정형 Data 분석에서 파워풀한 성능을 보이는 대표 모델인 XGBoost를 소개하는 논문입니다.
[Abstract]
Tree boosting은 매우 효율적이고 널리 사용되는 ML 방법입니다. 해당 논문에서는 XGBoost로 불리는 scalable end-to-end tree boosting 시스템을 소개합니다. 해당 논문에서는 sparse data를 위한 sparse-aware 알고리즘과 approximate tree learning을 위한 weighted quantile sketch를 소개합니다. 또한, scalable tree boosting 시스템 설계를 위한 cache access patterns과 data compression, sharding의 아이디어를 제안합니다.
1. Introduction
ML과 data-driven 접근법은 다양한 영역에서 중요해지고 있습니다. 성공적인 사용을 위해서는 2가지 중요한 요인이 있습니다.
- 복잡한 data dependecy를 포착할 수 있는 효율적인 (statistical) 모델
- 큰 dataset들로부터 모델을 학습할 수 있는 scalable learning system
Gradient tree boosting은 다양한 영역에서 두각을 나타내는 기술 중 하나입니다.
해당 논문에서는 tree boosting을 위한 scalabe machine learning 시스템인 XGBoost를 소개합니다.
Domain dependent 데이터 분석과 feature engineering은 여전히 중요한 역할을 하고 있지만, XGBoost는 충분히 합리적인 선택이라는 사실은 XGBoost의 영향력과 중요도를 보여줍니다.
XGBoost 성공의 중요한 요인으로는 모든 상황에서 갖고 있는 scalability역량입니다. XGBoost는 존재하는 유명한 다른 방법론들에 비해 10배가량 빠르며, 분산되고 메모리 제한적인 상황에서 10억개의 예제까지 확장될 수 있습니다. XGBoost의 scalability는 몇 개의 중요한 시스템과 알로기즘 최적화 덕분입니다.
- sparse data를 다루기 위한 tree learning 알고리즘
- approximate tree learning을 다루기 위한 weighted quantile sketch
- 학습을 빠르게 가능하게 해준 병렬, 분산 연산
해당 논문의 기여는 아래와 같습니다.
- highly scalable end-to-end tree boosting 시스템을 설계
- 효율적인 proposal 계산을 위한 weighted quantile sketch
- parallel tree learning을 위한 sparsity-aware 알고리즘
- out-of-core tree learning을 위한 효율적인 cache-aware block 구조
Parallel tree boosting을 사용하는 기존 연구들이 있었지만, out-of-core 연산, cache-aware, sparsity-aware 학습은 없었습니다. 이 모든 것을 합친 end-to-end system은 현실 문제에 창의적인 해답을 제공합니다.
2. Tree Boosting in a Nutsell
이번 section에서는 gradient tree boosting system을 리뷰합니다.
2.1 Regularized Learning Objective
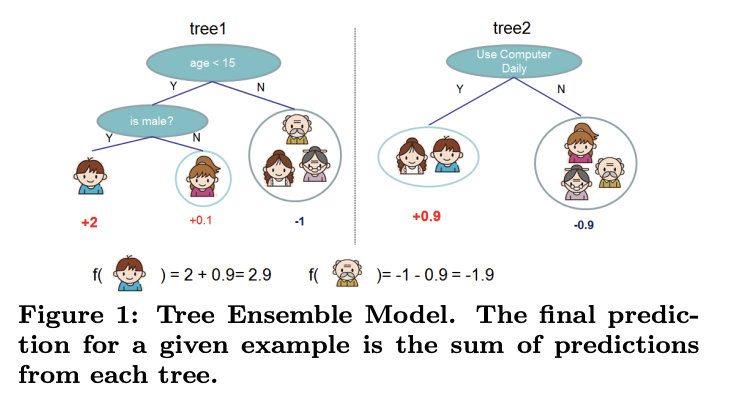
아래와 같이 n개의 sample, m개의 feature를 포함하는 dataset D가 있다고 하자.
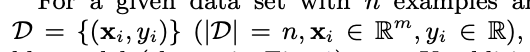
아래 그림과 같은 tree 앙상블 모델은 output 예측을 위해 K개의 함수를 더합니다.
