Count-based model과 predict-based model의 장점을 결합하여 비지도 방법으로 word vector를 학습하는 GloVe를 소개하는 논문입니다.
[Abstract]
벡터 연산을 사용하여 단어를 벡터 공간에 표현하는 최근의 방식은 의미와 문법적인 규칙을 포착하는 데 훌륭한 성공을 보이고 있지만 여전히 규칙의 원천이 어디인지는 불투명성이 남아 있습니다. 해당 논문에서는 global matrix factorization과 local context window methods 2개의 주된 모델의 장점을 결합한 global log-bilinear regression model을 소개합니다. 새로운 모델은 word-word co-occurrence 행렬의 0이 아닌 원소들을 학습하여 통계 정보를 효율적으로 활용합니다.
1. Introduction
언어의 semantic vector space 모델은 각 단어를 실수 vector로 표현합니다.
많은 word vector 방법론들은 단어 표현 집합들의 내부적인 quality를 평하기위한 주된 방법으로 word vector 간의 거리나 각도에 의존합니다.
Word vector를 학습하기 위한 주된 2가지 방법은 다음과 같습니다.
- global matrix factorization : LSA(Latent Semantic Analysis)
- local context window methods : Skip-grap model
LSA와 같은 방법은 통계 정보를 효율적으로 활용하지만 word analogy task에서 성능이 좋지 않았습니다. Skip-gram과 같은 방법은 word analogy task에서 성능은 좋았지만, global co-occurrence count 대신에 local context window에서 학습을 하기 때문에 말뭉치의 통계정보를 잘 활용하지 못한다는 단점이 있었습니다.
해당 논문에서는 linear directions of meaning을 만들기에 필수적인 모델의 특성을 분석하고 global log-bilinear regression model이 이를 위해 가장 적합한 모델임을 주장합니다. 해당 논문에서는 global word-word co-occurrence counts를 학습하는 weighted least square model을 제안하고 통계정보를 효율적으로 활용할 수 있도록 하였습니다.
2. Related Work
Matrix Factorization Methods
Matrix fatorization mehods는 저차원의 word representaion을 만들어내는 방법입니다. 이 방법은 말뭉치의 통계 정보를 잡아내는 큰 행렬을 분해하기 위해 low-rank approximation을 사용합니다. 이런 행렬들을 통해 포착되는 정보의 종류는 적용 되는 곳에 따라 달라집니다. LSA에서는 term-document 행렬을 활용합니다. HAL(Hyperspace Analogue to Language)는 term-term 행렬을 활용합니다.
HAL과 유사한 방법론의 주된 문제는 가장 자주 등장하는 단어들이 유사도를 구할 때 비정상적으로 많은 영향을 미친다는 것입니다. 예를 들어, the와 and는 실질적으로 의미의 연관성이 없지만 둘이 동시에 등장하는 횟수가 많기 때문에 둘의 유사도에 큰 영향을 미칩니다. Co-occurrence 행렬을 entorpy- 나 correlation-based 정규화를 활용하여 변환하는 COALS와 같은 모델이 HAL의 단점을 보완하기 위해 등장하였습니다.
Shallow Window-Based Methods
또 다른 방법에서는 local context window 내부에서 예측을 목적으로 하여 word representation을 학습합니다. Word2Vec은 word vector 학습을 위해 간단한 신경망 구조를 활용했습니다.
Skip-gram과 ivLBL 모델에서는 단어가 주어졌을 때 해당 단어의 문맥을 예측하는 것을 목적으로 합니다. 반면에 CBOW와 vLBL 방법에서는 문맥이 주어졌을 때 중심 단어를 예측하는 것을 목적으로 합니다. Word analogy task를 활용한 평가를 통해, 이러한 모델들은 word vector 사이의 linear relationship을 통해 언어적인 pattern을 학습할 수 있다는 것을 보여주었습니다.
Shallow window-based method는 말뭉치의 co-occurrence 통계 정보를 제대로 활용하지 못한다는 단점을 갖고 있습니다.
3. The GloVe Model
말뭉치의 단어 등장 통계 정보는 word representaion을 비지도 학습을 활용하는 방법들이 활용할 수 있는 주된 정보입니다. 하지만 여전히 남아있는 주된 의문사항은 통계 정보를 통해서 의미가 어떻게 만들어 질 수 있으며, 어떻게 결과적으로 얻은 word vector가 의미를 표현할 수 있는가 입니다.
해당 논문에서는 소개된 모델에서 global corpus 통계 정보를 잡아내기 때기 때문에 GloVe라고 부르는 모델을 소개합니다.
해당 논문에서 사용되는 notaion은 아래와 같습니다.
- X : word-word co-occurrence counts
- X_ij : word i가 있는 문맥에서 word j가 등장한 횟수
- X_i : word i가 있는 문맥에서 등장한 모든 단어들의 횟수 = 모든 j들에 대해 X_ij들의 합
- P_ij = P(j|i) = X_ij / X_i : word i가 있는 문맥에서 word j가 등장할 확률
다양한 prove word k가 주어졌을 때, co-occurrence 확률의 비율을 통해 단어들 사이의 관계를 확인할 수 있습니다. 예를 들어, i = ice, j = steam, k = solid 일때, P_ik/P_jk 값은 커집니다. 비슷하게 k = gas와 같이 steam과는 관련이 있지만 ice와는 관련이 없는 단어 k를 선택했을 때는 비율은 작아지게 됩니다. k가 water나 fastion과 같이 양쪽 모두에 관련이 있거나 관련이 없을 경우네는 비율이 1에 가까워지게됩니다.

