Seq2Seq를 소개하는 논문입니다. Input의 단어 순서를 뒤집어줌으로써 long sentence에서도 학습이 잘 될 수 있고, 성능 향상도 달성할 수 있다는 것을 보여주는 논문입니다.
[Abstract]
DNN(Deep Neural Network)는 까다로운 learning task에도 훌륭한 성능을 보이는 강력한 model입니다. DNN이 크기가 큰 labeling train dataset이 사용가능할 때는 훌륭한 성능을 보이지만 sequences to sequences mapping에서는 사용할 수 없었습니다. 해당 논문에서는 general end-to-end sequence learning을 소개합니다. 소개하는 방법에서는 multiyaered LSTM(Long Short-term Memory)를 사용하여 input sequece를 고정된 차원의 vector로 mapping 시키며 또 다른 deep LSTM은 이렇게 만들어진 vector를 통해서 target sequecne로 decode를 수행합니다. 추가적으로 LSTM은 long sentence에 대해서도 큰 문제가 없었습니다. 또한 LSTM은 단어의 순서에 민감한 phrase, sentence representation을 학습하였습니다. 마지막으로 해당 논문에서는 모든 source sentence들의 단어 순서는 뒤집지만 target sentence 단어 순서는 유지하는 방식을 활용하여 LSTM의 성능을 눈에 띄게 증가시킬 수 있었습니다. 이러한 방식을 통해 source sentecne와 target sentence 사이의 short term dependency를 만들어 최적화를 쉽게 할 수 있기 때문입니다.
1. Introduction
DNN은 까다로운 문제에도 좋은 성능을 갖는 강력한 machine learning model 입니다. DNN은 또한 step마다 parallel computation이 가능하다는 장점을 지니고 있습니다. Neural network가 기존의 statistical model과 관련이 있지만 neural network는 좀 더 복잡한 연산을 학습할 수 있습니다. Large DNN은 labeling되어 있는 training set이 network의 parameter들을 특정할 수 있는 정보를 충분히 지니고 있다면 supervised backpropagation을 활용하여 학습될 수 있습니다. 만약 좋은 성능을 갖는 large DNN의 parameter setting을 알고 있다면 supervised backpropagation은 이러한 prameter를 찾을 수 있고, 문제를 해결할 수 있습니다.
DNN은 input과 target이 고정된 차원의 vector로 encoding이 잘 될 수 있는 문제에만 활용할 수 있습니다. 대부분의 중요한 문제들이 길이를 사전에 알 수 없는 sequence로 표현되는 경우가 많기 때문에 고정된 차원의 vector를 필요로 한다는 것은 매우 큰 제약사항이 됩니다. 그러므로 sequece to sequence mapping을 할 수 있는 domain-independent method를 매우 유용합니다.
DNN은 input와 output의 차원을 고정된 값으로 알고 있어야하기 때문에 sequence는 다루기 매우 어렵습니다. 해당 논문에서는 LSTM architecture를 활용하여 general sequence to sequence 문제를 해결할 수 있다는 것을 보여줍니다. 주된 아이디어는 한 LSTM은 input sequence를 timestep마다 읽어 고정된 길이의 vector representation을 만들어주고, 또 다른 LSTM은 앞서 얻은 vector representation을 활용해 output sequence를 얻습니다. 두번째 LSTM은 input sequence를 활용한다는 점을 제외하고서는 본질적으로 recurrent neural network language model입니다. LSTM은 long range dependency를 지닌 data에서도 학습을 성공적으로 할 수 있기 때문에 input과 output 사이의 상당한 time lag가 존재하는 상황에서는 좋은 선택지로 사용할 수 있습니다.
