NLP를 넘어서 DeepLearning 분야에 큰 영향을 준 Transformers를 소개하는 논문입니다.
[Abstract]
기존 지배적인 sequence trancsduction model들은 encoder와 decoder를 포함하는 복잡한 recurrent 또는 convolutional 신경망들을 기본으로 하고 있습니다. 가장 좋은 성능을 보이는 모델은 encoder와 decoder를 attenction mechanism으로 연결하고 있습니다. 해당 논문에서는 Transformers라는 이름의 attention mechanism만 사용하는 간단한 구조를 소개합니다. Transformers는 병렬연산이 가능하여 학습 시간을 줄일 수 있게 해주었습니다.
1. Introduction
RNN, LSTM, GRU들은 sequence modeling에 널리 활용되며 sequential한 특징을 지니고 있었습니다.
Recurrent model은 input과 output sequence의 symbol position을 따라 factor computation을 수행합니다. 각 계산 step마다 이전 hidden state h_(t-1)과 t 시점의 input을 활용하여 새로운 hidden state h_t를 만들어냅니다. 이러한 sequential한 계산 방식은 자연스럽게 학습 시 병렬 연산을 힘들게 만들었습니다. 결과적으로 문장의 길이가 매우 길어지게되면 메모리 문제와 같은 현상을 초래하곤 했습니다.
Attention mechanism은 input과 output sequence들의 거리에 의존하지 않고 모델링을 할 수 있게 되어 sequence modeling과 transduction model에서 중요한 역할을 하게되었습니다. 하지만 이러한 attention mechanism은 recurrent network와 결합하여 사용되었습니다.
해당 논문에서는 recurrence는 완전히 배제하고 온전히 attention mechanism만 사용하는 Transformers라는 모델 구조를 소개합니다. Transformers는 병렬화를 제대로 활용하여 학습을 수행할 수 있게 해주었습니다.
2. Background
Sequential한 연산을 피하고자하는 노력은 모든 input과 output 위치에 대하여 병렬적으로 hidden representaion 계산이 가능한 CNN을 기본 block으로 하는 모델들의 발전을 이루어낸 결과를 만들어냈습니다. 이러한 모델들에서 임의의 input과 output 사이의 연관성을 찾기위해 필요한 연산의 수가 거리에 따라 증가하였습니다. 결과적으로 거리가 멀어질 수록 계산이 힘들어졌습니다. Transformers에서는 항상 일정한 연산 개수를 가질 수 있도록 하였습니다.
Self-attention(intra-attention)은 sequence의 representation을 계산하기 위하여 하나의 sequence에서 서로 다른 위치에 attention mechanism을 적용하는 방법입니다.
Transformers는 input과 output의 representation을 계산하기 위하여 sequence-aligned RNN이나 convolution을 사용하지 않고 오직 self-attention에만 의존하는 첫번째 transduction model입니다.
3. Model Architecture
기존의 성능이 좋은 transduction model들은 encoder-decoder 구조를 가지고 있습니다. Encoder에서는 (x_1 ~ x_n)의 input symbol들을 연속적인 representation인 z = (z_1 ~ z_n)으로 바꿔주는 역할을 합니다. z가 주어졌을 때 decoder는 매 시점마다 output sequence (y_1 ~ y_m)을 만들어내는 역할을 수행합니다. 각 step마다 모델들은 다음 output을 만들어내기 위하여 이전에 만들어낸 symbol과 현재 input을 동시에 활용하는 auto-regressive한 성격을 지니고 있습니다.
Transformers는 encoder와 decoder에서 self-attention, point-wise fully connected layer들이 여러 층 쌓은 구조를 기본으로 하고 있습니다.