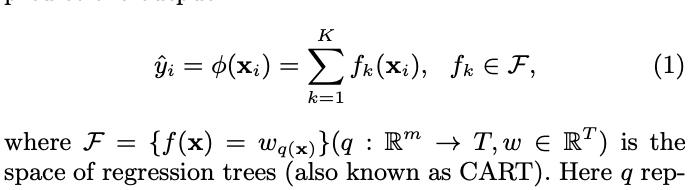
- F : CART로 알려진 regression tree 공간
- q : sample을 해당하는 leaf index에 mapping하는 tree의 구조
- T : tree의 leaf 개수
- f_k : 독립적인 tree q와 leaf 가중치 w를 mapping
- w_i : i번째 leaf의 score(가중치)
해당 model에서 사용된 함수들을 학습하기 위해서 아래의 regularized objective를 최소화해야합니다.

- l : 예측 값과 실제 값의 차이를 측정하는 미분가능한 convex loss function
- sigma function : 모델의 복잡도를 penalize
Regularization항은 over-fitting이 되는 것을 방지합니다. 유사한 regularizaion 기술이 Regularized greedy forest(RGF)에서 사용됐었습니다. 해당 논문에서 사용하는 objective 함수와 learning 알고리즘은 RGF보아 단순하고 병렬화가 쉽습니다.
2.2 Gradient Tree Boosting
식 2의 tree 앙상블 모델은 parameter로써 함수를 포함하고 유클리안 공간에서 전통적인 최적화 방법으로 최적화를 수행할 수 없습니다.
- hat(y_i^(t)) : t번째 반복에서 i번째 sample의 예측값
아래의 objective를 최소화하기 위해 f_t를 더해줍니다.
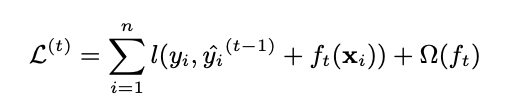
위의 식은 식 2를 따라 모델의 성능을 가장 많이 높여주는 f_t를 greedily하게 더해주는 것을 의미합니다.
위의 objective를 더욱 빠르게 최적화하기 위해 아래와 같이 2차 근사를 활용합니다.

위의 식을 단순화하기 위해 상수항을 제거해주면 t 단계에서의 objective는 아래와 같아집니다.
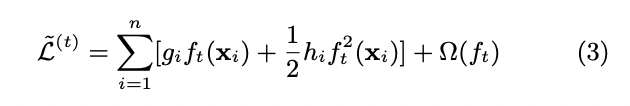
아래 과정에서 f는 leat weight들의 합으로 생각하면 이해하기 수월합니다. f라는 함수가 결국 sample의 결과값을 얻는 것인데 결과값이 결국 leat weight들의 합이기 때문입니다.

식 6은 tree 구조 q의 품질을 측정하기 위한 scoring function으로 사용할 수 있습니다. 이 score는 decision tree를 평가하기 위해 사용되는 불순도와 같습니다.

일반적으로 가능한 tree 구조 q 전부를 나열하는 것은 불가능합니다. 하나의 leaf에서 시작하여 반복적으로 branch를 추가하는 greedy 알고리즘이 대신하여 사용됩니다.
- I_L : 분리 후 왼쪽 node
- I_R : 분리 후 오른쪽 node
- I = I_L U I_R
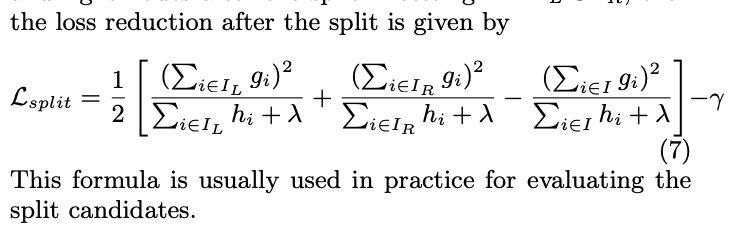
2.3 Shrinkage and Column Subsampling
Over-fitting을 방지하기 위해 regularized 외에도 2가지 방법을 더 사용합니다. 첫째는 shrinkage입니다. Shrinkage는 tree boosting의 각 단계 이후 factor에 의해 추가되는 weight를 확장합니다. Shrinkage는 개별 tree의 영향과 미래 tree의 leaf 공간을 성능 향상을 위해 줄입니다. 둘째는 column subsampling입니다. Column subsampling의 사용은 parallel 알고리즘의 계산 속도를 높여줍니다.
3. Split Finding Algorithm
3.1 Basic Exact Greedy Algorithm
Tree 학습에서 발생할 수 있는 주된 문제 중 하나는 7번 식에서 언급한 최적의 분리를 찾는 것입니다. 최적의 분리를 찾기 위해 split finding 알고리즘은 모든 feature들에서 가능한 분리를 모두 찾아 나열합니다. 이러한 방식을 exact greedy algorithm이라고 합니다.

