Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Paper_review
RNN Encoder-Decoder 모델을 소개하면서 추후 GRU라고 이름붙은 LSTM 변형 Unit을 소개하는 논문입니다.
[Abstract]
해당 논문에서는 RNN Encoder-Decoder라고 불리는 2개의 RNN(Recurrent Neural Network)들로 구성된 새로운 neural network model을 소개합니다. 2개 중 1개의 RNN은 symbol들의 sequence를 고정된 길이의 vector representation으로 encode하는 역할을 하며 나머지 1개의 RNN은 vector representation을 또 다른 symbol들의 sequnce로 decode하는 역할을 합니다. 소개하는 모델의 encoder와 decoder는 source sequence가 주어졌을 때 target sequence의 조건부 확률을 최대화할 수 있도록 jointly하게 학습됩니다. 해당 논문에서는 소개하고 있는 모델이 linguistic phrase의 의미적, 문법적으로 의미있는 내용을 잘 학습한다는 것을 보여줍니다.
1. Introduction
최근 많은 연구들에서 NLP의 많은 task에서 neural network가 성공적으로 사용될 수 있다는 것을 보여주었습니다. SMT(Statistical Machine Translation) 분야에서 deep neural network는 꽤 좋은 성능을 보이기 시작하였습니다. 해당 논문에서는 전통적인 phrase-based SMT system의 일부로 사용할 수 있는 새로운 neural network 구조에 집중하였습니다. RNN Encoder-Decoder로 부르는 encoder와 decoder로 사용되는 2개의 RNN으로 구성된 새로운 모델을 소개합니다. Encoder는 고정되지 않은 길이의 source sequence를 고정된 길이의 vector로 mapping해주고 decoder는 vector representation을 고정되지 않은 길이의 target sequence로 mapping 해줍니다. Encoder와 decoder는 source sequence가 주어졌을 때 target sequence의 조건부 확률을 최대화시키는 방향으로 같이 학습됩니다. 추가적으로 해당 논문에서는 memory capacity와 학습의 편의를 모두 향상시킬 수 있는 hidden unit을 활용합니다.
소개되는 model은 phrase 쌍 간의 score 측정을 통해 standard pharse-based SMT system의 일부분으로 사용할 수 있습니다. 실험을 통해 해당 모델을 사용하여 얻은 score를 활용하여 번역의 성능을 향상시킬 수 있었습니다.
해당 논문에서는 학습된 RNN Encoder-Decoder를 기존의 번역 model들과의 phrase score를 비교하여 정성적으로도 분석하였습니다. 정성 분석 결과는 RNN Encoder-Decoder가 linguistic regualrity를 잘 포착한다는 것을 보여주었습니다. RNN Encoder-Decoder는 phrase 구조의 의미적, 문법적 구조를 모두 보존하면서 continuous representation을 학습합니다.
2. RNN Encoder-Decoder
2.1 Preliminary : Recurrent Neural Network
RNN은 고정되지 않은 길이의 sequence x = (x1 ~ x_T)에 적용되는 hidden state h와 선택적으로 사용되는 output Y로 구성된 neural network입니다. 매 time step t마다 hidden state h(t)는 아래 식을 통해 갱신됩니다.
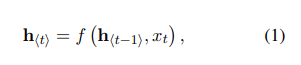
f는 non-linear activation function으로 logistic sigmoid함수처럼 단순할 수도 있고, LSTM(Long Short-Term Memory)처럼 복잡할 수도 있습니다.
RNN은 sequence의 다음 symbol을 예측하는 과정을 통해 sequence의 확률분포를 학습할 수 있습니다. 이 때 time step t의 output은 조건부 확률분포 p(xt|x(t-1) ~ x_1)입니다.

