional filter를 사용한 후 2개의 highway layer를 적용한 후 512 representation으로 linear projection 시켜주었습니다.

4. Evaluation
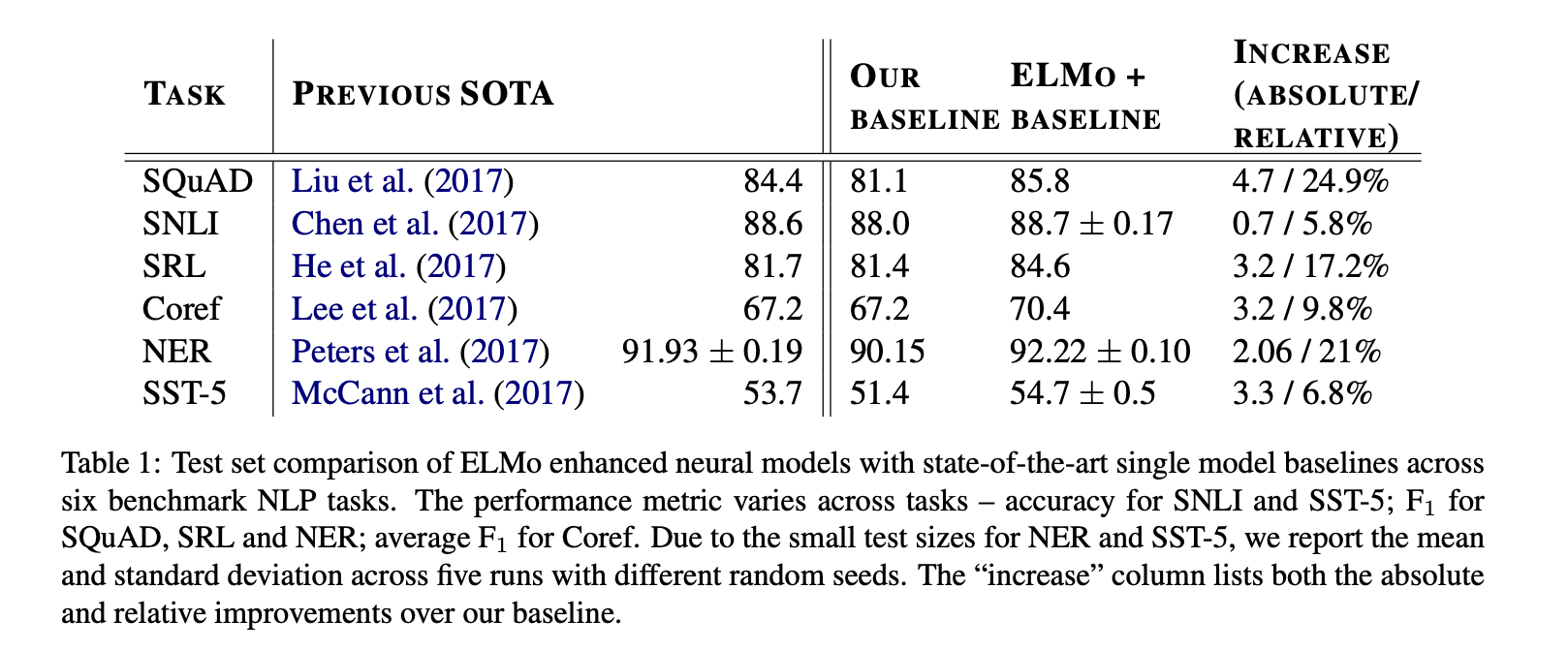
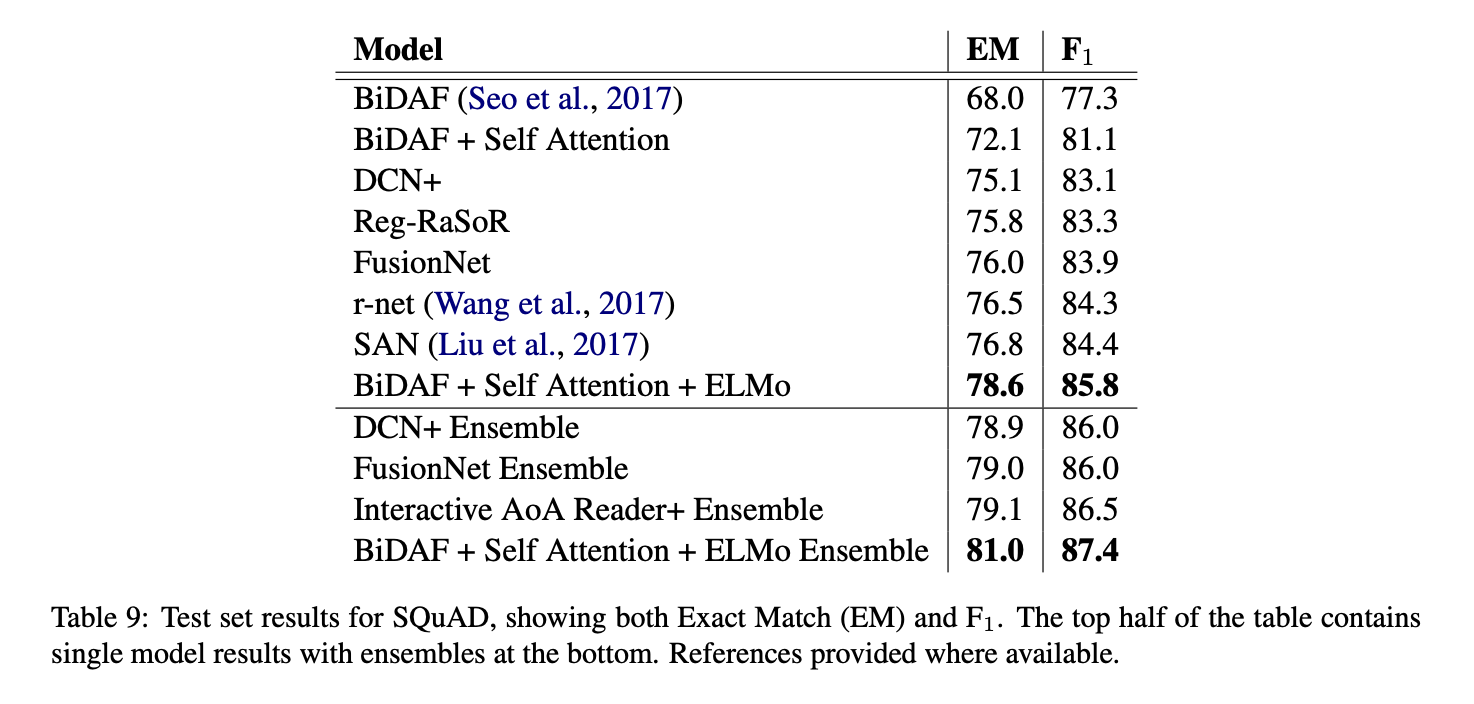
Question anwering
Textual entailment

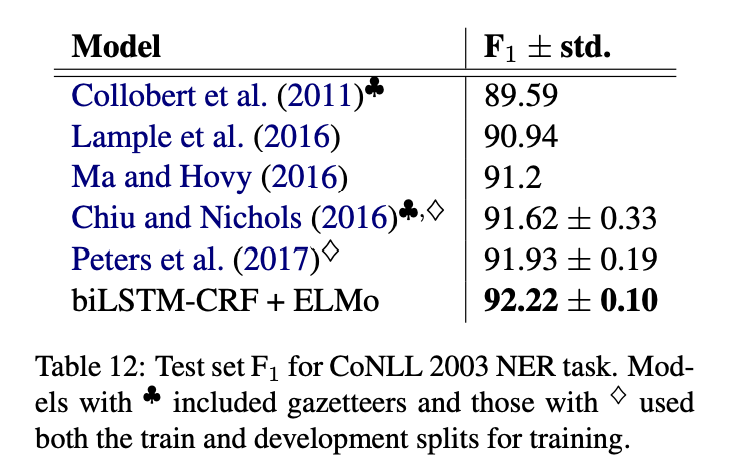
Semantic role labeling
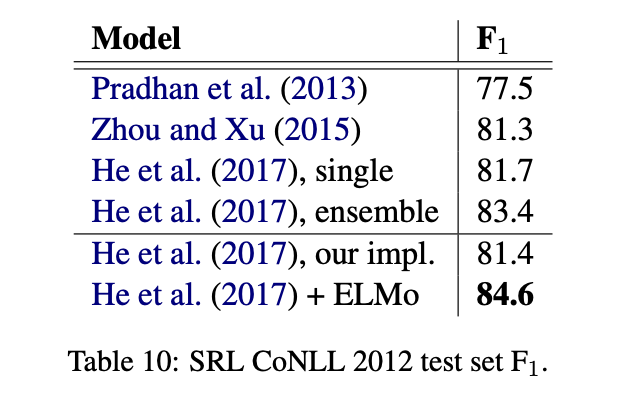
Conference resultion
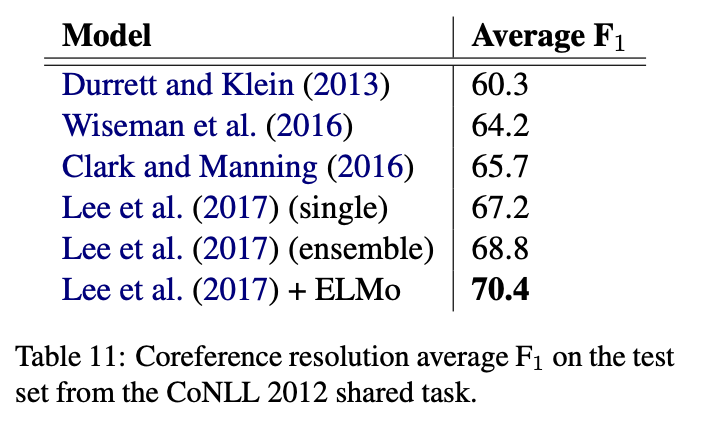
Named entity extraction
Sentiment analysis
5. Analysis
