Key2Vec: Automatic Ranked Keyphrase Extraction from Scientific Articles using Phrase Embeddings
Paper_review
과학논문을 한정하여 keyword를 자동으로 뽑아주고 theme weighted PageRank 알고리즘을 통해 keyword 간의 ranking을 매기는 Key2Vec 모델을 소개하는 논문입니다.
[Abstract]
Keyphrase 추출은 문서를 phrase의 representation 집합으로 mapping시키는 NLP의 주된 task 중 하나입니다. 해당 논문에서는 Key2Vec이라고 부르는 unsupervised 방법을 소개합니다. Key2Vec은 과학논문들로부터 keyphrase들을 ranking화하여 phrase embedding을 사용합니다.
1. Introduction and Background
Keyphrase는 문서의 중요한 부분을 나타내는 하나 혹은 둘 이상의 어휘적 단위입니다. 과학논문에서 뽑힌 keyphrase들의 순위를 매기는 task는 독자들에게 관련된 문서들을 추천하고, 저자들에게 빠진 인용을 강조해주고, 주된 reviewer들을 선별하고, 연구 분야의 trend를 분석하는데 도움을 주기 때문에 큰 관심을 받고 있습니다. 하지만 해당 task는 아직 제대로 해결되지 않았으며 현 system하에서 성능은 그리 좋지 않습니다. 직면하고 있는 어려움 중 몇 가지는 처리되어야 하는 문서의 길이가 고정되어 있지 않다는 것, 문서 구조가 일관적이지 않다는 것, 서로 다른 영역을 다룰 수 있는 방법이 존재하지 않다는 것입니다.
자동으로 keyphrase를 뽑아주는 방법은 supervised, unsupervised 2가지로 분류할 수 있습니다. Supervised 방식은 문제를 binary 분류 문제로 취급하는 반면, unsupervised 방식은 TF-IDF, clustering, graph-based ranking 등의 방법을 기반으로 하고 있습니다. Unsupervised 방식은 training data가 필요하지 않다는 이점이 있으며 어떠한 영역에서도 결과를 만들어낼 수 있다는 장점이 있습니다.
최근 NLP 영역에서 딥러닝 기술이 발전함에따라 word embedding이라 불리는 단어를 dense real-value vector로 표현하는 방식이 주된 trend가 되었습니다. 이렇게 얻은 embedding vector는 단어 간의 의미적, 문법적 관계 정보를 포함할 수 있게 되었습니다.
Word embedding은 과학논문으로부터 keyphrase를 추출하는 과정에서 유의미한 결과를 얻어내는 데 도움이 된다는 것이 이미 몇차례 확인되었습니다. 기존에는 domain에 특화된 방식을 사용하지 않았기 때문에 해당 논문에서는 과학논문에 특화된 domain-specific embedding을 활용하여 실험을 진행하였습니다.
해당 논문에서는 과학논문으로부터 keyphrase로 뽑힌 후보들을 domain-specific embeeding을 활용하여 표현하고 theme-weighted PageRank 알고리즘을 활용하여 순위를 매겼습니다. 후보 keyphrase들의 theme-weight는 동일한 embedding을 통해서 얻은 theme representaion이나 논문의 주된 주제와 얼마나 유사한지를 나타내는 값입니다. 후보 keyphrase들을 표현하기 위해 확장된 phrase embedding을 활용하고 순위를 매겼기 때문에 Key2Vec이라는 이름을 붙였습니다.

2. Methodology
해당 논문의 방식에서는 3단계를 활용합니다.
- 후보 선별
- 선별된 후보들 scoring
- 후보 순위 매기기
모든 단계들은 text processing 단계와 phrase embedding model에 영향을 받게됩니다.
2.1 Text Processing
Unigram word와 혼합된 multi-word phrase 표현 방식은 embedding model의 성능과 accuracy를 높여준다는 연구가 이미 존재하고 있습니다. 2개이상의 단어들이 서로 얼마나 자주 동시에 등장하는지 고려하는 방법을 사용하지 않고 해당 논문에서는 이미 학습된 dependency parsing과 NER model에 의존합니다. 이를 위해 해당 논문에서는 Spacy를 활용하여 문서를 문장으로 나누고 문장을 tokenize하여 unigram token화하고 해당 token들로부터 noun phrase 여부와 named entity를 확인하였습니다.