2.2 RNN Encoder-Decoder
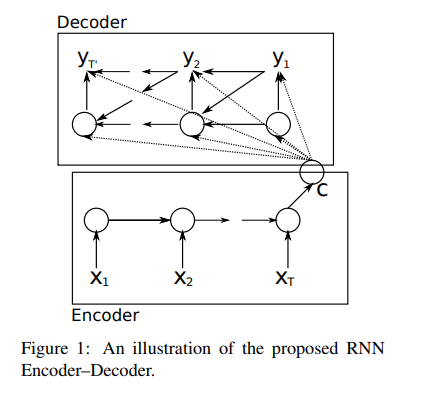
해당 논문에서는 고정되지 않은 길이의 sequence를 고정 길이의 vector representation으로 encode하고, 고정 길이의 vector representation을 고정되지 않은 길이의 sequence로 다시 decode할 수 있도록 학습하는 새로운 neural network를 소개합니다. 확률적인 시각에서 제안하는 모델은 하나의 고정되지 않은 길이의 sequence가 주어졌을 때 또 다른 고정되지 않은 길이의 sequence의 조건부 확률분포(p(y1 ~ y_T' | x_1 ~ x_T), T!=T')를 학습하는 일반적인 방법으로 볼 수 있습니다.
Encoder는 input sequence x의 각 symbol들을 순차적으로 읽습니다. 각 symbol들을 통해 식 (1)을 활용하여 RNN의 hidden state는 변화합니다. Sequence의 가장 마지막 symbol이 통과된 후의 만들어진 RNN의 hidden state c는 input sequence의 요약된 정보로 생각할 수 있습니다.
Decoder는 hidden state h(t)가 주어졌을 때 다음 symbol yt를 예측하는 방식으로 output sequence를 만들어 낼 수 있도록 학습된 RNN입니다. 앞서 설명된 기본적인 RNN과 달리 y_t와 h(t)는 모두 y_(t-1)과 input sequence의 summary c에 의존합니다. 따라서 time step t에서 decoder의 hidden state는 아래 식과 같이 계산됩니다.

소개되는 모델 RNN Encoder-Decoder의 encoder와 decoder는 아래의 조건부 log-likelihood를 최대화 하는 방식으로 학습됩니다. 이 때 theta는 model의 parameter set이고 (x_n, y_n)은 training set의 (input sequence, output sequence) pair 입니다.
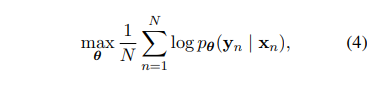
RNN Encoder-Decoder가 학습이 되면, 이 모델은 2가지 방식으로 사용할 수 있습니다. 첫 번째 방식은 model을 input sequence가 주어졌을 때 target sequence를 만들어낼 수 있도록 사용하는 것입니다. 또 다른 방법은 model은 주어진 input, output pair간의 score를 측정하는 데 사용할 수 있습니다. 이 때 score는 식 (3)과 (4)로부터 확률 p_theta(y|x) 값을 사용합니다.
2.3 Hidden Unit that Adaptively Remembers and Forgets
해당 논문에서는 또한, 새로운 hidden unit(식 (1)의 함수 f 역할)을 소개합니다. 소개하는 새로운 hidden unit은 LSTM unit에서 영감을 받았지만 계산과 실제 수행 과정이 좀 더 단순합니다.
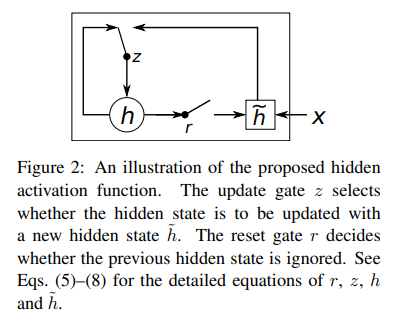
Reset gate r_j는 식 (5)를 통해 계산됩니다.

Update gate z_j는 식 (6)을 통해 계산됩니다.
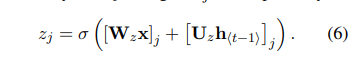
새로 소개되는 hidden unit의 activation hj는 식 (7)을 통해 계산되며 이 때 사용되는 candidate activation h(t)는 식 (8)에 의해 계산됩니다.