효율적으로 하기 위해서는 알고리즘은 feature 값에 따라 data를 먼저 정렬하고 gradient 통계량을 축적시키기 위해 정렬된 순서로 data를 처리해야 합니다.
3.2 Approximate Algorithm
Exact greedy algorithm은 모든 경우를 전부 확인하기 때문에 강력하지만 data가 memory에 들어가지 않는다면 사용할 수 없습니다. 동일한 문제는 distributed 환경에서도 발생합니다. 이런 경우에서 효율적인 gradient tree boosting을 지원하기 위해 approximate algorithm이 필요합니다.

알고리즘은 먼저 feature 분포의 percentile를 활용하여 splitting 지점 후보군을 제시합니다. 그 후 후보 지점들로 분리된 bucket에 feature를 mapping하고 통계량을 합친 후 해당 통계량을 바탕으로 최적의 solution을 찾습니다.
후보 지점 proposal 시점에 따라 2가지 변형이 있습니다. Gloval variant는 tree 구조의 최초 phase 동안에 후보 지점을 제시하고, 동일한 proposal을 모든 level에서 split finding을 위해 사용합니다. Local variant는 각 분리 이후마다 새롭게 proposal을 제공합니다.
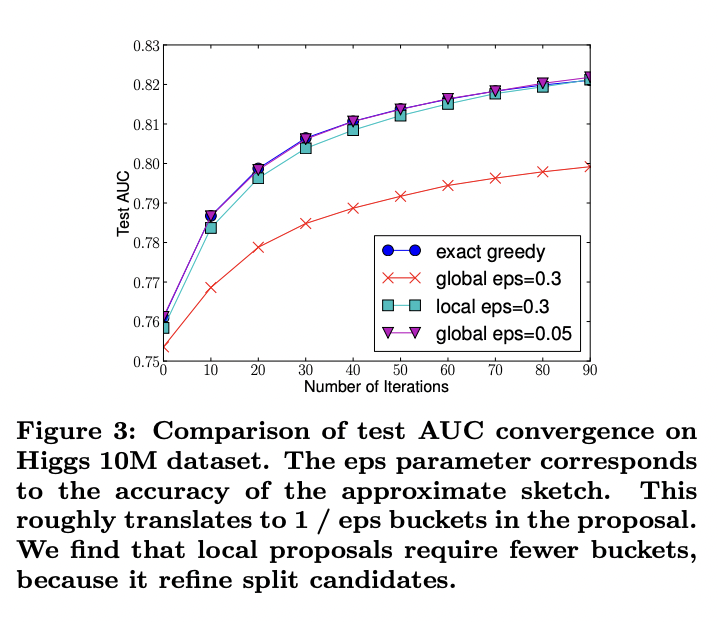
XGBoosting은 하나의 머신에서 효율적으로 exact greedy를 지원하고 모든 환경에서 local, global proposal approximate algoritm 둘 다를 지원합니다.
3.3 Weighted Quantile Sketch
Approximate algorithm의 중요한 단계중 하나는 split point의 후보를 제안하는 것입니다. 일반적으로 feature들의 percentile이 후보 분포를 만들기 위해 활용됩니다.

해당 논문에서는 provable theoretical guarantee로 weighted data를 다룰 수 있는 창의적인 distributed weighted quantile sketch algorithm을 소개합니다. 기본 아이디어는 merge와 prune 연산을 지원하는 data 구조를 제안하는 것입니다.
3.4 Sparsity-aware Split Finding
현실 문제의 data에서 input x가 spare한 경우가 많습니다.
- data에 결측치가 존재하는 경우
- 0이 자주 등장하는 경우
- one-hot encoding 등 인위적인 feature engineering을 한 경우
데이터에서 알고리즘이 sparsity pattern을 인식하도록 하는 것은 중요합니다. 이를 위해 해당 논문에서는 각 tree node에서 아래 그림처럼 default 방향을 더하는 것을 소개합니다.