3.1 Encoder and Decoder Stacks
Encoder : Encoder는 N=6인 동일한 layer들의 stack으로 구성되어있습니다. 각 layer들은 2개의 sub-layer를 갖습니다. 2가지는 multi-head self-attention mechanism과 simple, position-wise fully connected feed-forward network입니다. 해당 논문에서는 2개의 sub-layer마다 residual connection을 활용하고 후에 layer normalization 역시 사용하였습니다. 결과적으로 각 sub-layer의 output은 LayerNorm(x + Sublayer(x))가 되고 이 때 Sublayer(x)는 sub-layer에 의해 연산된 결과입니다. 모든 sub-layer 뿐만 아니라 embedding layer에서도 residual connection을 사용할 수 잇도록 output dimension d_model = 512로 두었습니다.
Decoder : Decoder 역시 N=6인 동일한 layer들로 이루어져있습니다. Encoder layer의 동일한 2개의 sub-layer 외에도 decoder에는 encoder stack의 output에 multi-head attention을 수행하는 3번째 sub-layer가 있습니다. Encoder와 마찬가지로 residual connection과 layer normalization을 사용합니다. 또한 self-attention sublayer를 decoder stack에서 수정하여 뒤에 등장하는 input들이 attend 되는 것을 막아주었습니다. 이러한 masking은 i번째 위치를 예측하기 위하여 i번째 이전의 위치들의 정보들만 활용할 수 있도록 해주었습니다.
3.2 Attention
Attention function은 query와 key-value 쌍을 output으로 mapping하는 역할을 해줍니다. 이 때 queyr, key, value, output 모두 vector입니다. Output은 value들의 가중평균으로 계산되며 이 때 가중치는 query와 key에서 도출됩니다.
3.2.1 Scaled Dot-Product Attention
해당 논문에서는 이러한 독특한 attention을 Scaled Dot-Product Attention이라고 합니다. Input은 d_k 차원을 갖는 query, key와 d_v 차원을 갖는 value들로 이루어져 있습니다. Query와 모든 key에 대하여 dot product를 계산한 후 (d_k)^(1/2)로 나눠준 후 value들의 가중치로 활용하기 위하여 계산 결과를 input으로 softmax function의 결과값을 얻습니다.

주로 활용되는 2가지 attention function은 additive attention과 dot-product(multiplicative) attention입니다. Dot-product attention이 해당 논문에서 scaling factor를 제거한 버전입니다. Additive attention은 single hidden layer와 feed-forward network를 사용하는 compatibility function을 계산합니다. 이론적으로 두 모델은 complexity에서 비슷하지만, dot-product attention이 활용함에 있어서 좀 더 빠르고, 좀 더 space-efficent합니다.
3.2.2 Multi-Head Attention
d_model 차원의 key, value, query들에 하나의 attention function을 적용하는 대신에 해당 논문에서는 query, key, value에 d_k, d_k, d_v 차원을 각각 갖는 서로 다른, 학습된 linear projection을 h번 적용했을 때 이점이 있다는 것을 보였습니다. 각 projected version마다 attention function을 병렬적으로 적용하였습니다.
