NMT에서 효율적으로 활용될 수 있는 attention 기반의 구조인 global. local 2가지 방법을 소개하는 논문입니다.
[Abstract]
Attention mechanism은 번역 시 source sentence의 특정 부분에 선택적으로 집중하는 방식을 통해 NMT(Neural Machine Translation)의 성능을 높이는데 사용되었습니다. 하지만 attention-based NMT를 위한 효율적인 구조를 찾는 연구는 거의 수행되지 않았습니다. 해당 논문에서는 2개의 단순하면서 효율적인 attention mechanism을 소개합니다.
- global approach : 항상 모든 source words를 attend
- local approach : source words의 일부만 attend
1. Introduction
NMT는 large-scale 번역에서 SOTA 성능을 보였습니다. NMT는 최소한의 domain knowledge만을 필요로하고 컨셉적으로 단순하기때문에 매력적입니다.
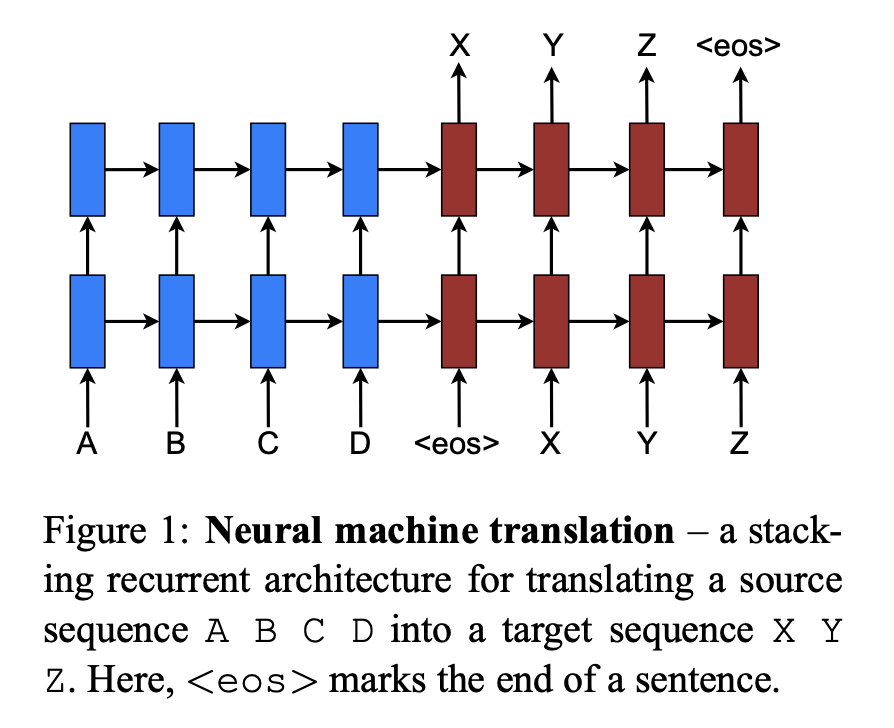
NMT는 end-to-end 방식으로 학습되는 large neural network이고 매우 긴 word sequences들에 대해서도 일반화를 잘할 수 있습니다. 이는 model이 매우 큰 phrase table와 language model을 갖고 있을 필요가 없다는 것을 의미합니다. 따라서 NMT는 매우 작은 memory footprint를 가집니다. 또한 NMT decoder는 간단하게 수행됩니다.
"Attention"의 개념은 최근 신경망을 학습하는 과정에서 유명세를 얻고 있습니다. NMT 분야에서 Bahdanau et al. (2015) 논문에서 성공적으로 attention mechanism을 적용하였습니다. 하지만 지금까지 NMT를 위한 attention-based architecture를 찾는 연구는 없었습니다.
해당 논문에서는 attention을 기반으로 한 2개의 단순하면서 효율적인 model을 소개합니다.
Global approach는 모둔 source word를 attend합니다. Local approach는 source word의 일부를 사용합니다. Global approach는 Bahdanau et al. (2015)의 model과 유사하지만 좀 더 단순한 구조를 갖고 있습니다. Local approcah는 Xu et al. (2015)에서 제안한 hard attention model과 soft attention model을 섞은 것으로 볼 수 있습니다. Local approach는 global model이나 soft attention보다 계산 비용이 적다는 이점이 있습니다. 동시에 hard attention과 다르게 local attention은 거의 모든 구간에서 미분가능하여 학습을 좀 더 쉽게 할 수 있습니다. 이 뿐만 아니라 해당 논문에서는 다양한 alignment function을 사용하여 실험을 진행하였습니다.