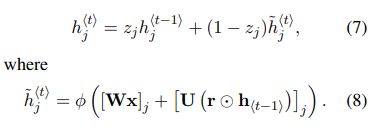
위 식들을 살펴보면, reset gate가 0에 가까운 값을 가질 때는 hidden state는 과거의 hidden state 값을 완전히 무시하고 current input만으로 값을 초기화합니다. 이러한 방식은 효율적으로 hidden state가 미래 결과와 관련이 없는 정보를 제거하여 compact한 representation을 가질 수 있도록 해줍니다.
Update gate는 과거의 hidden state를 현재 hidden state에 얼만큼 갖고 올 것인지 조절해줍니다. 이는 LSTM의 memory cell과 유사한 역할을 하며 RNN이 long-term 정보를 학습할 수 있도록 도움을 줍니다.
각 hidden unit들은 reset gate와 update gate를 분리하였기 때문에, hidden unit들은 서로 다른 time scale의 dependency를 잡아낼 수 있도록 학습할 수 있습니다. Shor-term dependency를 포착하는 역할을 하는 unit은 reset gate가 자주 active되어 현재의 input 값으로 초기화 하는 과정을 자주 수행하도록 학습될 것이고, long-term dependency를 포착하는 역할을 하는 unit은 long-term 정보를 학습하는 update gate를 자주 active 시킬 것입니다.
3. Statistical Machine Translation
SMT system의 목적은 source setence e가 주어졌을 때 아래 식을 최대화 시키면서 translation f를 찾는 것을 목적으로 합니다.
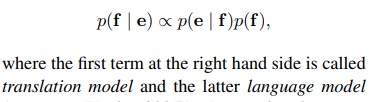
하지만 대부분의 SMT system은 log(p(f|e))를 additional feature들과 corresponding weight들을 활용하여 아래 식과 같이 모델링합니다.

3.1 Scoring Phrase Pairs with RNN Encoder-Decoder
해당 논문에서는 RNN Encdoer-Decoder를 phrase pair들에 대해 학습하고 이로부터 구한 score 값을 식 (9) log-linear model의 additional feature로 활용하여 SMT decoder tuning 시에 활용합니다.
RNN Encoder-Decoder를 학습할 때, original corpus에서 phrase pair들의 (normalized) 빈도수를 무시하였습니다. 이러한 방식은 2가지 목적으로 수행되었습니다. 첫째, 매우 많은 phrase pair들에서 임의로 뽑는 계산 비용을 줄이기 위함입니다. 둘째, RNN Encoder-Decoder가 빈도수에 의존하지 않도록 하기 위함입니다. 해당 논문에서는 RNN Encoder-Decoder 모델이 linguistic regularity(번역의 성능, 잘 된 번역의 manifold 학습) 자체만을 학습하는 것에 집중하였습니다.
RNN Encoder-Decoder가 학습이 되면, 각 phrase pair의 새로운 점수로 phrase table을 수정하였습니다. 이를 통해 기존 tuning 알고리즘에 최소한의 계산 비용만으로 새로운 score를 포함시킬 수 있게 되었습니다. 해당 논문에서는 기존에 존재하는 pharse table의 pharse pair들에 대해서만 score 값을 새로 매겼습니다.
3.2 Related Approaches: Neural Networks in Machine Translation
실험 결과를 보여주기 전에, SMT system에 neural network를 활용한 다른 연구들을 소개합니다.
(Schewent. 2012)에서는 phrase pair에 scoring을 하는 유사한 방식을 소개했었습니다. 해당 연구에서는 고정된 크기의 input에 대해 feedforward network를 사용하여 고정된 크기의 output을 활용하였습니다. Phrase의 길이가 길어지고 고정되지 않은 길이의 sequence data를 활용하기 위해서는 고정되지 않은 길이의 input, output을 다룰 수 있는 neural network가 필요했습니다. 해당 논문에서 소개하는 RNN Encoder-Decoder는 그러한 목적에 잘 부합했습니다.
(Devlin et al., 2014)에서는 (Schewent. 2012)과 유사하게 feedforward network를 사용하였지만 target phrase의 단어 하나만 예측하는 방식을 활용하였습니다. 성능의 향상은 있었지만, 여전히 input phrase 길이의 고정된 최대값이 존재하였습니다.
