Transformer의 decoder만을 활용한 구조를 통해 라벨링되지 않은 text 뭉치에서 범용적인 language model을 학습한 후 특정 task 수행을 위해 input 변화를 통해 fine-tuning을 수행하여 model을 얻는 GPT-1의 논문입니다.
[Abstract]
NLU(Natural Language Understanding)은 다양한 task를 구성하고 있습니다. Unlabeled text들은 충분히 있지만 특정 task를 수행하기 위한 labeled data는 부족하기때문에 특정 task를 잘 수행할 수 있는 model을 학습하는 것은 어렵습니다. 해당 논문에서는 이러한 task들을 잘 수행할 수 있도록 해주는 unlabeled text로부터 generative pre-training of language model을 만든 후 각 task마다 discriminative fine-tune을 적용하는 방법을 소개합니다. 이전 방식들과는 달리 해당 논문에서는 각 task에 적합한 input 형태를 만들어주어 fine-tunining 과정에서 모델 구조의 변화를 최소화하여 효율성을 높일 수 있었습니다.
1. Introduction
정제되지 않은 text에서 효율적으로 학습할 수 있게되면 NLP분야에서 supervised learning 의존도를 낮춰줄 수 있습니다. 많은 경우 labeled text가 부족하기 때문에 unlabeled text로부터 언어정보를 사용할 수 있는 model은 annotation 수집 과정을 줄여주기 때문에 큰 도움이 됩니다.
하지만 unlabeled text로부터 단어수준 이상의 정보를 학습하는 것은 2가지 이유로 어렵습니다. 첫째, transfer에 사용하기에 효율적인 text representation을 학습하기에 효과적인 최적화 방식이 명확하지 않습니다. 둘째, 특정 task를 위해 학습된 representation을 transfer하는 효율적인 방식 중 모두에게 인정받는 것이 없습니다.
해당 논문에서는 unsupervised pre-training과 supervised fine-tuning을 결합한 방식을 사용하는 semi-supervised approach를 소개합니다. 해당 논문의 목표는 범용적인 representation을 학습하여 약간의 조정만으로 다양한 task에 적용할 수 있도록하는 것입니다.
이를 위해 2-step 학습 단계를 거칩니다. 먼저 unlabeld data를 활용하여 신경망의 초기 parameter를 학습하는 것을 목적으로 하는 language modeling을 사용합니다. 그 후 해당 parameter를 바탕으로 supervised objective를 사용하는 특정 task를 수행하도록 합니다.
해당 논문에서 소개하는 model 구조는 Transformer로 이루어져있습니다. Transformer를 사용함으로써 text에서 long-term 의존성을 다룰 수 있었고 결과적으로 다양한 task에서 robust한 성능을 가질 수 있도록 해주었습니다. Transfer 과정에서 해당 논문은 task의 특성에 맞도록 input의 형태를 바꿔주는 작업을 추가하였습니다. 이를 통해 pre-trained model 구조를 거의 변화시키지 않은 채 효율적응로 fine-tune시킬 수 있었습니다.
2. Related Work
Semi-supervised learning for NLP
해당 논문의 결과물은 넓은 범위에서 semi-supervised에 속한다고 볼 수 있습니다.
최근에는 unlabeled data로부터 단어 수준 이상의 의미를 학습하고 사용하는 연구들이 수행되고 있습니다.
Unsupervised pre-training
Unsupervised pre-training은 최적의 initialization을 찾는 것을 목적으로 하는 semi-supervised learning의 특별한 case입니다.
해당 논문과 가장 유사한 분야는 language modeling objective를 통해 신경망을 pre-training한 후 특정 task에 supervised하게 fine-tuning하는 것입니다. 기존과는 달리 해당 논문에서는 Transformer 구조를 사용하여 긴 범위의 정보를 잡아낼 수 있습니다.
Auxiliary training objective
Auxiliary unsupervised training objective를 추가하는 것은 semi-supervised learning를 대체할 수 있는 방식입니다.
3. Framework
해당 논문의 학습 과정은 2단계로 이루어져있습니다. 먼저 large corpus of text로부터 high-capacity language model을 학습합니다. 그 후 해당 model을 labeld data를 활용하여 특정 task에서 잘 적용될 수 있도록 조정하는 과정입니다.
3.1 Unsupervised pre-training

해당 논문에서는 language model을 위해 multi-layer Transformer decoder를 사용하였습니다. 해당 model은 input context token에 multi-headed self-attention을 적용한 후 position-wise feedforward layer를 적용하여 target token의 distribution을 반들어냅니다.