실험을 통해 2가지 방법 모두 효율적이라는 것을 보일 수 있었습니다.
2. Neural Machine Translation
NMT는 source sentence x_1 ~ x_n이 주어졌을 때 target sentence y_1 ~ y_m으로 번역되는 조건부 확률 p(y|x)를 modeling하는 신경망입니다.
기본적인 NMT는 2가지 구성요소를 지니고 있습니다.
- Encoder : 각 source sentence S의 representation을 계산합니다.
- Decoder : 각 시간마다 target word를 만들어내며 조건부 확률을 아래 식과 같이 분해합니다.
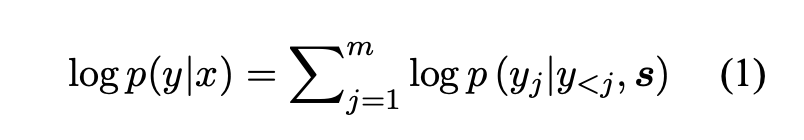
위와 같이 decoder의 분해에 사용되는 model은 RNN 구조를 주로 사용합니다. 이와 관련된 논문은 매우 다양하지만 어떤 RNN 구조가 decoder에 사용되고 어떻게 source sentence representation s를 encoder가 계산하는 지 모두 다릅니다.
Kalchbrenner and Blunsom (2013)에서는 decoder에서 standard hidden unit을 지닌 RNN을 사용하고 source sentence representation encoder에서 CNN을 사용하였습니다.
Sutskever et al. (2014)와 Luong et al. (2015)에서는 RNN을 여러층 쌓아 LSTM hidden unit으로 encoder와 decoder에 사용하였습니다.