해당 논문에서는 다음과 같은 token들만 걸러냈습니다.
- 숫자로만 이루어진 noun phrase와 named entity
- Date, time, percent, money, quantity, ordinal, cardinal에 속하는 named entity
- 일반적인 stopword들은 제거
- -를 제외한 punctuation들은 제거
또한 아래와 같은 단계를 거쳐 multi-word noun phrase와 named entity를 전처리하였습니다.



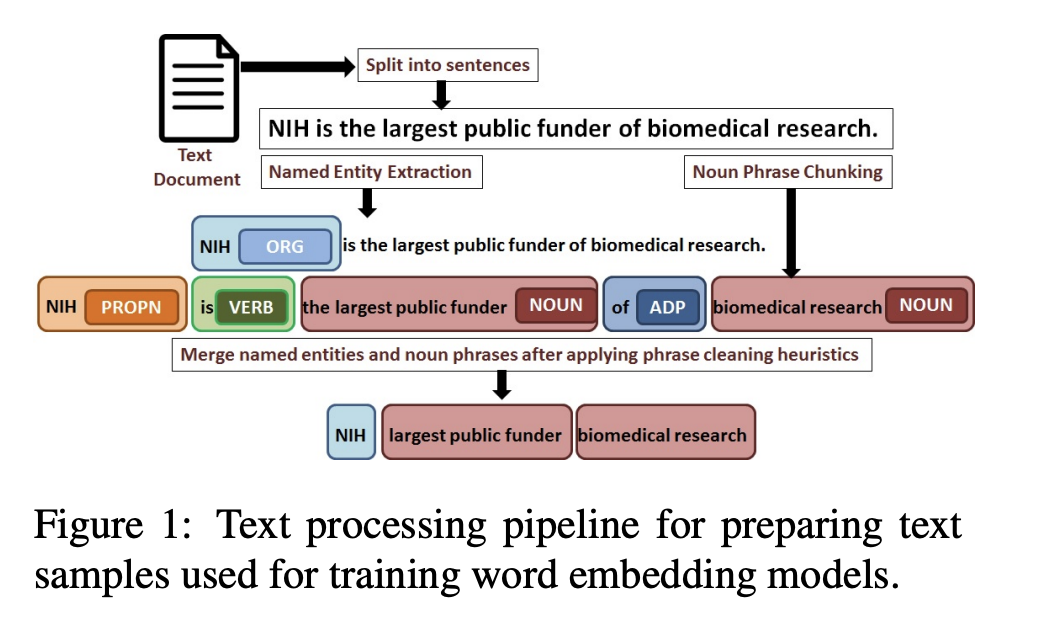
2.2 Training Phrase Embedding Model
해당 방법은 embedding model 성능에 큰 영향을 받습니다. 해당 논문에서는 Fasttext를 사용하여 multi-word phrase embedding을 학습하였습니다. 해당 논문에서 활용한 training 사전은 unigram과 multi-word phrase 모두를 포함하고있습니다.
Embedding model의 주된 목적은 단어 사이의 의미적, 문법적 유사도를 포착하기 위함입니다. 해당 논문에서는 단어 사이의 의미적 형태론적 유사도를 모두 잡아내기 위하여 Fasttext를 활용하였습니다.
Word2Vec과 Glove와 같은 embedding 방식들은 유사한 문맥 하의 등장 빈도를 고려하는 것을 바탕으로 하기 때문에 단어들 사이의 의미적 유사도만을 려하기때문에 해당 논문에서 활용하고자하는 목적과는 맞지 않았습니다.
Dataset
해당 논문에서는 1,147,000개의 과학논문들의 abstract들을 활용하였습니다.
