Dropout을 non-recurrent connection에만 적용하여 RNN 계열에 dropout을 활용할 수 있는 방법을 제안하는 논문입니다.
[Abstract]
해당 논문에서는 LSTM(Long Short-term Memory) unit을 활용하는 RNN(Recurrent Neural Network)를 쉽게 regularization할 수 있는 방법을 소개합니다. 신경망을 regularization하는 가장 성공적인 방법인 dropout은 RNN와 LSTM에 잘 적용되지 않았습니다. 해당 논문에서는 LSTM에 dropout을 효율적으로 적용하는 방법을 소개하고 다양한 task에서 overfitting을 효율적으로 감소시킬 수 있음을 보여줍니다.
1. Introduction
RNN은 NLP의 다양한 분야에서 SOTA 성능을 보인 neural sequence model입니다. Neural network를 성공적으로 사용하기 위해서는 좋은 regularization이 필요하다는 것이 알려져 있습니다. 불행히도 feedforward neural network에서 가장 효과적인 regularization 방법인 dropout은 RNN에서는 유사한 성능을 보이지 않았습니다. 그 결과 RNN을 활용할 때는 큰 size의 RNN은 overfitting 되는 경향이 있기 때문에 매우 작은 size의 RNN을 사용하게 되었습니다. 해당 논문에서는 dropout을 제대로 사용한다면 LSTM의 overfitting을 효율적으로 막아주는 것을 보여주고, 3가지 task에서 성능을 평가하였습니다.
2. Related work
Dropout은 feed-forward neural network에서 가장 성공적인 regularization 방법으로 최근에 소개되었습니다. 다양하게 dropout이 활용되고 있지만 RNN에 적용하는 연구는 상대적으로 거의 없습니다. 과거 한 연구에서는 기본적인 dropout은 recurrence가 noise를 증폭시키고 이것이 곧 학습에 좋지 않은 영향을 주기 때문에 RNN에 잘 적용되지 않는다고 하였습니다. 해당 논문에서는 RNN의 특정 부분에만 dropout을 적용함으로써 이 문제를 해결하고자 하였습니다. 결과적으로 RNN 역시 dropout의 이점을 누릴 수 있게 되었습니다.
해당 논문에서는 LSTM에 dropout을 어떻게 알맞게 적용하는지 보였습니다. 이러한 방식은 또 다른 RNN 기반의 architecture에도 잘 적용될 가능성이 있습니다.
3. Regularizing RNNs with LSTM cells
- all state are n-dimensional
- (h_t)^l : hidden state in layer l in timestep t
- T_(n,m) : n차원에서 m차원으로 변화시키는 affine transform(Wx+b for some W, b)
- ⊙ : element-wise multiplication
- (h_t)^0 : input word vector at timestep t
- (h_t)^L : activations to predict y_t
- L : the number of layesr in deep LSTM
3.1 Long Short-term Memory units
기본 RNN은 아래 식과 같이 표현할 수 있습니다.
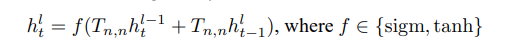
LSTM은 여러 차원의 timestep의 정보를 손쉽게 기억하기 위해 좀 더 복잡한 구조로 이루어져 있습니다. Long term memory는 memory cell (c_t)^l에 저장되어 있습니다. 다양한 LSTM architecture들이 connectivity structure와 activation function들이 다르지만, 모든 LSTM architecture들은 장기간의 정보를 저장하기 위한 memory cell을 갖고 있습니다. LSTM은 memory cell을 덮어쓰거나, 찾고, 다음 time step으로 넘겨줄 것을 결정합니다. LSTM의 식은 아래 식과 같이 표현할 수 있습니다.