단순히 확률값 하나만 사용하는 것보다는 확률의 비율을 사용하는 것이 관련있는 단어와 관련 없는 단어를 구분할 때 효율적이며 관련있는 2개 단어 사이를 구분할 때 역시 효율적입니다.
Word vector 학습을 위한 시작점으로 단순 확률보다는 co-occurrence 확률의 비율이 되는 것이 적절합니다.
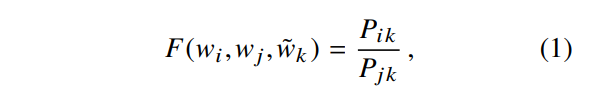
w는 d차원의 word vector이고 w~ 역시 d차원의 context word vector입니다. (1) 식에서 우항은 말뭉치에서 얻을 수 있는 정보이며, F는 아직은 특정되지 않은 parameter들에 의존하게 됩니다. F가 될 수 있는 수는 매우 방대하지만 몇가지 제약조건을 통해 특정 조건을 만족하는 F를 선택할 수 있습니다. 첫째로, F는 확률의 비율이 갖고 있는 정보를 word vector 공간에 ecoding 할 수 있어야 합니다. Vector 공간은 linear structure이기 때문에 가장 자연스러운 방법은 vector 간의 차이를 활용하는 것입니다. 이러한 목적을 위해 함수 F를 2개의 target word의 차이를 input으로 활용하는 것으로 제한하여 (1) 식을 아래의 (2) 식으로 변경할 수 있습니다.
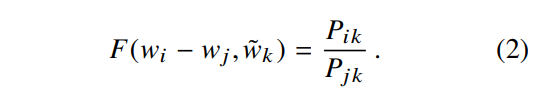
다음으로 (2) 식에서 우항은 scalar이지만 F의 input은 vector임을 확인할 수 있습니다. 이런 문제를 피하기 위해 F의 input들을 dot product하여 아래와 같이 (3) 식으로 변경할 수 있습니다.