Deep contextual representation을 downstream task에 사용하면 biLM이나 MT encoder에서 최상단 layer의 결과만 사용했던 이전 결과보다 성능이 좋아지는 것을 볼 수 있습니다.
biLM에서 서로 다른 contextual information이 다른 layer에서 잡힌다는 것을 확인할 수 있고, syntactic information은 lower layer에서 semantic information은 higher layer에서 잡히는 것을 확인할 수 있었습니다.
또한 해당 논문의 biLM은 일정하게 CoVe보다 풍부한 representation을 갖는다는 것을 알 수 있었습니다.
5.1 Alternate layer weighting schemes
biLM layer를 결합하기 위한 방식으로 식1 이외에서 많은 방법들이 있습니다. 과거 연구들에서는 오직 최상단 layer의 output만 활용했었습니다. Regularization parameter lambda를 선택하는 것도 중요했습니다. lamda = 1과 같이 커질 수록 weighting function을 각 layer의 단순 평균을 하는 것과 같이 단순화한 반면 lamda = 0.001과 같이 아주 작은 값일 수록 layer의 weight 값들이 다양해졌습니다.
모든 layer의 representation을 포함하는 것이 최상단 layer 결과만 사용하는 것보다 성능이 좋았습니다.

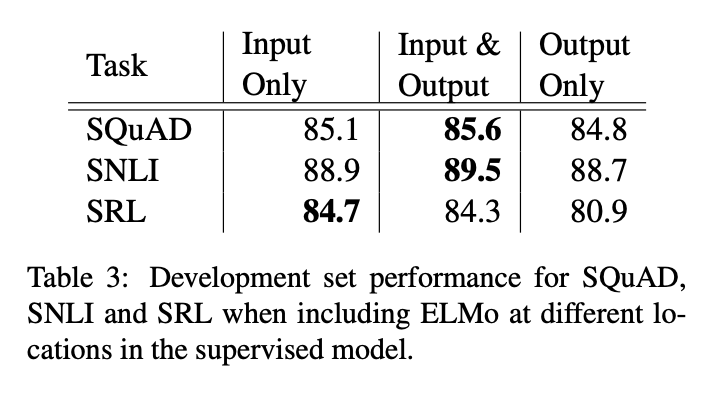
5.2 Where to include ELMo?
해당 논문의 모든 task 구조에서 word embedding은 biRNN 최하단 layer의 input으로만 활용됩니다. 하지만 task-specific 구조의 biRNN output에 ELMo를 포함하는 것은 전반적인 성능 향상을 보였습니다.