Cho et al. (2015)와 Bahdanau et al. (2015) Jean et al. (2015)에서는 다른 형식의 RNN의 hidden unit으로 GRU를 사용하였습니다.
좀 더 자세히 설명하자면, 각 단어 y_j를 아래 식과 같이 decoding하는 확률을 parameterize할 수 있습니다.

3. Attention-based Models
해당 논문에서 제시하는 attention based model은 global과 local 2가지로 분류할 수 있습니다. 이는 attention이 모든 source 위치에서 적용되느냐 아니면 일부에 적용되느냐의 차이를 기준으로 나뉘어집니다.
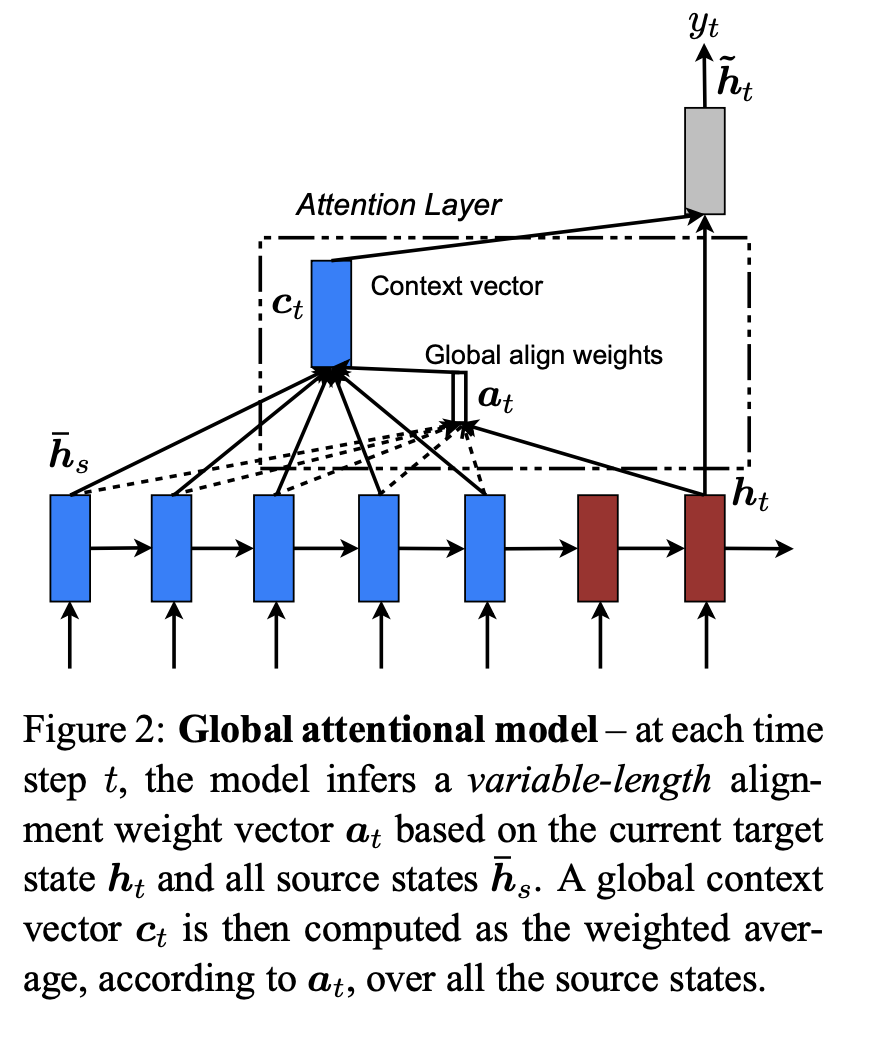
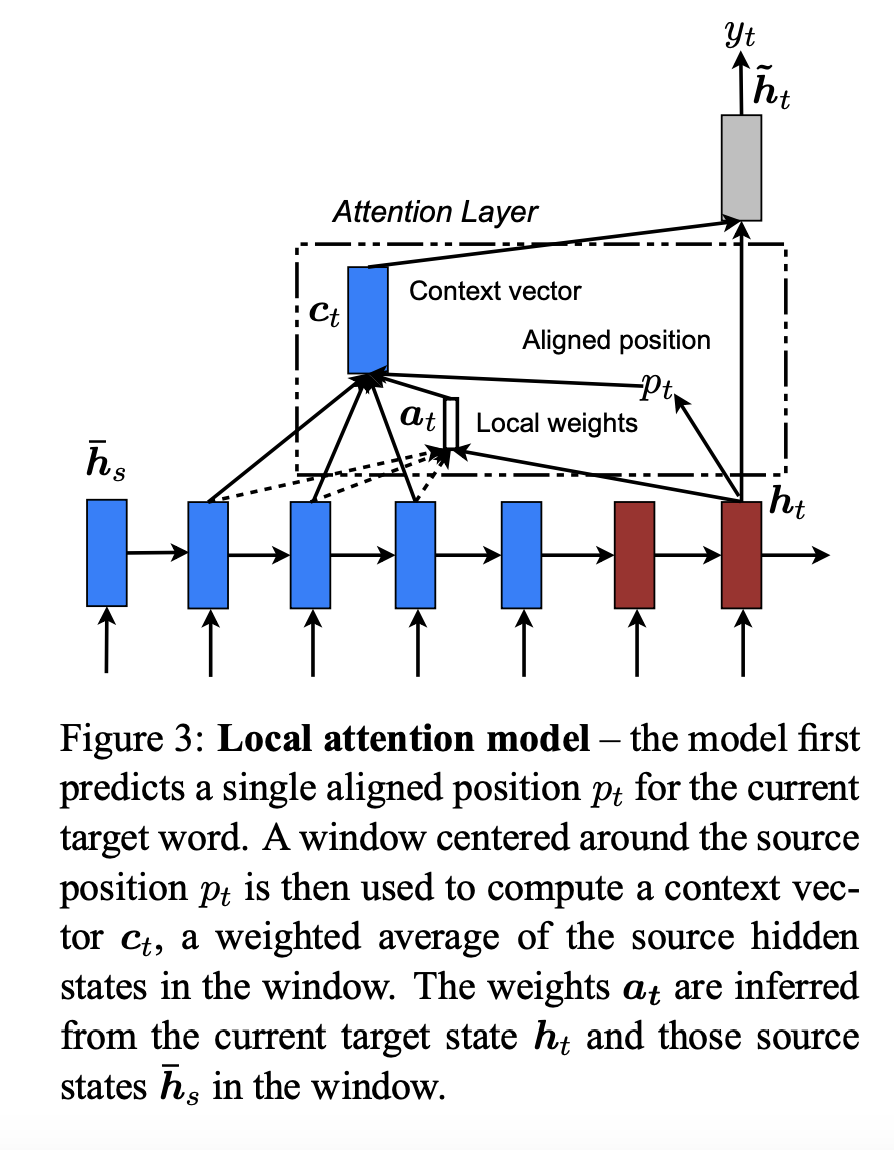
위 2가지 model의 공통점은 decoding의 각 time step t마다 hidden state h_t를 stacking LSTM인 top layer의 input으로 사용한다는 것입니다. 이 때 목적은 현재의 target word y_t를 예측하는 데 도움을 줄 수 있는 관련있는 source-side information을 갖고 있는 context vector c_t를 얻는 것입니다. 위 두 모델은 context vector c_t를 얻을 때 방식에 차이가 있습니다.