(Zou et al., 2013) 연구에서는 완전한 neural network는 아니지만 bilingual embedding을 학습하였습니다. (Zou et al., 2013) 연구는 phrase pair간의 거리를 계산하기 위하여 embedding을 학습하였고 계사된 거리를 SMT system의 additional feature로 활용하였습니다.
(Chandar et al., 2014)에서는 input phrase의 bag-of-words representation을 output phrase로 mapping하기 위해 feedfowrad neural network를 학습하였습니다. Bag-of-words를 활용한 유사한 연구가 (Gao et al., 2013)에서도 소개되었습니다. 2개의 recursive neural network를 사용한 encoder-decoder model은 (Socher et al., 2011)에서 소개되었지만 monolingual setting이라는 제약사항이 있었습니다.
RNN Encoder-Decoder는 같은 단어들로 이루어져 있더라도 순서가 다르다면 이를 구분할 수 있었습니다.
RNN Encoder-Decoder와 가장 유사한 방법은 (Kalchbrenner and Blunsom, 2013)에서 소개된 Recurrent Continuous Translation Model입니다. (Kalchbrenner and Blunsom, 2013)에서 encoder와 decoder로 수성된 유사한 모델을 제안하였습니다. RNN Encoder-Decoder와의 차이는 (Kalchbrenner and Blunsom, 2013)는 convolutional n-gram model(CGM)을 encoder로 활용하였고 decoder로 inverse CGM과 recurrent neural network의 혼합을 사용했다는 점입니다.
4. Experiments
4.1 Data and Baseline System
4.1.1 RNN Encoder-Decoder
RNN Encoder-Decoder는 새롭게 제안한 1000개의 hidden units을 encoder, decoder에 사용하였습니다.
각 단어마다 100차원의 embedding을 학습하기 위해 rank-100 matrix를 사용하였습니다.
식 (8)의 candidate hidden state의 activation function으로는 tanh를 사용하였습니다.
RNN Encoder-Decoder의 recurrent 가중치 행렬을 제외한 모든 가중치 parameter들은 표준편차가 0.01인 isotropic zero-mean(white) Gaussian 분포에서 추출되었습니다. Recuurent 가중치 행렬에는 white Gaussian 분포에서 먼저 추출 후 left singular vector matrix를 사용하였습니다.
학습에는 Adadelta와 stochastic gradient descent를 사용하였습니다.
4.1.2 Neural Language Model
RNN Encoder-Decoder의 scoring 효율성을 평가하기 위해 target lanugage model(CSLM) 학습을 위한 neural network 사용하는 전통적인 방식을 시도하였습니다.
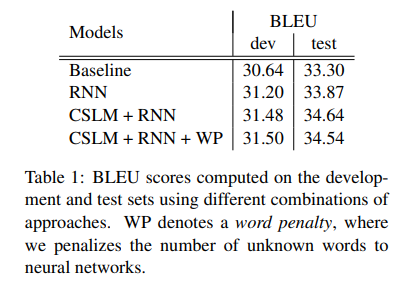
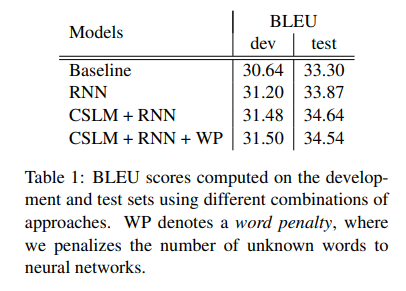
4.2 Quantitative Analysis
- Baseline configuration
- Baseline + RNN
- Baseline + CSLM + RNN
- Baseline + CSLM + RNN + Word penalty
4.3 Qualitative Analysis

RNN Encoder-Decoder에서 선택한 target phrase 실제 번역과 가장 가까웠습니다. RNN Encoder-Decoder는 일반적으로 짧은 phrase를 선호한다는 것도 확인할 수 있습니다.