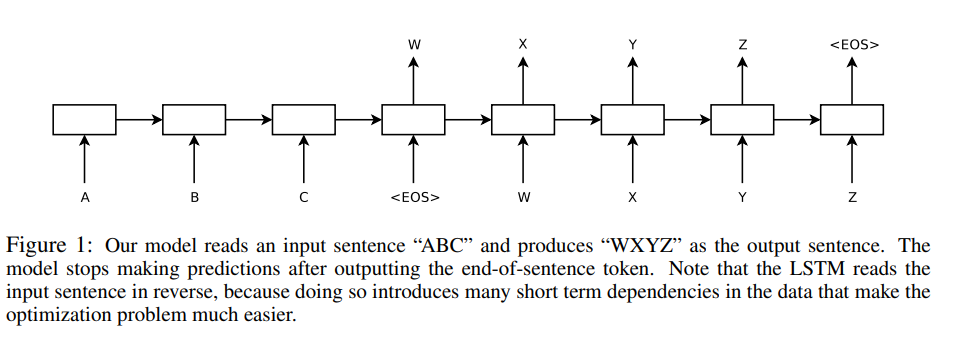
유사한 architecture를 사용했던 기존 연구들에서 long sentence에 있어서는 문제가 많았지만 해당 논문에서는 LSTM에서 long sentence로 인해 발생하는 문제는 없었습니다. Source sentence의 단어 순서를 뒤집고, target sentence의 단어 순서는 유지하여 train과 test에 활용하여 long sentence에서 발생하는 문제를 해결할 수 있었습니다. 이 방식을 통해 최적화 문제를 간단하게 만들어주는 short term dependency를 많이 줄 수 있었습니다. 해당 논문의 주된 contribution 중 하나는 source sentence의 단어 순서를 뒤집어 주는 단순한 trick입니다.
LSTM의 유용한 특징 중 하나는 고정되어 있지 않은 길이의 input sentence를 고정된 차원의 vector representation으로 mapping할 수 있다는 것입니다. Translation이 source sentence의 paraphrase를 찾는 것으로 생각해보았을 때, translation의 objective는 LSTM이 의미를 포함하는 sentence representation을 찾아 유사한 것들은 가깝게 두고, 다른 문장들은 거리를 멀게 두는 것으로 생각해볼 수 있습니다.
2. The Model
RNN(Recurrent Neural Network)는 feedforward neural network를 sequence로 일반화한 것입니다. RNN은 input (x_1 ~ x_T)가 주어졌을 때 아래의 계산을 통해 output (y_1 ~ y_T)를 얻습니다.
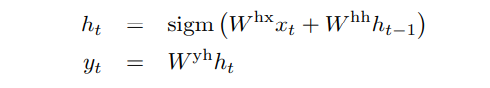
RNN은 input과 output 사이의 alignment가 time에 따라 알려져 있을 때 손쉽게 sequence to sequence mapping을 수행할 수 있습니다. 하지만 input과 output의 길이가 다르고 복잡하고 non-monotonic relation이 있을 때는 RNN을 활용하기에는 한계가 있습니다.
일반적인 sequence learning을 위한 단순한 방법은 input sequence를 고정된 길이의 vector로의 변환을 하나의 RNN이 수행하고 만들어진 vector를 target sequence로 바꿔주는 역할을 또 다른 RNN이 수행하는 것입니다. 하지만 RNN을 long term dependency가 있는 상황에서는 학습을 제대로 할 수 없습니다. 하지만 LSTM은 long term dependency를 학습한다고 알려져 있습니다.
LSTM의 목적은 T와 T'이 다른 값을 때 input (x_1 ~ x_T), output (y_1 ~ y_T')에 대해 조건부 확률 p(y_1 ~ y_T' | x_1 ~ x_T)을 추정하는 것입니다. LSTM은 input (x_1 ~ x_T)으로부터 마지막 hidden state인 fixed representation v를 얻고, 이 값을 초기 hidden state로 활용하는 standard LSTM-LM을 통해 output 원소들의 확률을 계산합니다.