Target hidden state h_t와 source-side context vector c_t가 주어졌을 때 해당 논문에서는 attentional hidden state를 만들어내기 위한 두 vector로부터 정보를 결합해주는 simple concatenation layer를 활용합니다.
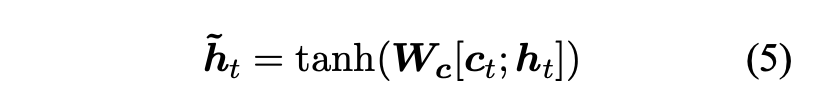
Attentional vector h_t^hat 은 softmax layer로 들어가 predictive distribution을 만들어냅니다.

3.1 Global Attention
Global attention model의 아이디어는 encoder의 모든 hidden state를 고려하여 context vector c_t를 만들어내는 것입니다. 이런 model에서 크기가 source side의 각 step의 개수와 길이가 변하는 vector a_t는 현재의 target hidden state h_t와 각 source hidden state h_s^-와 비교하여 만들어집니다.

따라서 score는 content-based function으로 여겨집니다.

해당 논문에서는 아래 식과 같은 location-based function을 사용하였습니다.
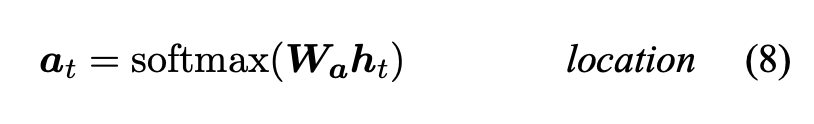
Alignment vector를 가중치로써 사용한다면 context vector c_t는 모든 source hidden state들의 가중평균으로 계산됩니다.
해당 논문에서는 encoder와 decoder 모두에서 top LSTM layer의 hidden state를 사용했습니다. 하지만 Bahdanau et al. (2015)에서는 bi-directional encoder와 non-stacking unidirectional decoder의 target hidden states를 concatenation하여 사용했습니다. 둘째로 해당 논문의 연산 path는 단순합니다. 해당 논문에서는 h_t -> a_t -> c_t -> h_t^hat으로 연산이 이루어지지만 Bahdanau et al. (2015)에서는 h_t-1 -> a_t -> c_t -> h_t 순으로 연산이 이루어집니다. 마지막으로 Bahdanau et al. (2015)는 하나의 alignment function인 concat product만 사용하였지만 해당 논문에서는 다른 대안들이 더 낫다는 것을 보여줍니다.
3.2 Local Attention
Global attention은 각 target word마다 모든 source side의 모든 단어들을 attend해야하는 단점이 있으며 이는 계산 비용이 많이 들고 매우 긴 문장을 translate할 때는 효율적이지 못합니다. 이런 단점을 해결하기 위해 해당 논문에서는 매 target word마다 source word의 일부만을 사용하여 attend하는 local attention을 소개합니다.
Local attention은 soft attention model과 hard attention model 사이의 tradeoff에서 영감을 얻었습니다. Soft attention은 가중치들이 source image의 모든 patche마다 softly하게 가중치로 사용되는 global attention approach입니다. Hard attention은 한 번에 하나의 image patch만 선택하여 attend 합니다. Inference time이 적게 들지만 hard attention model은 미분 불가능했으며 variance reduction이나 reinforcement learning과 같은 복잡한 방법들이 학습 시 필요했습니다.
해당 논문의 local attention은 선택적으로 context의 small window에 집중하고 미분 가능합니다. 이는 soft attention의 많은 계산 비용을 피함과 동시에 hard attention보다 학습이 쉽습니다. 자세히 설명하자면 local attention은 먼저 time t의 target word의 aligned position p_t를 만듭니다. 그 후 context vector c_t는 window [p_t-D, p_t+D] 안에 있는 source hidden state들의 가중평균을 통해 얻을 수 있습니다. 이 때 D는 경험적으로 선택됩니다.
Global approach와 달리 local alignment vector a_t는 고정된 dimension을 갖습니다.
- Monotonic alignment (local-m) : p_t = t 로 가정하여 source와 target이 단순하게 monotonically하게 align
- Predictive alignment (local-p) : 해당 model에서는 aligned position을 다음과 같이 predict 합니다.