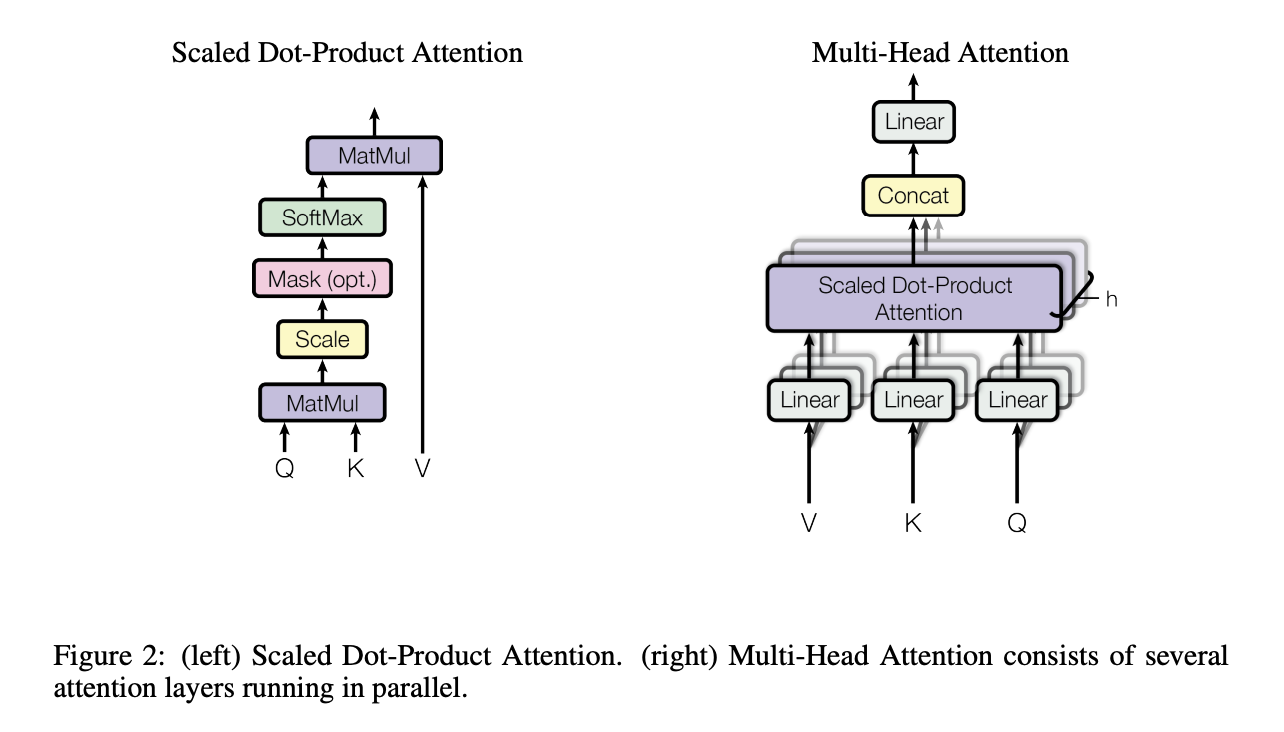
Multi-head attention은 model이 다른 위치에서 다른 representation subspace로부터 정보를 attend하여 결합할 수 있도록 해주었습니다.

3.2.3 Applications of Attention in out Model
Transformers에서는 3가지 다른 방식으로 multi-head attention을 사용합니다.
- 'Encoder-decoder attention' layer에서 query는 이전 decoder layer에서 넘어오고 memory key와 value는 encoder의 output에서 옵니다. 이는 decoder의 모든 위치에서 input의 모든 위치를 attend할 수 있도록 해줍니다.
- Encoder는 self-attention layer를 포함합니다. Self-attention layer에서 모든 key, value, query는 이전 encoder의 layer에서 나옵니다. Encoder의 각 위치에서 encoder의 이전 layer의 모든 위치를 attend할 수 있습니다.
- Decoder의 self-attention layer는 decoder의 각 위치에서 decoder의 모든 위치를 attend할 수 있게 해줍니다. 해당 논문에서는 masking out을 활용하여 오른쪽에서 왼쪽방향으로 오는(leftward) 정보 흐름을 막아줍니다. (예측 이후에 등장하는 단어 정보를 차단해줍니다)
3.3 Position-wise Feed-Forward Networks
Attention sub-layer 외에도 encoder와 decoder의 각 layer마다 fully connected feed-forward network가 있습니다. 이는 2개의 linear transformation과 ReLU로 이루어져 있습니다.