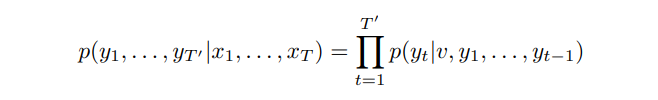
각 문장의 끝은 <E.O.S>라는 특별한 token을 붙여주고 하나의 문장을 구분할 수 있도록 해줍니다.
해당 논문에서 소개하는 모델은 실질적으로 3가지 측면에서 위의 모델과는 다릅니다.
- 2개의 다른 LSTM을 사용합니다. 하나는 input sequence를 위한 것이고, 다른 하나는 output sequence를 위한 것입니다. 이를 통해 계산 비용에는 큰 차이를 만들지 않으면서 model parameter를 늘릴 수 있고 LSTM이 다양한 language pair에 대해서도 학습을 할 수 있도록 해줍니다.
- Deep LSTM이 Shallow LSTM보다 성능이 좋기 때문에 LSTM with four layer를 활용합니다.
- Input sequence의 단어 순서를 뒤집어 줍니다.
3. Experiments
3.1 Dataset details
해당 논문에서는 고정된 크기의 vocabulary를 사용했습니다. Source language에서는 자주 사용되는 160,000개의 단어를 사용하고, target language에서는 자주 사용하는 80,000개 단어를 사용하였습니다. OOV에 대해서는 UNK token을 사용하였습니다.
3.2 Decoding and Rescoring
실험의 핵심은 large deep LSTM을 여러개의 문장 pair에 대해 학습하는 것입니다. 해당 논문에서는 이를 source sentence S가 주어졌을 때 제대로 된 translation T의 log probability를 최대화하는 방식으로 학습하였습니다.

3.3 Reversiong the Source Sentences
LSTM이 long term dependency가 있는 문제 해결에 사용할 수 있지만 해당 논문에서는 target sentence는 유지한 채 source sentence의 순서를 뒤집었을 때 LSTM이 학습을 더 잘 한다는 것을 발견했습니다.
이러한 현상에 대해 명확한 이유를 설명할 수는 없지만, dastaset 사이에 여러개의 short term dependency를 만들 수 있었기 때문이라고 생각하고 있습니다. 단어 순서를 뒤집지 않았을 때는 source sentence를 target sentence와 붙였을 때 대응 하는 각 단어들의 거리가 매우 멀다는 것을 알 수 있습니다. 하지만 source sentence의 순서를 뒤집음으로써 모든 단어들 사이의 거리 평균을 크게 차이가 나지 않더라고 대응 하는 단어들 간의 거리가 가까워진 것들이 많아지게 됩니다.