다음으로 word-wrod co-occurence 행렬을 활용한다면, 단어간의 차이와 context 단어는 임의로 선택할 수 있으며, 둘의 역할 변경이 언제든지 자유로울 수 있어야 합니다. 안정적으로 이를 수행할 수 있기 위해서는, w를 w~로 변경하는 것을 넘어서 X행렬을 X^t 행렬로 변경할 수 있어야 합니다. 최종 모델은 이러한 역할 변경에 영향을 받지 않아야 하기 때문에 식 (3)은 적합하지 않습니다. 하지만 2 단계를 추가적으로 적용하여 symmetry를 유지할 수 있습니다. 첫째로 함수 F는 groups(R, +)와 groups(R>0, x) 사이의 준동형사상(homomorphism)이어야 합니다.
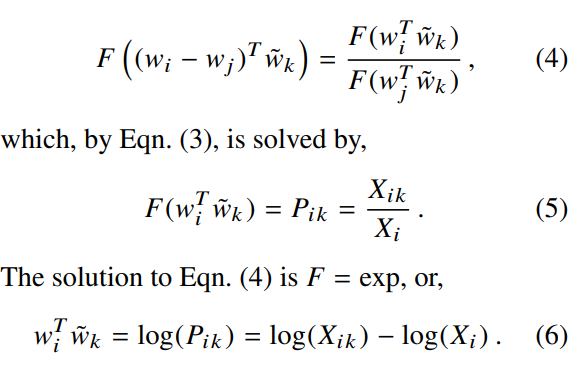
log(X_i)는 k에 독립적이기 때문에, bias b_i로 대체할 수 있으며, bias b_k~를 추가합니다.

식 (7)은 결과적으로 식 (1)을 단순화한 결과입니다. 하지만 X_ik값이 0일 때 log 값이 발산하기 때문에 이를 피하기 위해 log(1+X_ik)로 변경합니다.
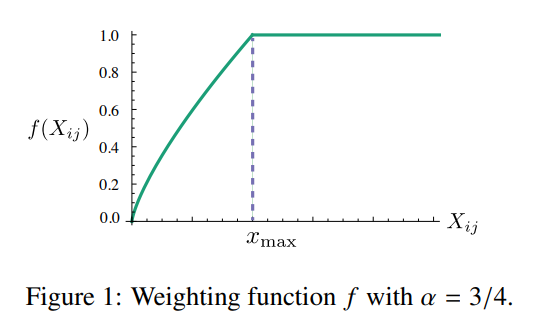
해당 모델은 거의 등장하거나 등장하지 않은 단어들에 대해서도 모두 동일한 가중치를 주고 있다는 단점이 있습니다. 이러한 거의 등장하지 않은 단어들은 노이즈로 볼 수 있으며, 자주 등장하는 단어들과 비교하였을 때 정보가 적게 들어있습니다.
해당 논문에서는 이러한 문제를 다루기 위해 새로운 weighted least squares regression model을 제안합니다. 식 (7)을 least square problem에 적용하고, weighting 함수 f(X_ij)를 도입하여 cost function을 아래와 같이 정의합니다.

3.1 Relationship to Other Models
Word vector를 학습하는 모든 비지도 방법에서는 말뭉치의 occurrence 통계량을 기반으로 하기 때문에, 모델들 간에 유사성이 있습니다.




3.2 Complexity of the model
4. Experiments
4.1 Evaluation methods
Word analogies
Word similarity

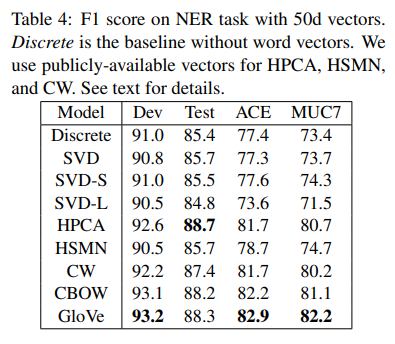
Named entity recognition
4.2 Corpora and training details
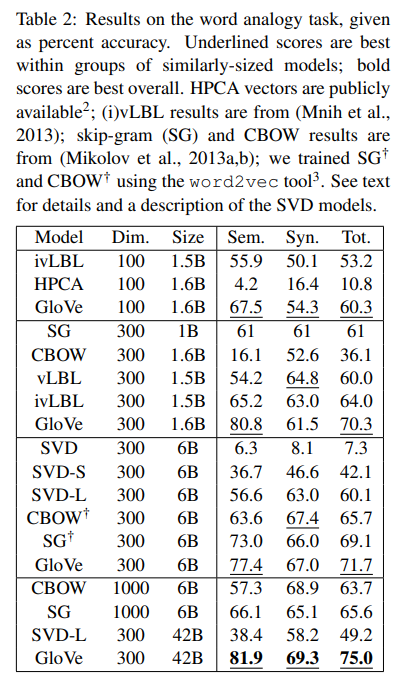
4.3 Results