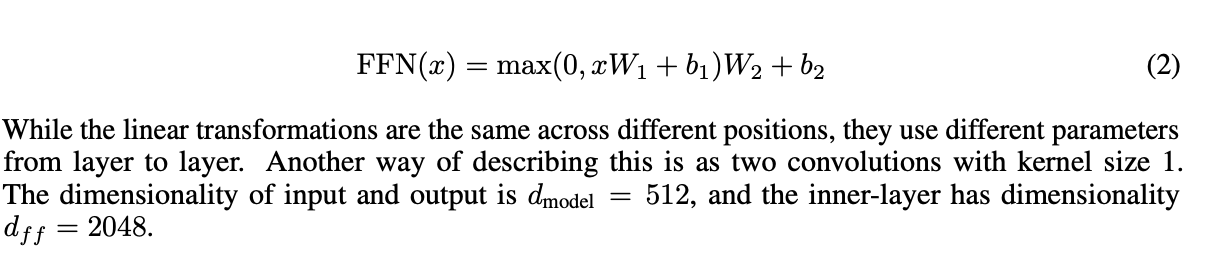
3.4 Embeddings and Softmax
해당 논문에서는 input token과 output token을 d_model 차원의 vector로 변환하기 위하여 embedding을 학습합니다. 또한 decoder의 결과를 다음 token 예측 확률로 변환하기 위하여 학습된 linear transformation과 softmax 함수를 사용합니다. 해당 논문의 모델에서는 두 embedding layer들과 pre-softmax linear transformation에서 동일한 가중치를 공유하여 활용합니다.
3.5 Positional Encoding
해당 논문에서는 recurrence와 convolution이 없기 때문에 model에서 sequence 순서 정보를 활용하기 위해서는 sequence에서 token들의 상대적이고 절대적인 위치 정보를 활용할 수 있도록 특정 정보를 추가해야만 했습니다. 