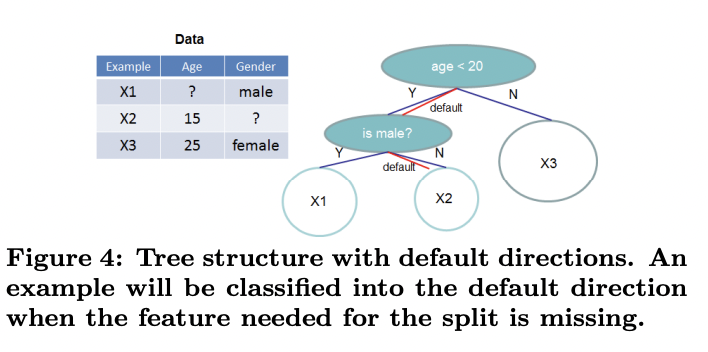
Sparse 행렬 x에서 value가 결측치 일때, default 방향으로 분류됩니다. 최적의 default 방향은 데이터를 통해 학습됩니다.

주된 개선점은 non-missing entiry I_k만 찾아 간다는 것입니다. 제안된 알고리즘은 non-presence를 결측치로 다루고 결측치를 다루는 최적의 방향으로 학습을 진행합니다.
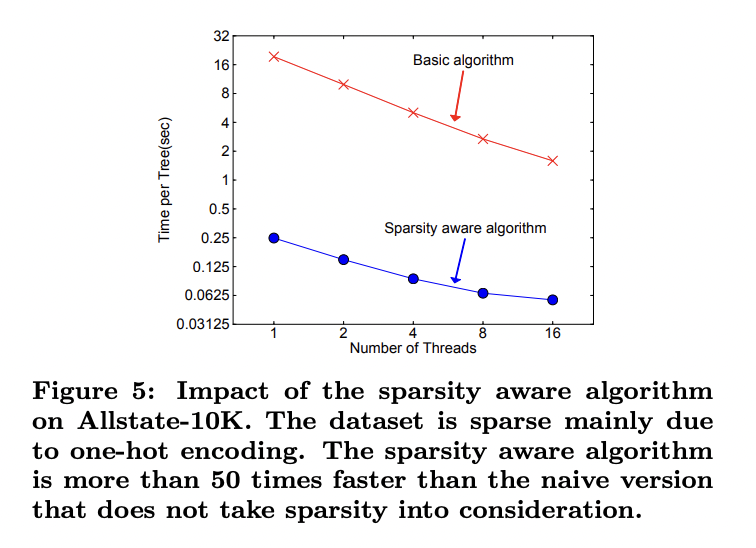
Sparsity aware 알고리즘은 일반버전보다 약 50배 가량 빠른것을 확인할 수 있었습니다.
4. System Design
4.1 Column Block for Parallel Learning
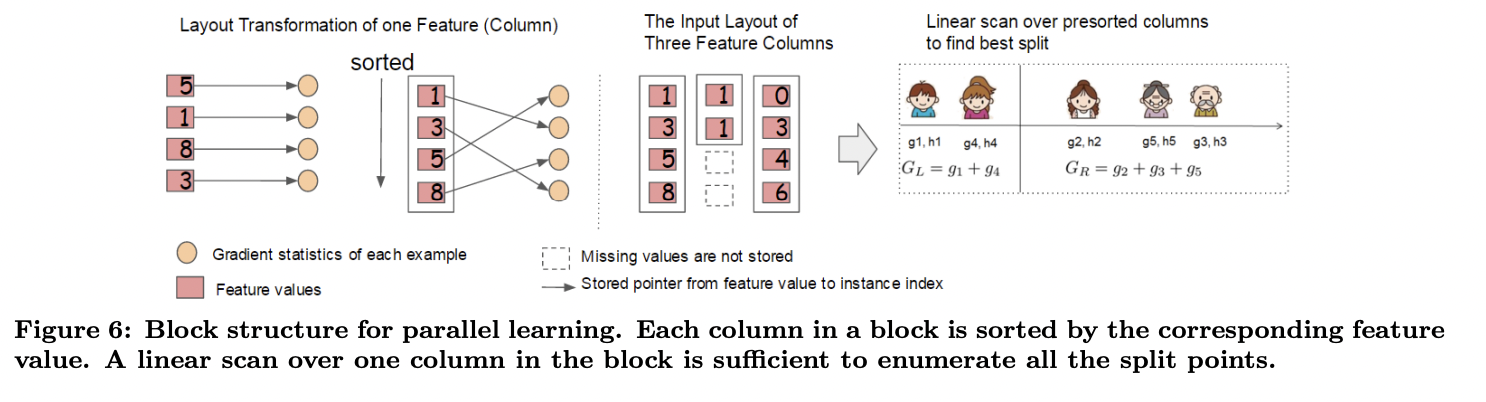
Tree 학습에서 가장 많은 시간이 소요되는 것은 data를 정렬할 때입니다. 정렬 시 발생하는 비용을 줄이기 위해 block라고 불리는 in-memory 단위에 data를 저장하는 방법을 제시합니다. 각 block의 data들은 각 column들이 대응되는 feature 값으로 정렬된 채로 compressed column(CSC) 형식으로 저장됩니다.