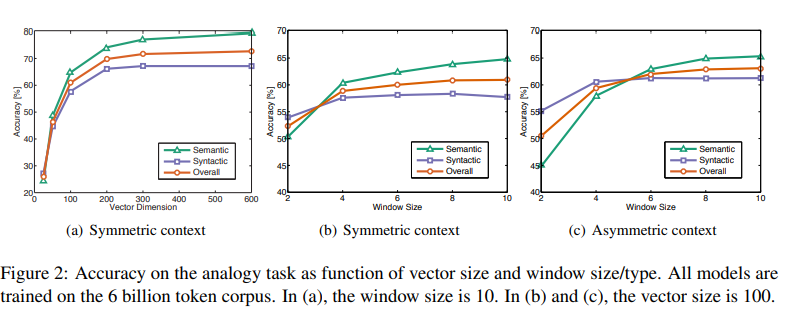
4.4 Model Analysis: Vector Length and Context Size
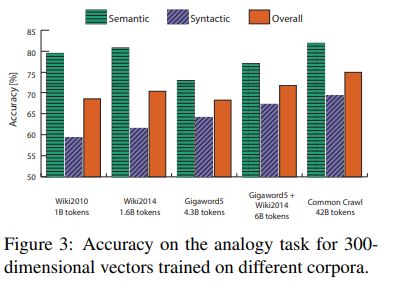
4.5 Model Analysis: Corpus Size
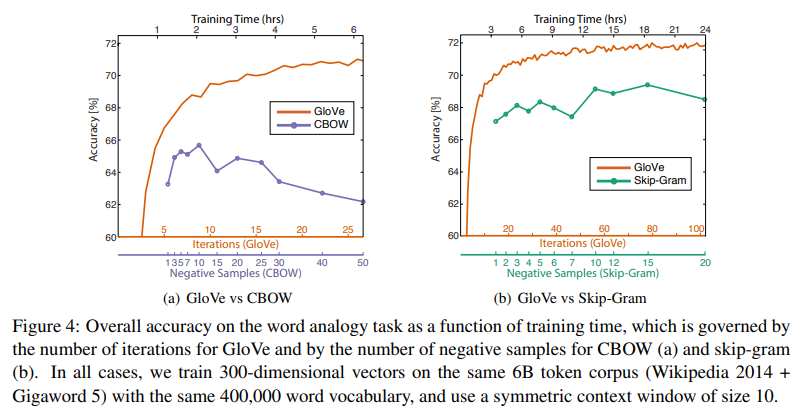
4.6 Model Analysis: Run-time
4.7 Model Analysis: Comparison with word2vec
5. Conclusion
최근에는 상당한 관심이 distributional word representaion이 count-based method랑 prediction-based method 둘 중 어떤 방법이 최선인지에 관한 질문에 있습니다. 해당 논문에서는 두 종류의 방법이 fundamental level에서는 모두 말뭉치의 co-occurrence 통계 정보를 사용하기 때문에 큰 차이가 없지만, count-based methods는 global 통계 정보를 잡아내기 때문에 이점이 있습니다. 해당 논문에서는 이러한 count data의 이점을 활용하면서 동시에 word2vec과 같은 log-bilinear prediction-based methods를 통해 의미있는 linear substructure를 잡아냅니다. 결과적으로 GloVe로 불리는 새로운 word representation을 학습하는 비지도 방법을 위한 new global log-bilinear regression model을 소개했습니다.