3.3 Input-feeding Approach
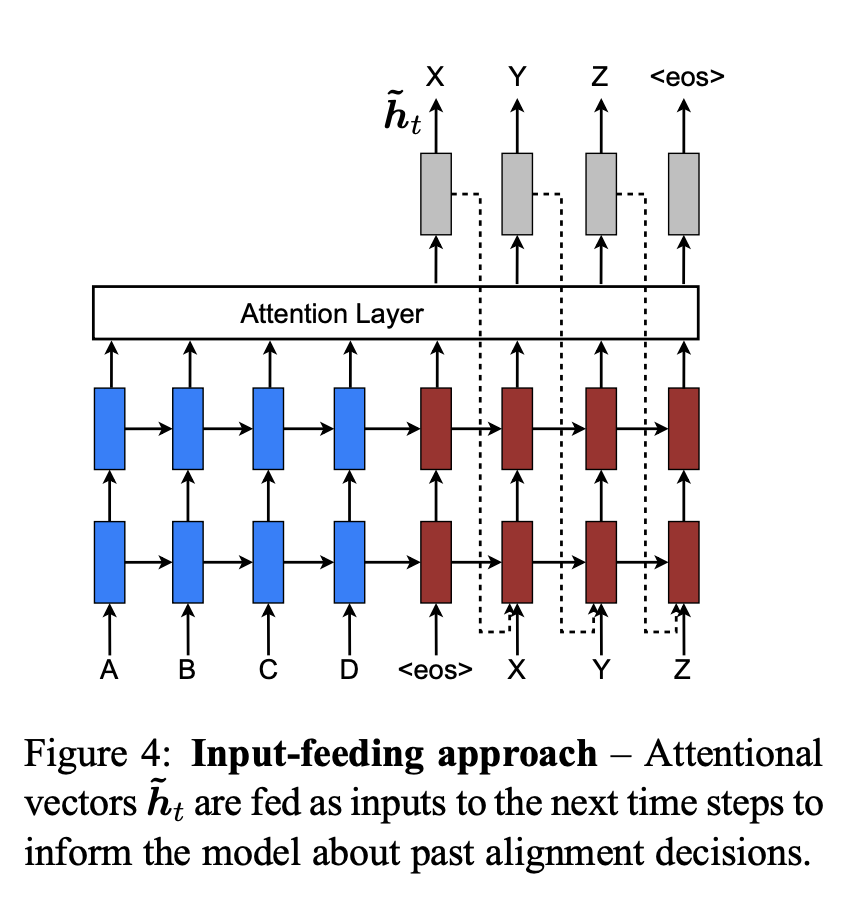
4. Experiments
4.1 Training Details
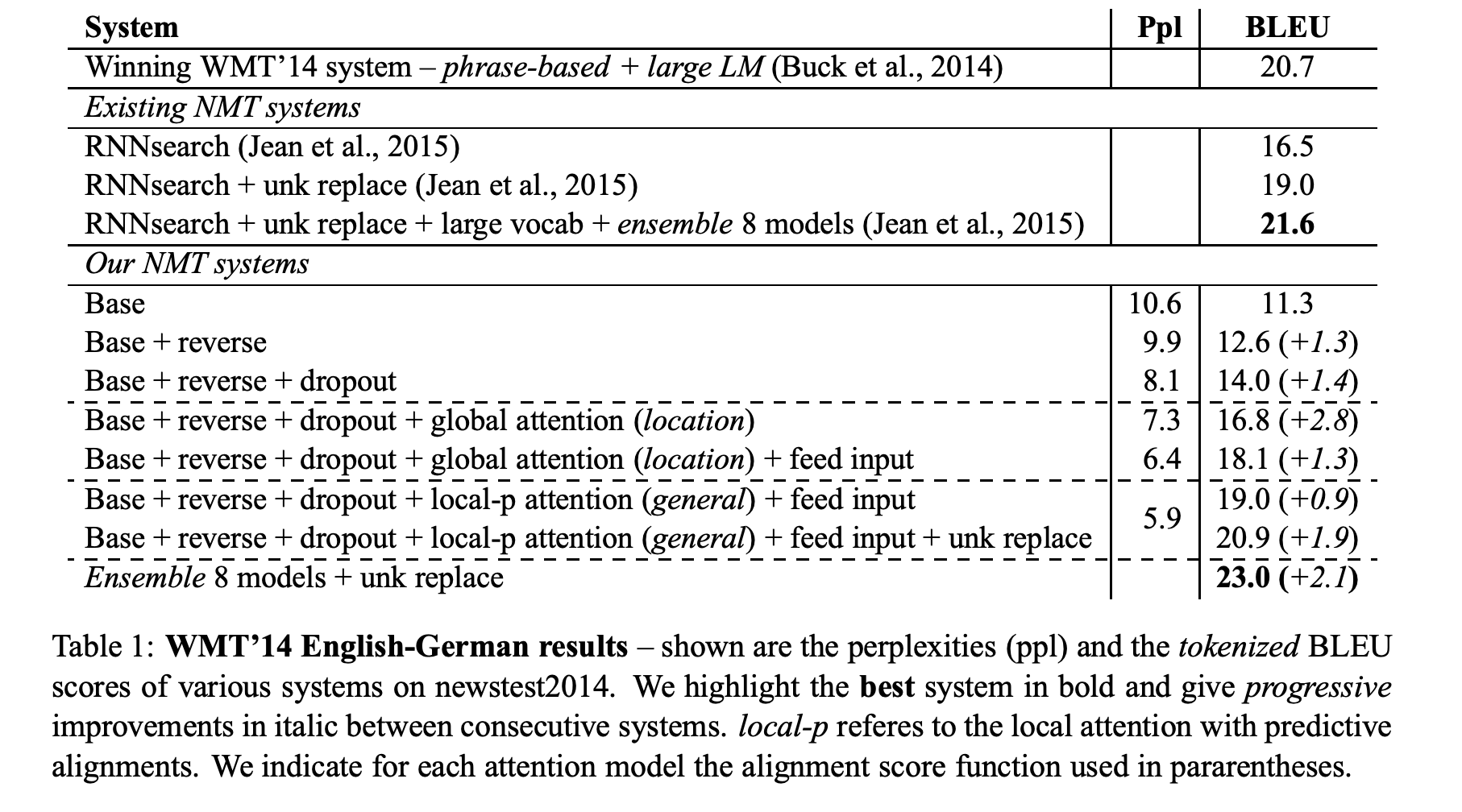
4.2 English-German Results

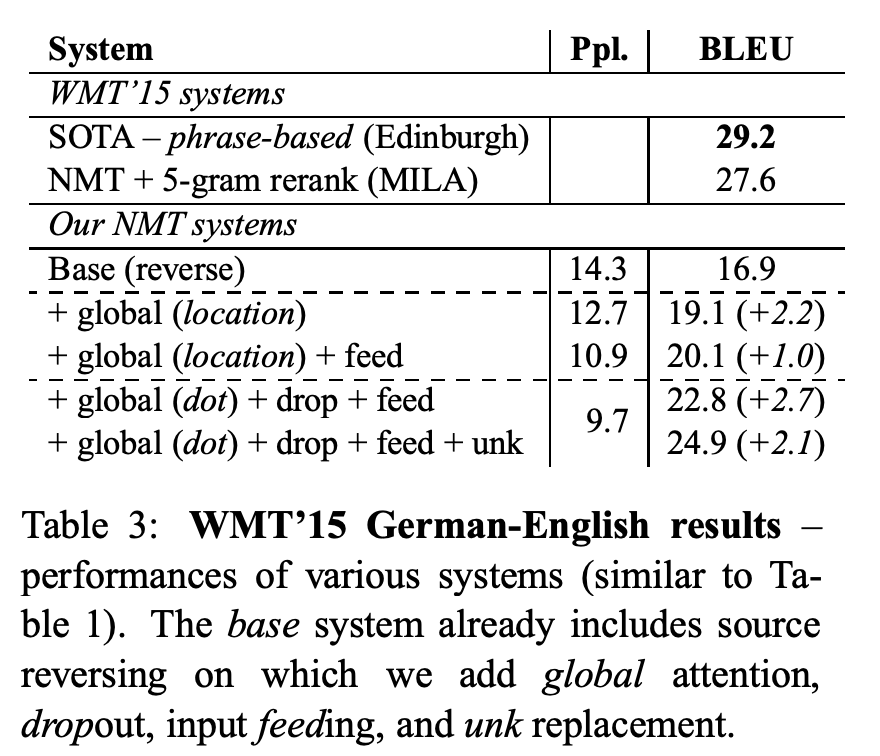