5.3 What information is captured by the biLM's representation
biLM의 contextual representation은 word vector에서 잡을 수 없는 NLP task들에 일반적으로 효율적인 정보를 encode해야만 합니다. biLM은 문맥을 통해 단어의 의미 모호성을 줄여줍니다.

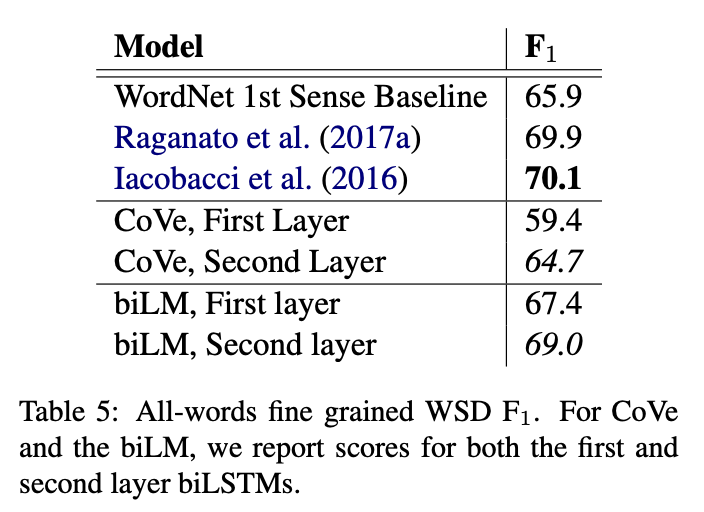
Word sense disambiguation
문장이 주어졌을 때, biLM representation을 1-nearest neighbor 방식을 사용하여 target word의 의미를 예측하는 데 사용할 수 있습니다.
POS tagging
biLM이 기본적인 syntax를 잡아내는지 확인하기 위해 context representation을 input으로 하여 POS tag를 예측하도록 하였습니다.
Implications for supervised tasks
실험들을 통하여 biLM의 서로 다른 layer들은 서로 다른 정보를 나타낸다는 것을 알 수 있고 biLM의 모든 layer를 포함하는 것이 downstream task성능 향상에 도움을 주는 지 알 수 있었습니다.
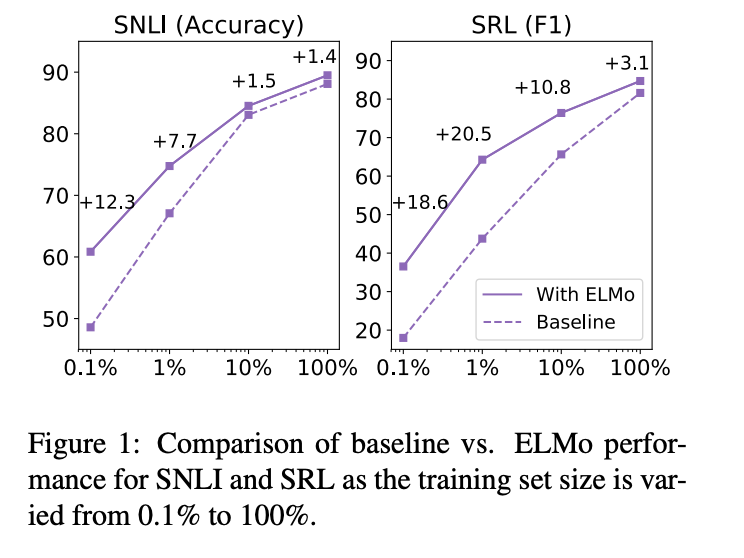
5.4 Sample efficiency
ELMo를 model에 추가하는 것은 parameter update와 training set size 모두 효율적으로 할 수 있도록 해줍니다. ELMo-enhanced model은 더 적은 training set을 ELMo가 없는 model보다 효율적으로 활용하였습니다.
5.5 Visualization of learned weights

6. Conclusion
해당 논문에서는 biLM으로부터 high-quality deep context-dependent representation을 학습하는 방법을 소개하였습니다. 뿐만 아니라 ELMo를 다양한 NLP task에 적용하여 성능 향상을 이룰 수 있다는 것을 보였습니다. biLM layer는 효율적으로 syntatic, semantic information을 encode하고 모든 layer을 활용하는 것이 모든 task 성능 향상에 도움을 준다는 것을 확인하였습니다.