Exact greedy algorithm에서는 전체 dataset을 하나의 block에 저장하고 이미 정렬된 entry를 선형적으로 scan하며 split search algorithm을 수행합니다.
아래 그림은 block구조를 사용하여 어떻게 dataset의 구조를 바꾸고, 최적의 split을 찾는 지 보여줍니다.
Block 구조는 approximate algorithm을 사용할 때 역시 도움이 됩니다.
각 column의 통계량을 수집하는 것은 split finding을 위한 parallel algorithm을 제공하여 parallelized 될 수 있습니다. 더 중요하게는 column block 구조는 column subsampling을 지원하기때문에 block 내부에서 column의 subset을 쉽게 찾을 수 있습니다.
4.2 Cache-aware Access
위에서 소개한 block 구조는 split finding의 계산 복잡도를 최적화해주는 데 도움을 주는 반면, 새로 소개하는 algorithm은 feature의 순서에 따라 접근하기 위해 row index를 통해 gradient statistics의 간접적인 접근을 필요로 합니다.

Exact greedy algorithm을 위해 cache-aware prefetching algorithm으로 문제를 완화할 수 있습니다.
아래 그림은 cache-aware와 non cache-aware algorithm을 비교합니다.
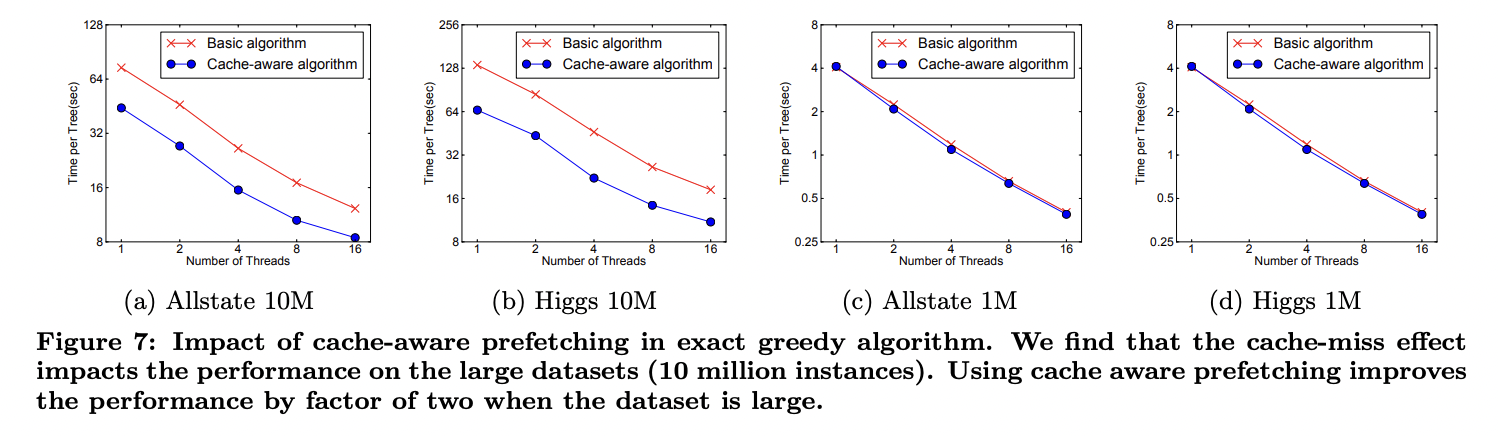
Dataset이 매우 클 때 cache-aware는 그렇지 않은 것보다 약 2배 정보 빠른것을 확인할 수 있습니다.