4.3 German-English Results
5. Analysis
5.1 Learning curves

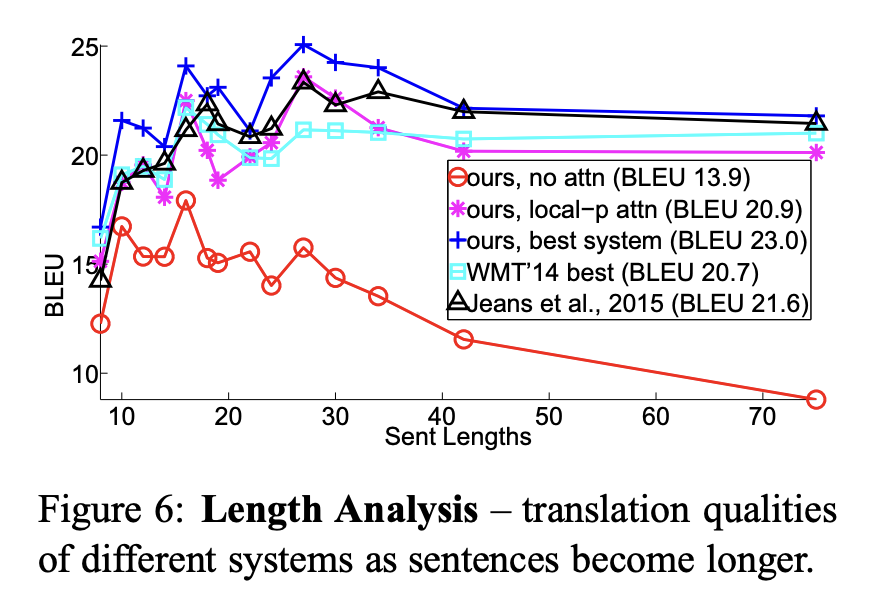
5.2 Effects of Translating Long Sentences
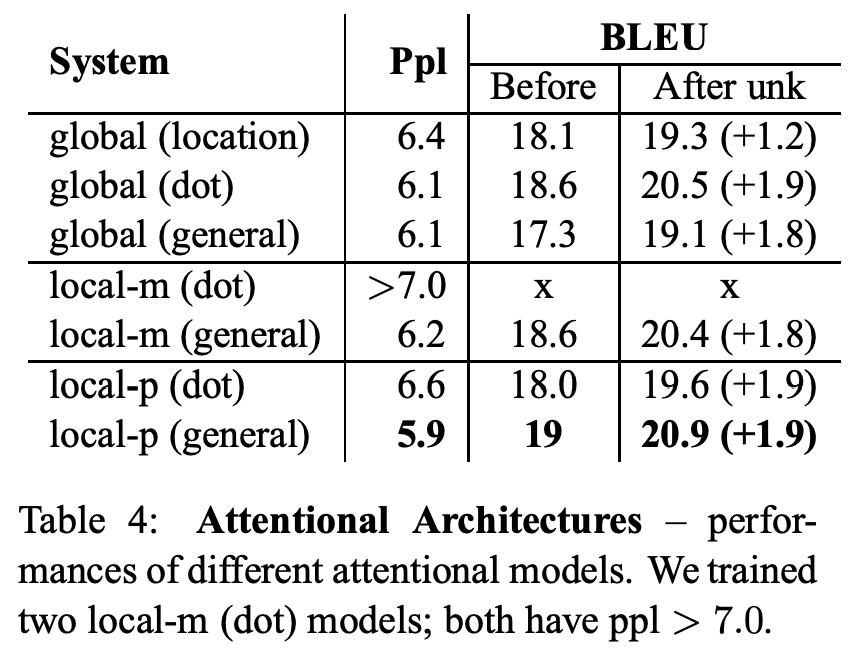