이를 위해 "positional encoding"을 input embedding에 추가하여 encoder과 decoder stack의 가장 bottom에 두었습니다. Positional encoding 역시 embedding과 동일한 차원 d_moeld을 가지며 둘은 합해질 수 있습니다.

4. Why Self-Attention
해당 논문에서는 self-attention layer와 recurrent, convolutional layer를 비교합니다.
먼저 각 layer마다 총 계산 복잡도입니다. 그 다음은 병렬화될 수 있는 계산량입니다. 세번째는 신경망 안에서 long-range 의존도 사이의 path length입니다.

5. Training
5.1 Training Data and Batching
5.2 Hardware and Schedule
5.3 Optimizer
5.4 Regularization
6. Results
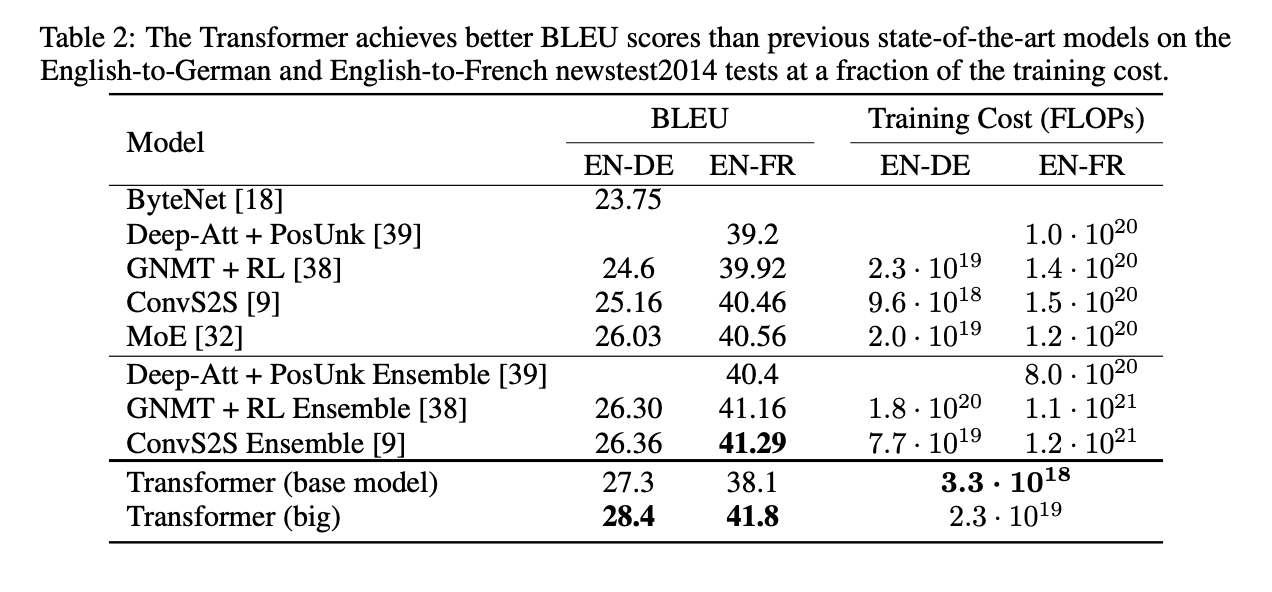
6.1 Machine Translation
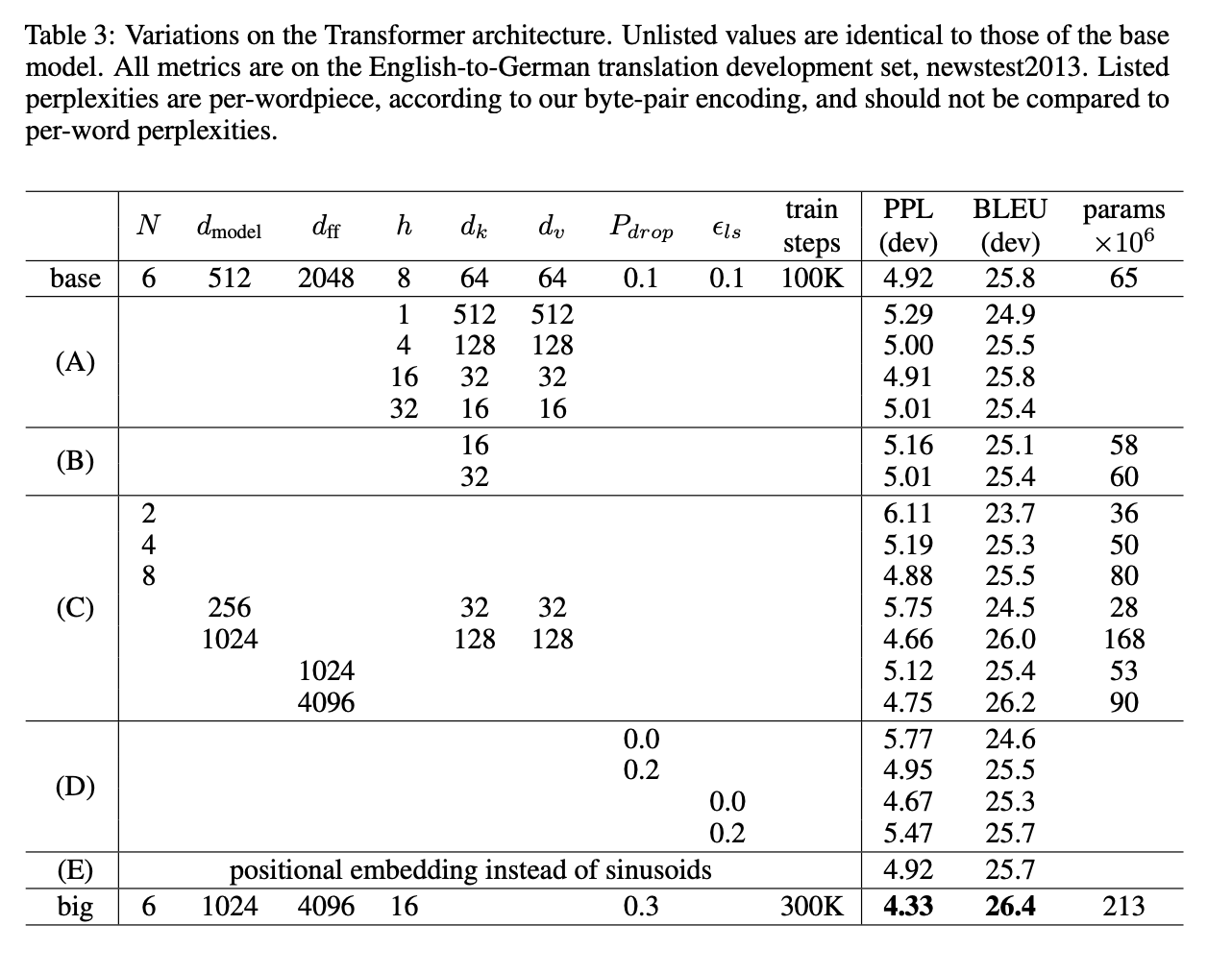
6.2 Model Variations
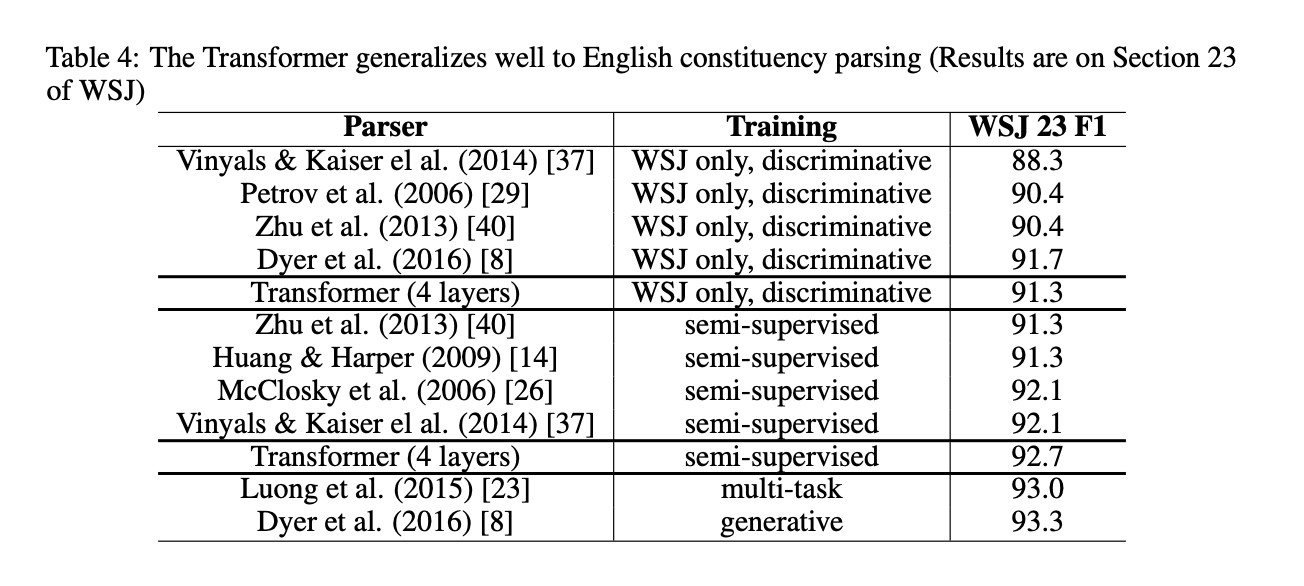
6.3 English Constituency Parsing
7. Conclusion
해당 논문에서는 오직 attention만 사용하는 첫번째 sequence transduction model인 Transformers를 소개하였습니다. Transformers는 encoder-decoder에서 일반적으로 활용하는 recurrent layer를 multi-headed self-attention으로 바꾸었습니다.