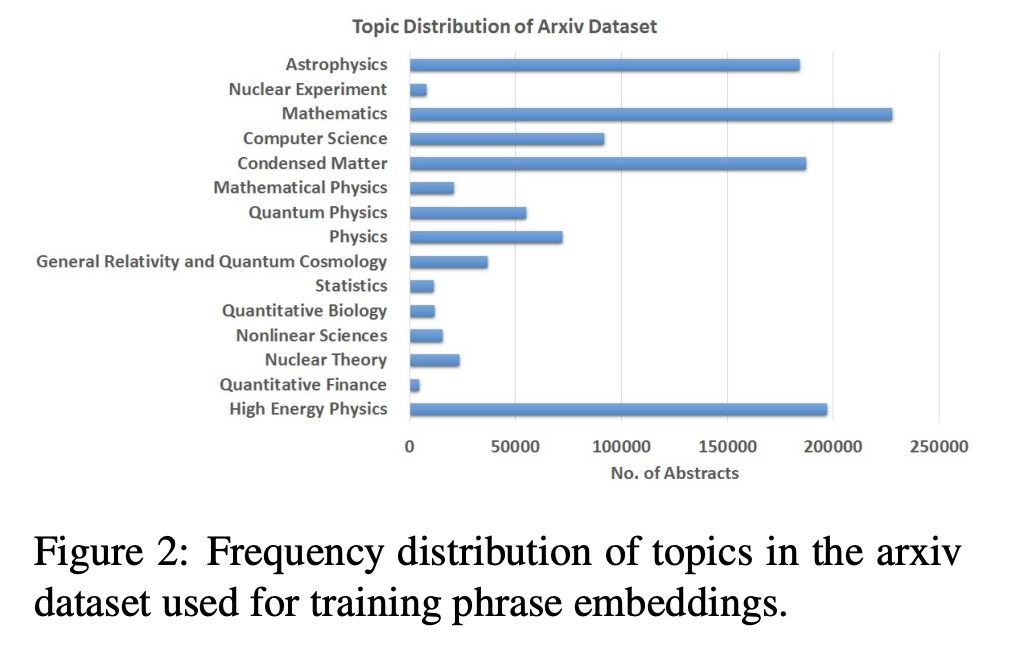
문서들을 전처리한 후 negative sampling과 window-size 5, dimension 100, epoch 10을 활용하여 Fasttext-skipgram model을 학습하였습니다.
Candidate Selection
해당 step에서는 문서에서 뽑은 모든 phrase들로부터 keyphrase 후보들을 뽑는 것을 목적으로 하며 일반적으로 대부분의 automated ranked keyphrase extraction system에서 활용됩니다. 모든 phrase들이 Keyphrase 후보로 사용되지는 않습니다.
Candidate Scoring
해당 step에서는 문서(d_i)에 theme vector((pi_d_i)^hat)를 부여합니다. Theme vector는 문서의 종류에 따라 조정이 될 수 있습니다. 이 과정에서 주어진 문서로부터 theme excerpt를 뽑아내고 더 나아가 named entity와 noun phrase, unigram word들로 이루어진 thematic phrase들의 unique set(T_d_i = {t_1, t_2 ~ t_m}d_i}을 뽑아낼 수 있습니다.
학습된 phrase embedding model을 사용하여 얻은 theme excerpt로부터 얻은 각 thematic phrase의 vector representation(t_j^hat)
를 얻을 수 있고 최종 theme vector는 vector들의 합을 통해 얻을 수 있습니다.
Theme vector와 keyphrase 후보 vector들 간의 cosine distance를 계산하여 각 후보마다 score로 할당을 해줍니다. 각 후보별 최종적인 thematic weight를 얻게되는 것입니다.
Candidate Ranking
Keyphrase 후보들의 최종 ranking을 수행하기위하여 해당 논문에서는 weighted personalized PageRank 알고리즘을 활용합니다. Directed graph G_d_i는 주어진 문서(d_i)를 vectex C_d_i로 사용하며 window size 5에서 두 keyphrase 후보들이 동시에 등장한다면 연결되는 edge E_d_i를 사용하여 만들어집니다. Edge들은 bidirectional합니다. Weight는 keyphrase 후보 간의 의미적 유사도를 사용하여 계산됩니다.