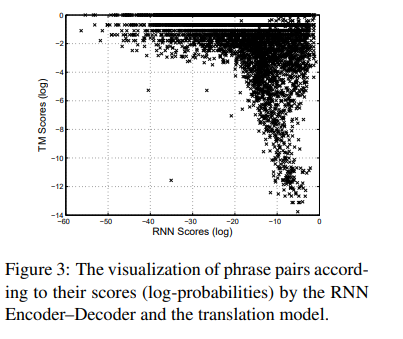
다수의 phrase pair에서 translation model과 RNN Encoder-Decoder의 score가 유사했지만 극단적으로 다른 경우도 많았습니다.

RNN Encoder-Decoder는 실제 pharse table과 유사한 제대로 만들어진 형태의 target phrase를 결과로 보여주었습니다.
4.4 Word and Phrase Representation
Neural network를 활용한 continuous space lanugage model들은 의미적으로 유의한 embedding을 학습할 수 있다고 알려져 있습니다. RNN Encoder-Decoder 역시 단어를 continuous space vector에 mapping할 수 있습니다.

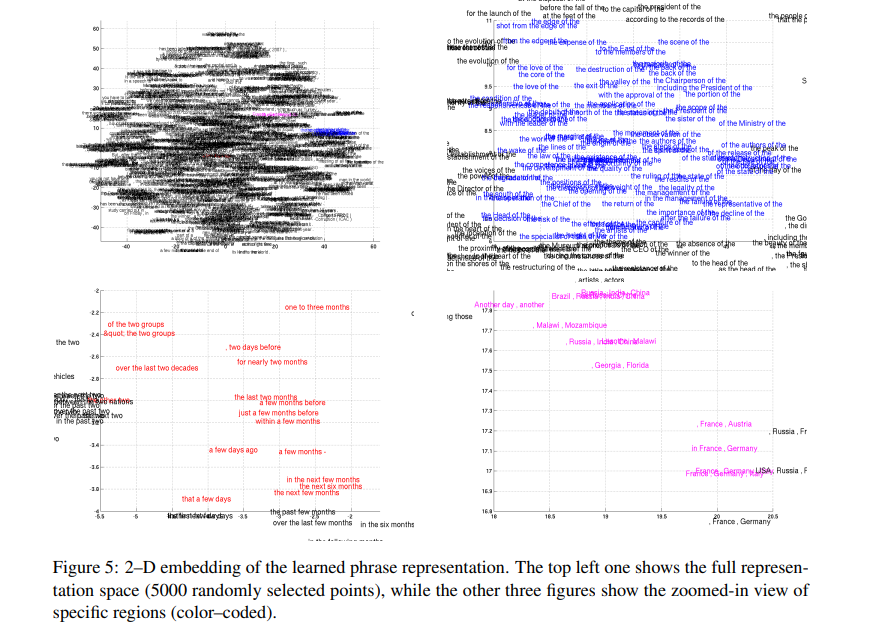
위 두 그림을 통해 RNN Encoder-Decoder는 의미적으로 문법적으로 의미있는 구조 정보를 잘 잡아낸 다는 것을 알 수 있습니다.
5. Conclusion
해당 논문에서는 RNN Encoder-Decoder라고 부르는 새로운 neural network architecture를 소개하였습니다. RNN Encoder-Decoder는 임의의 길이의 sequence를 또 다른 종류의 임이의 길이의 sequence로 mapping 시키도록 학습되었습니다. RNN Encoder-Decoder는 조건부 확률을 활용하여 sequence pair 간의 score를 구할 수 있고, source sequence가 주어졌을 때 target sequence를 만들어낼 수도 있습니다. 새로운 architecture와 더불어 해당 논문에서는 reset gate와 update gate로 이루어진 새로운 hidden unit 역시 소개합니다.
정성적으로 해당 논문에서는 제안하고 있는 모델이 phrase pair에서 linguisitc regularity를 잘 잡아낼 수 있고 잘 만들어진 phrase를 만들어낼 수 있다는 것을 보였습니다.
RNN Encoder-Decoder를 통해 만들어낸 score는 전반적인 번역 성능 향상에 기여하였습니다.