3.2 Supervised fine-tuning
Pre-training이 완료된 후 얻은 parameter를 기반으로 supervised target task를 수행합니다.

3.3 Task-specific input transformation
Text classification과 같은 몇몇 task에서는 바로 model을 fine-tunining할 수 있습니다. 하지만 QA와 같은 다른 task들에서는 input의 구조를 수정해줘야만 했습니다. Pre-trainined model이 text의 contiguous sequences로부터 학습되었기때문에 특정 task에 적용하기 위해서는 수정이 필요했습니다.
해당 논문에서는 모델의 구조를 거의 변화시키지 않게하기 위하여 pre-trained model이 다룰 수 있는 형태인 ordered sequence의 형태로 input들을 바꿔주었습니다.
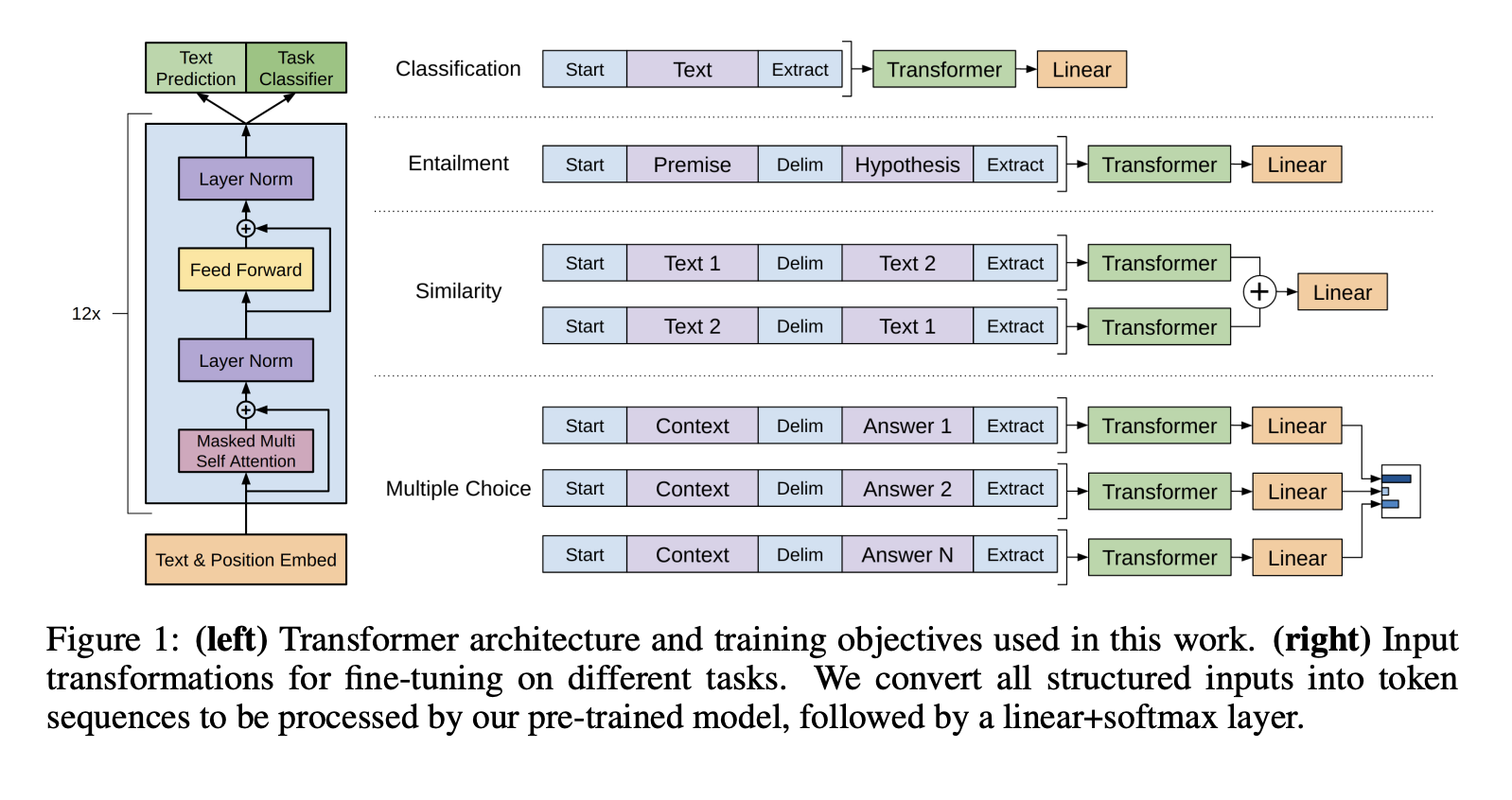
4. Experiments
4.1 Setup
4.2 Supervised fine-tunining
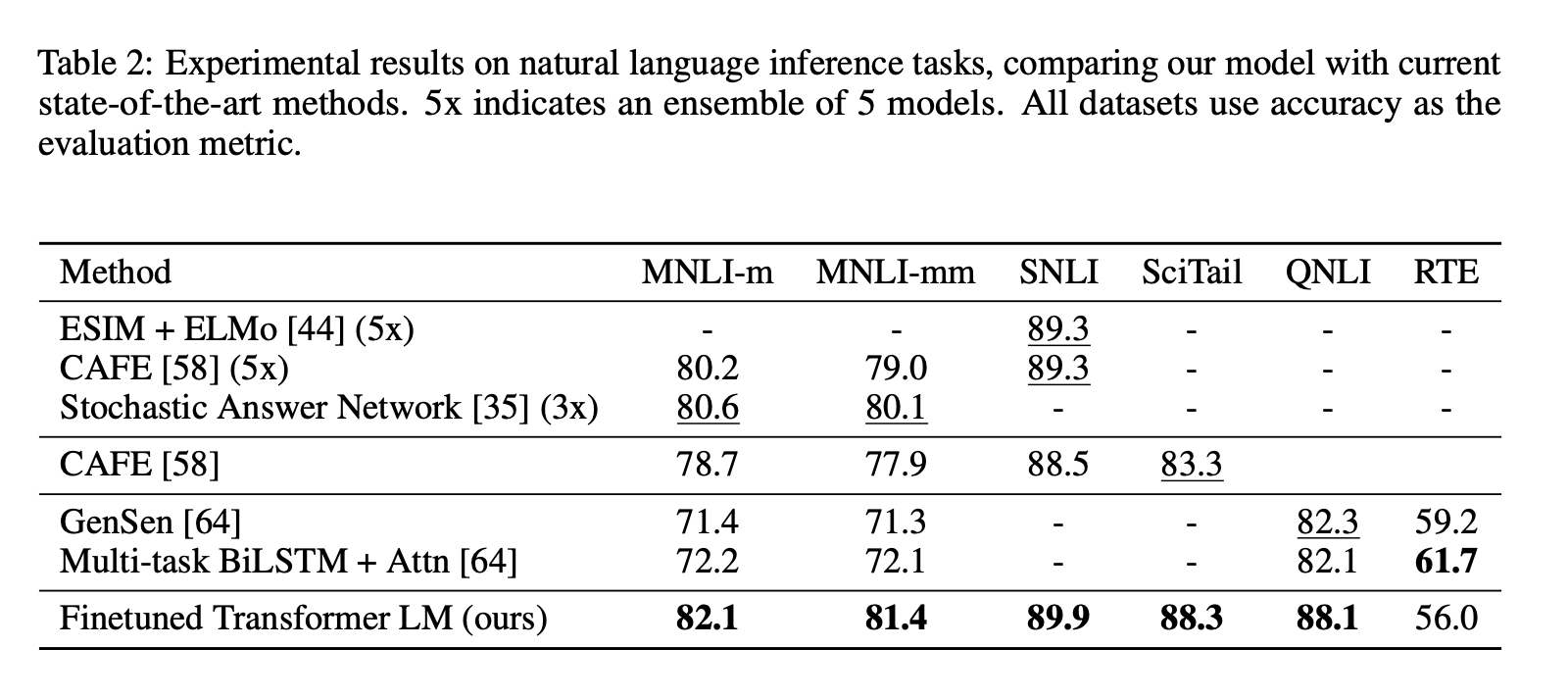
Natural Language Inference
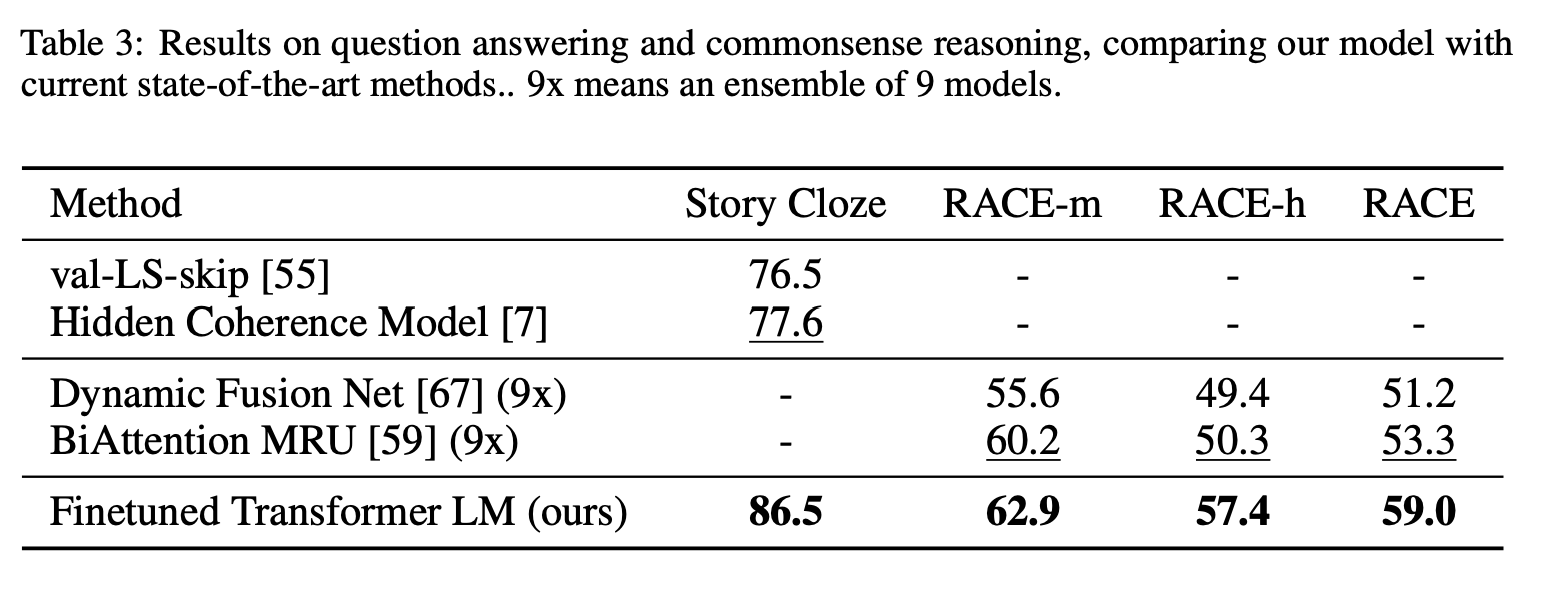
Question answering and commonsense reasoning