3. Experiments and Results
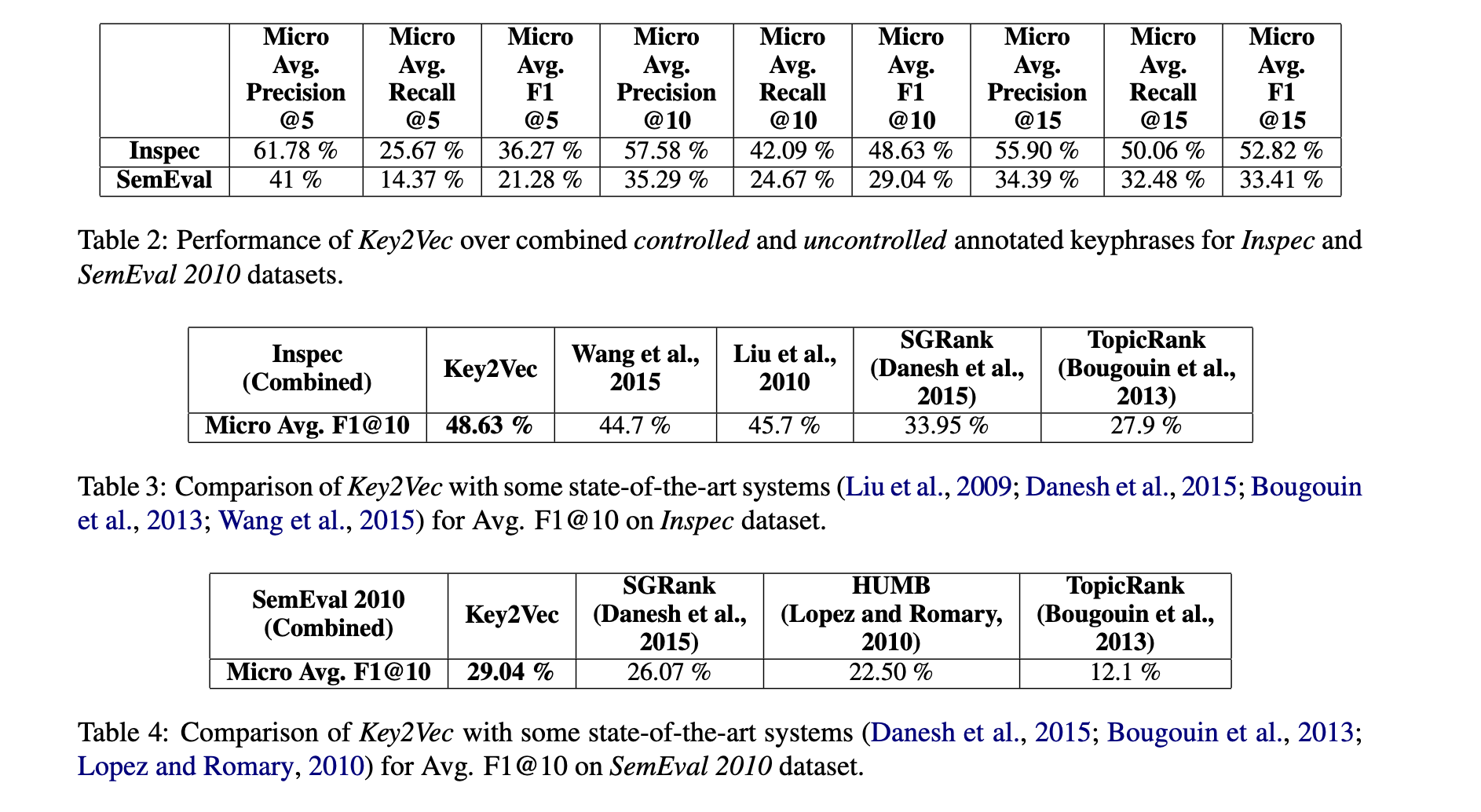
4. Conclusion and Future Work
해당 논문에서는 과학논문으로부터 keyphrase를 자동으로 뽑은 후 ranking을 매기는 framework를 제안하였습니다. 해당 논문에서는 phrase embedding을 학습하는 효율적인 방법을 보여주고 과학논문의 thematic representation을 구성하고 후보 keyphrase들의 thematic weight를 할당하는 효율적인 방법을 제안하였습니다. 또한 candidate keyphrase의 순위를 매기기 위하여 theme-weighted PageRank 알고리즘을 소개하였습니다. 실험을 통해 해당 논문에서 제안한 Key2Vec이 좋은 성능을 갖는다는 것을 보일 수 있었습니다.