3.4 Training details
- Deep LSTM with 4 layers with 1000 cells at each layer
- 1000 dimensional word embedding
- 160,000 input vocabulary
- 80,000 output vocabulary
- Initialize LSTM's parameter with the uniform distribution [-0.08, 0.08]
- SGD without momentum
- Fixed learing rate 0.7, After 5 epochs halving the learning rate every half epoch
- total 7.5 epochs
- batches of 128 sequences
- constraint on the norm of the gradient [10, 25] by scaling
- all sentences in a minibatch are roughly of the same length
3.5 Parallelization
3.6 Experimental Results

3.7 Performance on long sentences
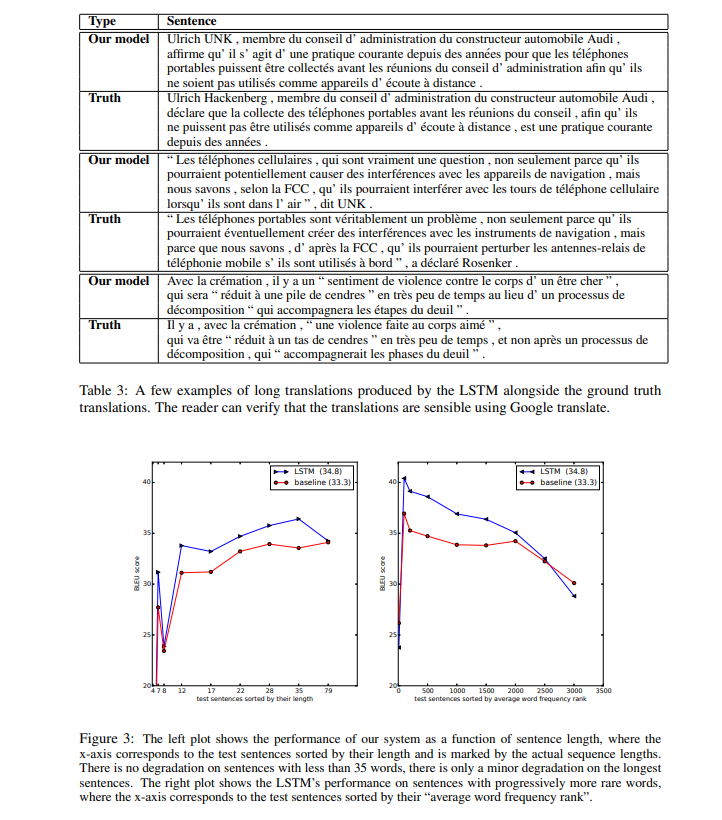
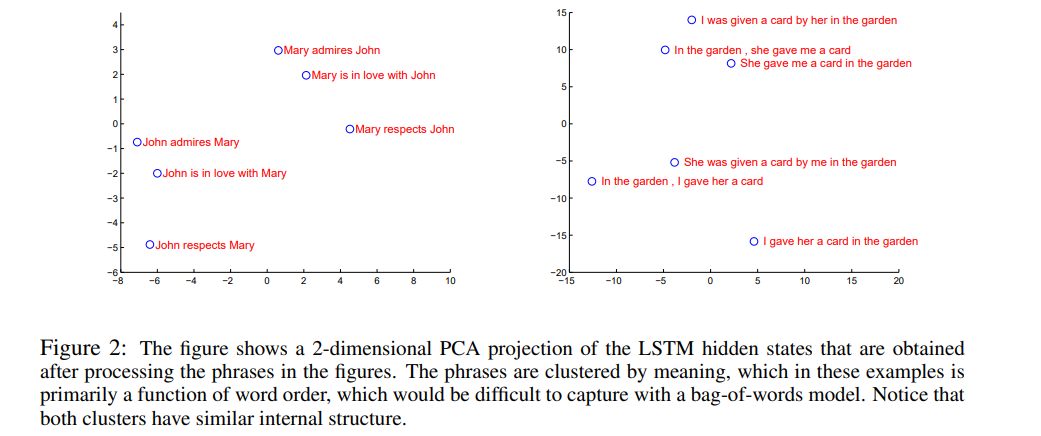
3.8 Model Analysis
4. Related work
5. Conclusion
해당 논문에서는 제한된 vocabulary와 다른 가정을 추가하지 않은 large deep LSTM이 제한되지 않은 vocabulary를 지닌 standard SMT-based system보다 성능이 좋을 수 있다는 것을 보였습니다. 이러한 성공을 바탕으로 또 다른 sequence learning problems에서도 좋은 결과를 보일 수 있다고 기대하고 있습니다.
Source sentence의 단어 순서를 뒤집는 것으로 성능 향상을 이룰 수 있다는 것에 놀랐습니다. 이를 통해 short term dependency가 많아지면 lenarning problem이 단순해지고 encoding에서도 좋은 성능을 보일 수 있다고 생각할 수 있습니다.
LSTM이 매우 긴 문장에 대해서도 translate를 수행하는 것에도 놀랐습니다. 과거 연구들과 제한된 메모리로 인해 LSTM이 긴 문장에 대해서는 학습이 제대로 되지 않을 것이라고 생각하였지만 단어의 순서를 뒤집어줌으로써 LSTM은 긴 문장에 대해서도 학습을 제대로 수행할 수 있었습니다.