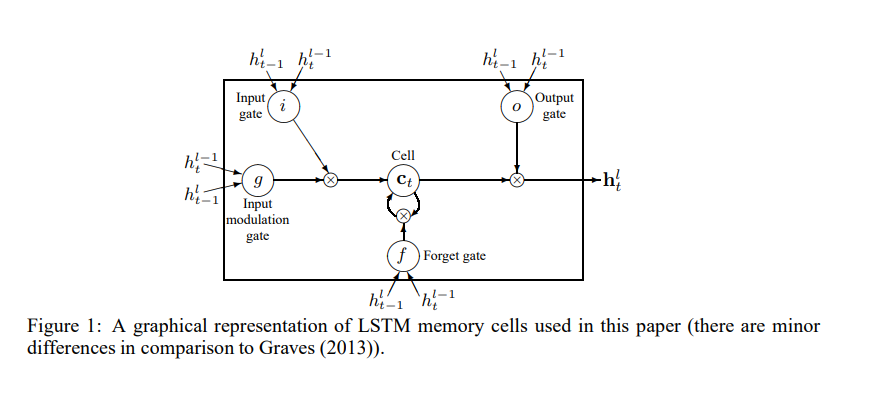
3.2 Regularization with Dropout
해당 논문의 주된 contribution은 성공적으로 overfitting을 줄일 수 있도록 dropout을 LSTM에 적용하는 방법을 제안했다는 점입니다. 주된 아이디어는 dropout을 non-recurrent connection에만 적용한다는 것입니다.

해당 아이디어는 아래 식과 같이 표현할 수 있습니다. D는 dropout operator로 일부분이 0으로 setting되어 있습니다.

Dropout은 unit에 의해 전달되는 정보들을 변형시키고 unit들이 중간 계산을 좀 더 robustly하게 할 수 있도록 해줍니다. 동시에 unit들로부터 나오는 정보들이 없어지는 것을 방지해야만 합니다. 먼 과거에서 발생한 정보들을 unit들이 갖고 있어야 하는 것은 매우 중요합니다. 아래 사진은 정보들이 어떻게 timestep에 따라 흘러가는지 보여줍니다.

일반적인 dropout은 recurrent connection을 교란하여 LSTM이 장기간의 정보를 갖고 학습하는 것을 어렵게 합니다. Dropout을 recurrent connection에는 사용하지 않음으로써, LSTM은 memorization 기능을 포기하지 않은 채로 dropout의 regularization의 이점을 얻을 수 있게 되었습니다.
4. Experiments
4.1 Language modeling
해당 논문에서는 PTB data를 활용하여 단어 수준 language modeling 실험을 수행하였습니다.
Hidden state는 0으로 초기화하고, minibatch size는 20을 사용하였습니다.
- Medium LSTM : 650 units per layer, paramter들은 [-0.05,0.05] 사이의 값으로 uniformly하게 초기화, non-recurrent connection에 대해 50%의 dropout, 39 epochs, learning rate 1, 6 epochs 이후에는 각 epoch마다 1.2 factor만큼씩 learning rate를 감소, gradient norm을 5를 기준으로 clip
- Large LSTM : 1500 units per layer, paramter들은 [-0.04,0.04] 사이의 값으로 uniformly하게 초기화, non-recurrent connection에 대해 65%의 dropout, 55 epochs, learning rate 1, 14 epochs 이후에는 각 epoch마다 1.15 factor만큼씩 learning rate를 감소, gradient norm을 10를 기준으로 clip
- Non-regularized LSTM : 200 units per layer, paramter들은 [-0.1,0.1] 사이의 값으로 uniformly하게 초기화, 13 epochs, learning rate 1, 4 epochs 이후에는 각 epoch마다 2 factor만큼씩 learning rate를 감소


4.2 Speech recognition

4.3 Machine translation
- 4 hidden layer, both layers and word embedding have 1000 unit
- dropout rate = 0.2

4.4 Image caption generation
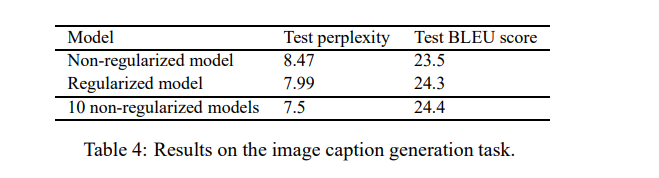
5. Conclusion
해당 논문에서는 LSTM에 dropout을 적용할 수 있는 간단한 방법을 소개하고 결과적으로 서로 다른 task들에서 큰 성능 향상을 얻을 수 있었습니다. 해당 논문의 방식으로 RNN에 dropout을 사용할 수 있도록 해주었고 해당 논문의 결과는 제안한 방식의 dropout 활용이 다양하게 적용되어 성능 향상을 이룰 수 있다고 보여줍니다.