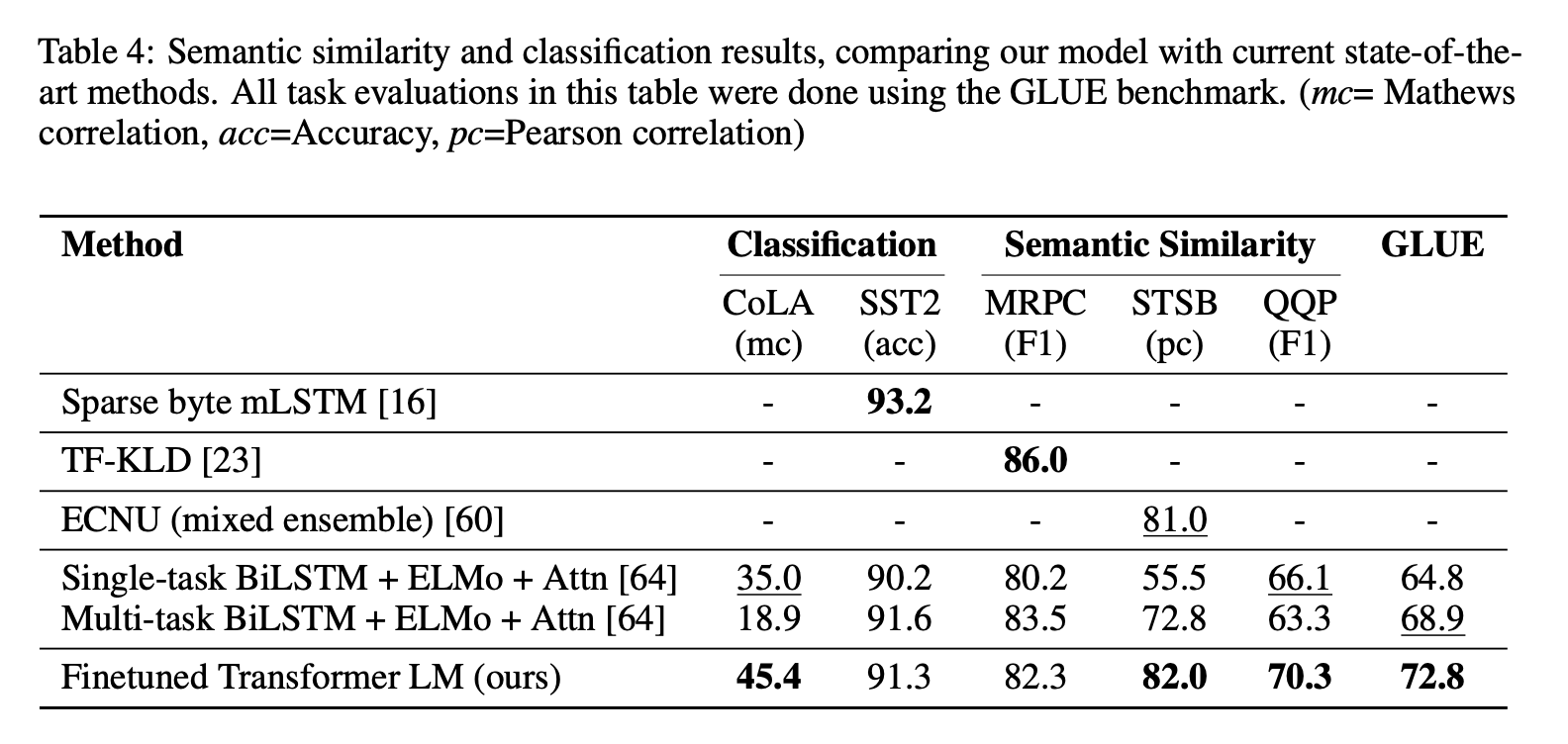
Semantic Similarity
Classification
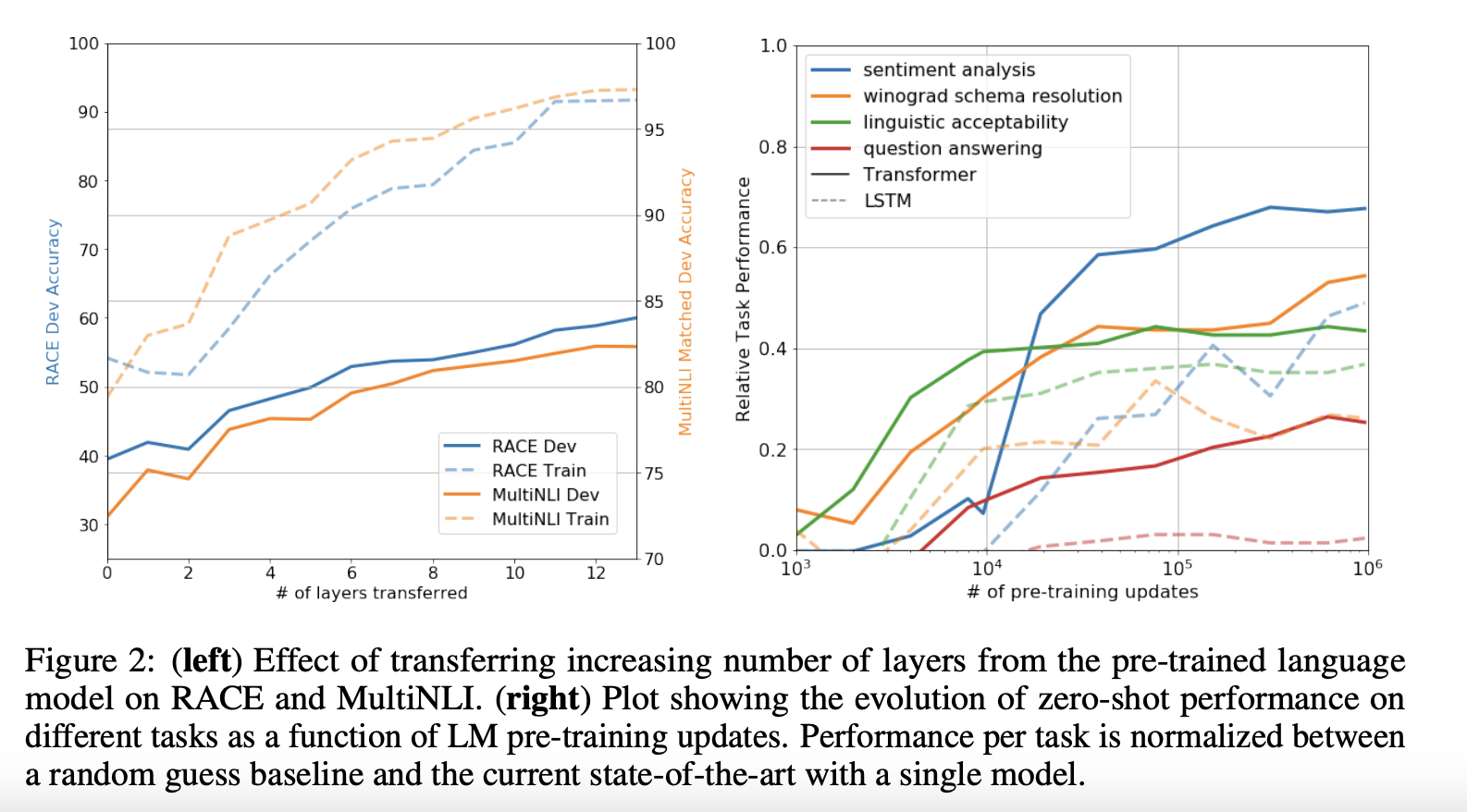
5. Analysis
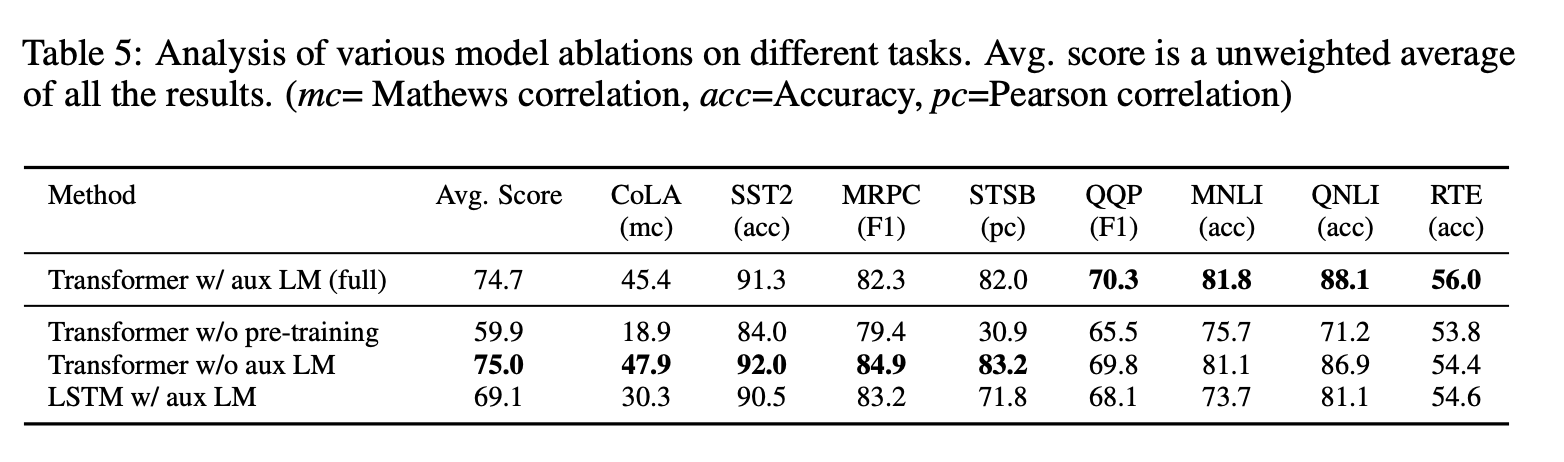
6. Conclusion
해당 논문에서는 generative pre-training을 통해 task-agnositc한 model과 task마다 구별되는 fine-tuning을 활용하여 강력한 natural language understading을 수행할 수 있는 framework를 소개하였습니다. Contiguous text의 diverse corpus를 pre-training하여 해당 논문의 model은 다양한 지식을 습득할 수 있었고 long-range 의존도를 처리할 수 있기때문에 다양한 task를 해결하는데 활용할 수 있었습니다.