4.3 Blocks for Out-of-core Computation
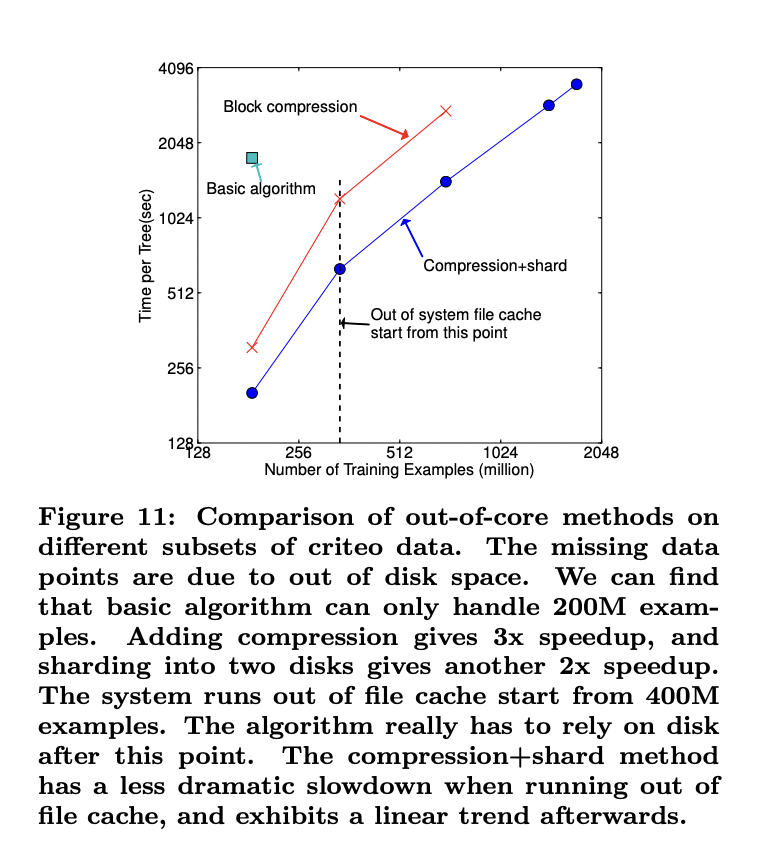
해당 논문 system의 목표 중 하나는 scalable learning을 달성하기 위해 기계의 자원을 모두 활용하는 것입니다. Main memory에 들어가지 않는 data를 다루기 위해 disk 공간을 활용하는 것은 중요합니다. Out-of-core computation을 가능하게 하기 위해 data를 여러 개의 block들로 나눈 뒤, 각 block을 disk에 저장합니다. 계산하는 동안에 독립적인 thread를 main memory buffer에 block을 pre-fetch 하기 위해 사용하는 것은 매우 중요하며 이를 통해 computation은 disk reading과 동시에 일어날 수 있습니다. Out-of-core computation을 개선하기위해 2가지 기술을 사용할 수 있습니다.
Block Compression
Block은 column에 의해 압축되며 main memory로 불러올 때 독립적인 thread에 의해 fly에 압축이 풀립니다. 이는 disk reading cost와 압축해제의 computation의 일부를 교환하는 데 도움을 줍니다.
Block Sharding
두 번쨰 방법은 여러개의 disk에 data를 shard하는 것입니다. Pre-fetcher thread는 각 disk에 할당되고 in-memory buffer로 data를 fetch합니다. 이는 disk reading 처리량 향상에 도움을 줍니다.
5. Related Works
XGBoost는 gradient boosting을 통해 수행됩니다. 또한 overfitting을 방지하기 위해 regularized model을 포함합니다. RGF에서 사용한 것과 유사하게 보이지만 parallelization을 위해 objective와 algorithm을 단순화 시켰습니다. Column sampling은 단순하지만 효과적인 기술입니다. Tree learning에서 sparsity-aware learning을 주되게 사용한 것은 처음입니다.
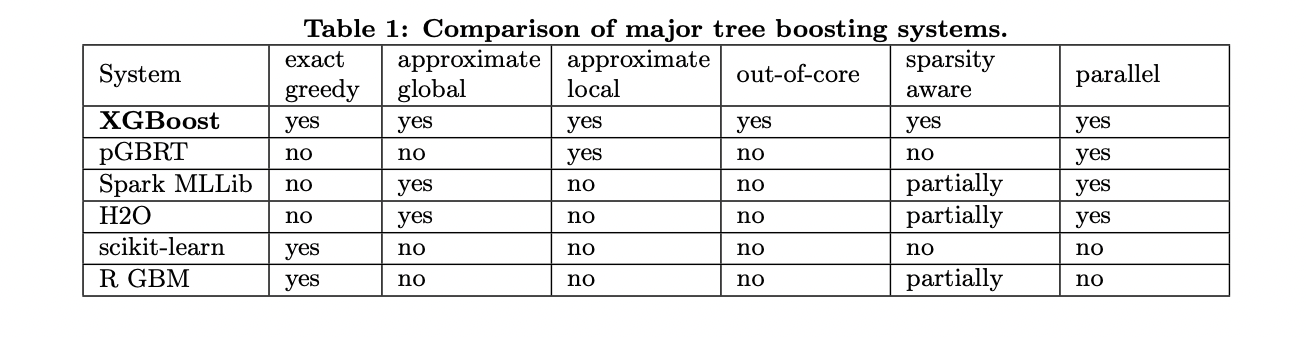
XGBoost는 out-of-core computation과 cache-aware learning을 사용합니다. 아래 표에서 각 모델 별 비교를 확인할 수 있습니다.