5.3 Choices of Attentional Architectures
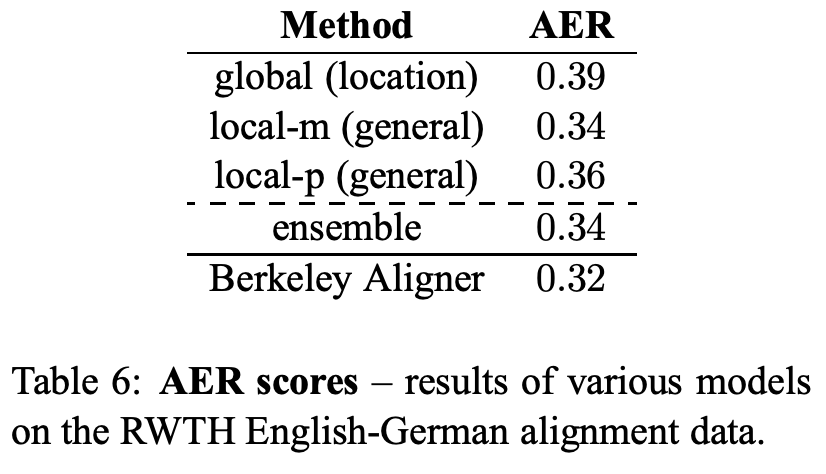
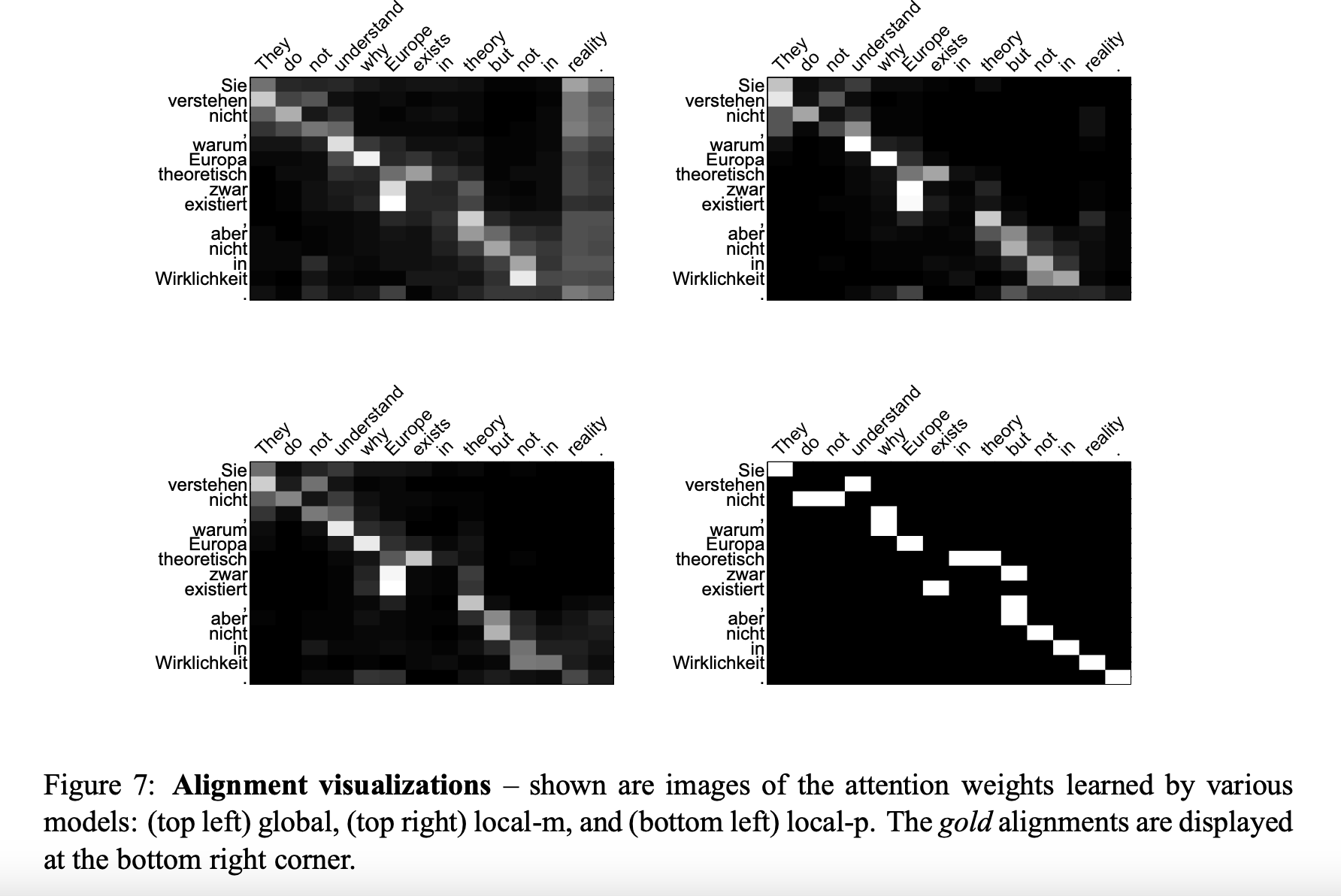
5.4 Alignment Quality
5.5 Sample Translations

6. Conclusion
해당 논문에서는 NMT를 위한 단순하면서 효율적인 attentional mechanism 2가지를 소개합니다. Global approach는 모든 source에 대해서 attend하고 local approach는 source의 일부만을 attend하여 사용합니다.
또한 해당 논문에서는 attention-based NMT model들이 non-attentional NMT보다 많은 경우 성능이 좋다는 것을 보였습니다.