6. End to End Evaluations
6.1 System Implementation
6.2 Dataset and Setup
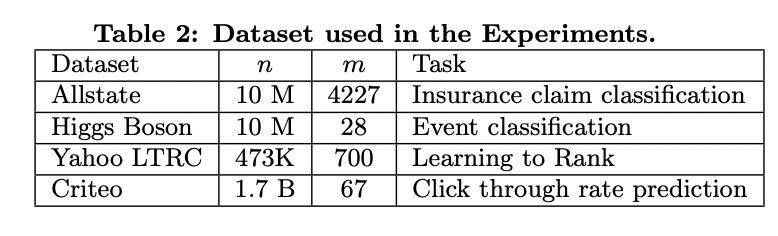
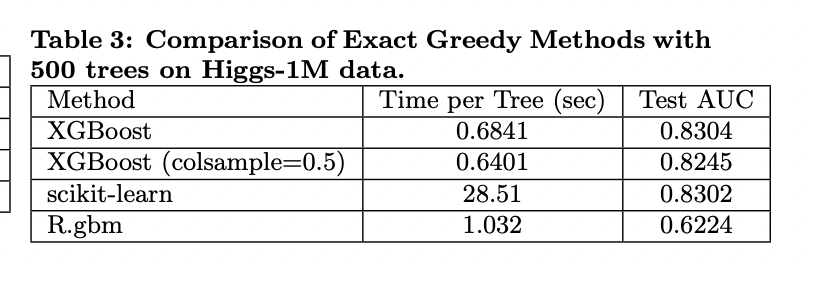
6.3 Classification
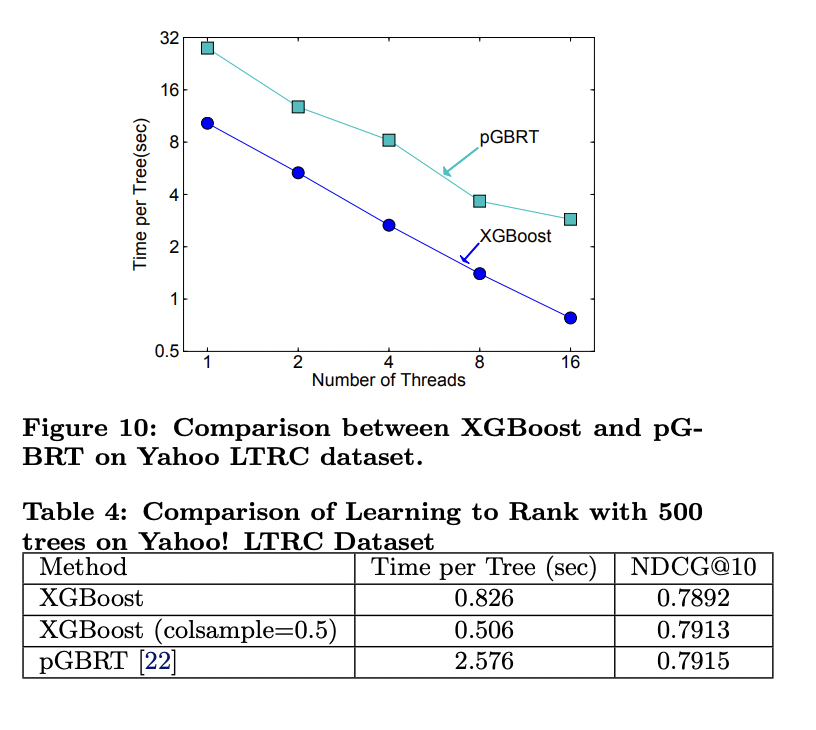
6.4 Learning to Rank
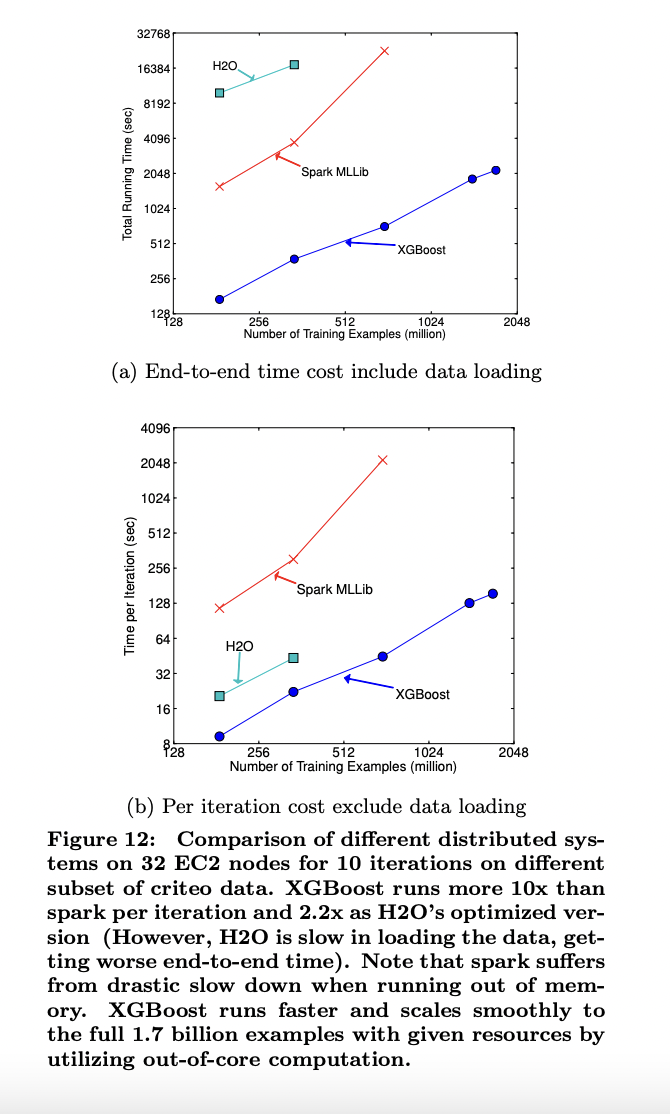
6.5 Out-of-core Experiment
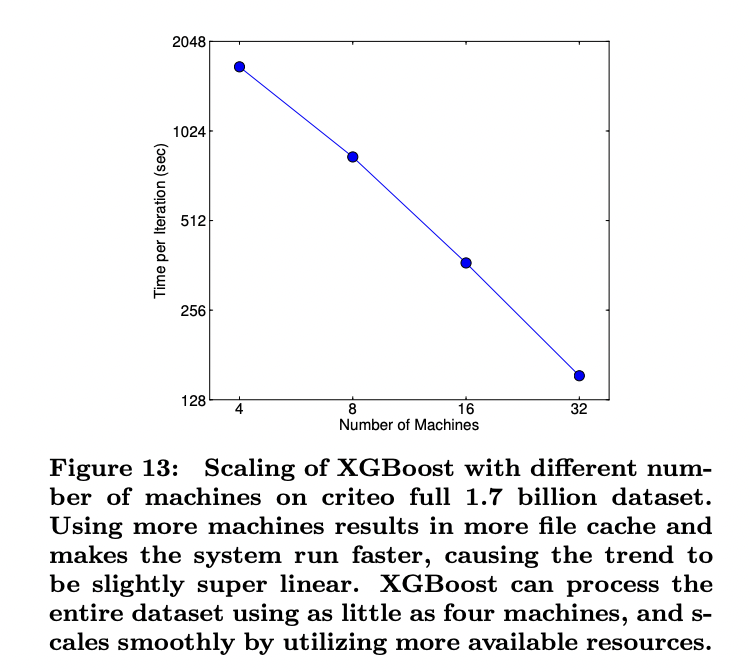
6.6 Distributed Experiment
7. Conclusion
해당 논문에서는 많은 문제에서 SOTA 성능을 보이고 있으며 데이터 과학자들에 의해 널리 사용되는 scalable tree boosting system인 XGBoost를 소개합니다. 또한 sparse data를 다루기 위한 sparsity aware algorithm과 approximate learning을 위한 theoretically jusitified weighted quantile sketch를 제안했습니다. XGBoost에서는 cache access patterns, data compression, sharding이 tree boosting을 위한 scalable end-to-end system을 설계하기 위해 중요한 요소인 것을 보였습니다.
