Union-Find
Disjoint Set이란 ?
💡 Union-Find 표현하기 위한 자료구조로 서로 중복되지 않는 부분 집합들로 나눠진 원소들에 대한 정보를 저장하고 조작하는 자료구조이다. 즉, 공통 원소가 없는 부분 집합들로 나눠진 원소들에 대한 자료구조이다.Union-Find 알고리즘
💡 Disjoint Set을 표현할 때 사용하는 알고리즘으로 Disjoint Set을 구현하는 데는 비트 벡터, 배열, 연결 리스트를 이용할 수 있으나 가장 효율적인 트리 구조를 이용하여 구현한다.Union-Find의 연산
- make-set(x)
- 초기화 시키는 단계로 x를 유일한 원소로 하는 새로운 집합을 만든다.
- union(x, y)
- 합집합의 연산으로 x가 속한 집합과 y가 속한 집합을 합친다.
- find(x)
- x가 속한 집합의 대표 값(부모)를 반환한다.
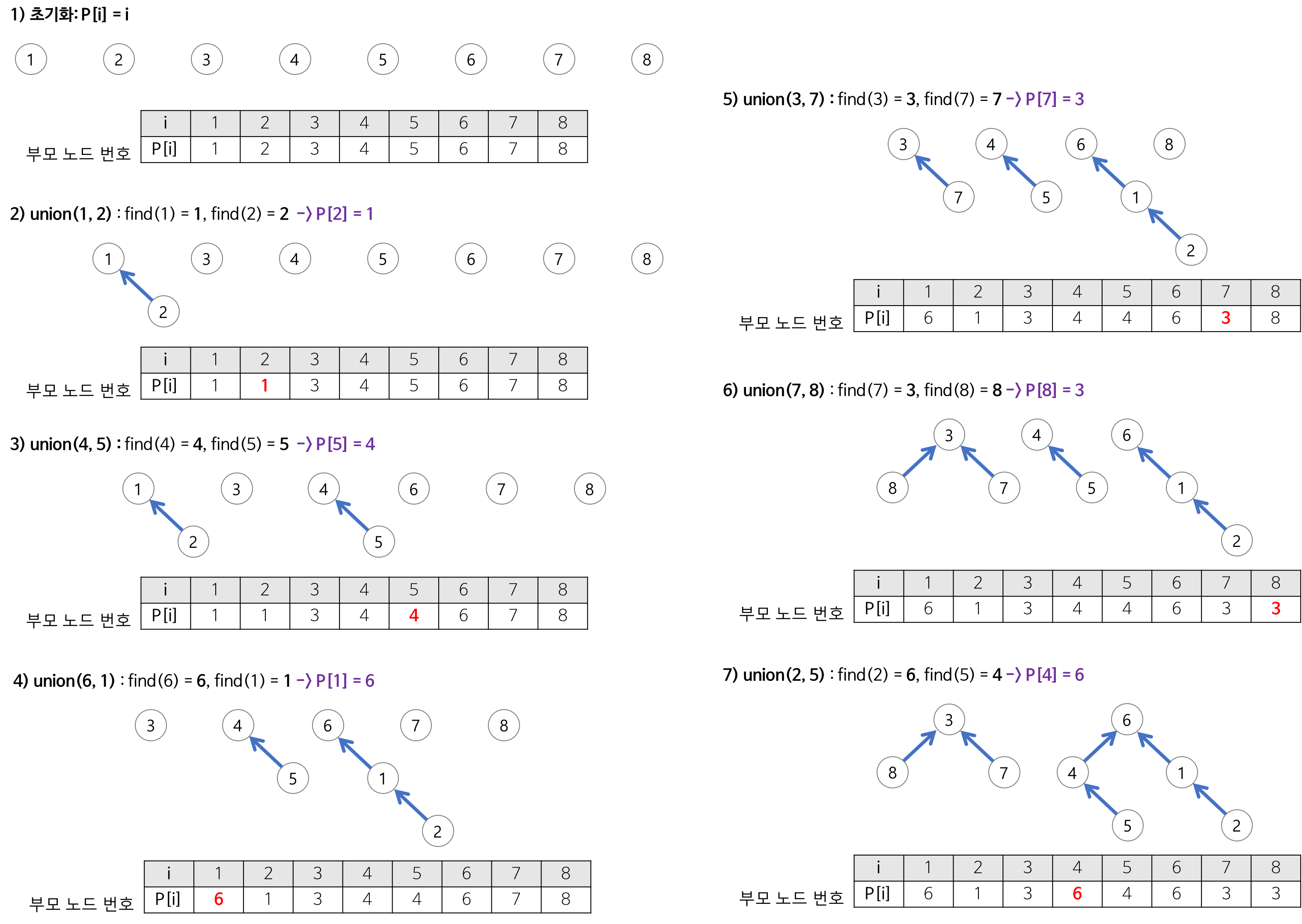
구현
int root[MAX_SIZE];
for(int i = 0; i < MAX_SIZE; i++) {
root[i] = i;
}
int find(int x) {
if(root[x] == x) {
return x;
} else {
return find[root[x]]; // 재귀를 통해 부모 노드의 값을 찾는다.
}
}
void union(int x, int y) {
x = find(x); // x의 부모 노드
y = find(y); // y의 부모 노드
root[y] = x; // y의 부모 노드를 x로 바꿔주면서 x와 y를 이어준다.
}4️⃣ Union-Find 알고리즘 코딩테스트 예제
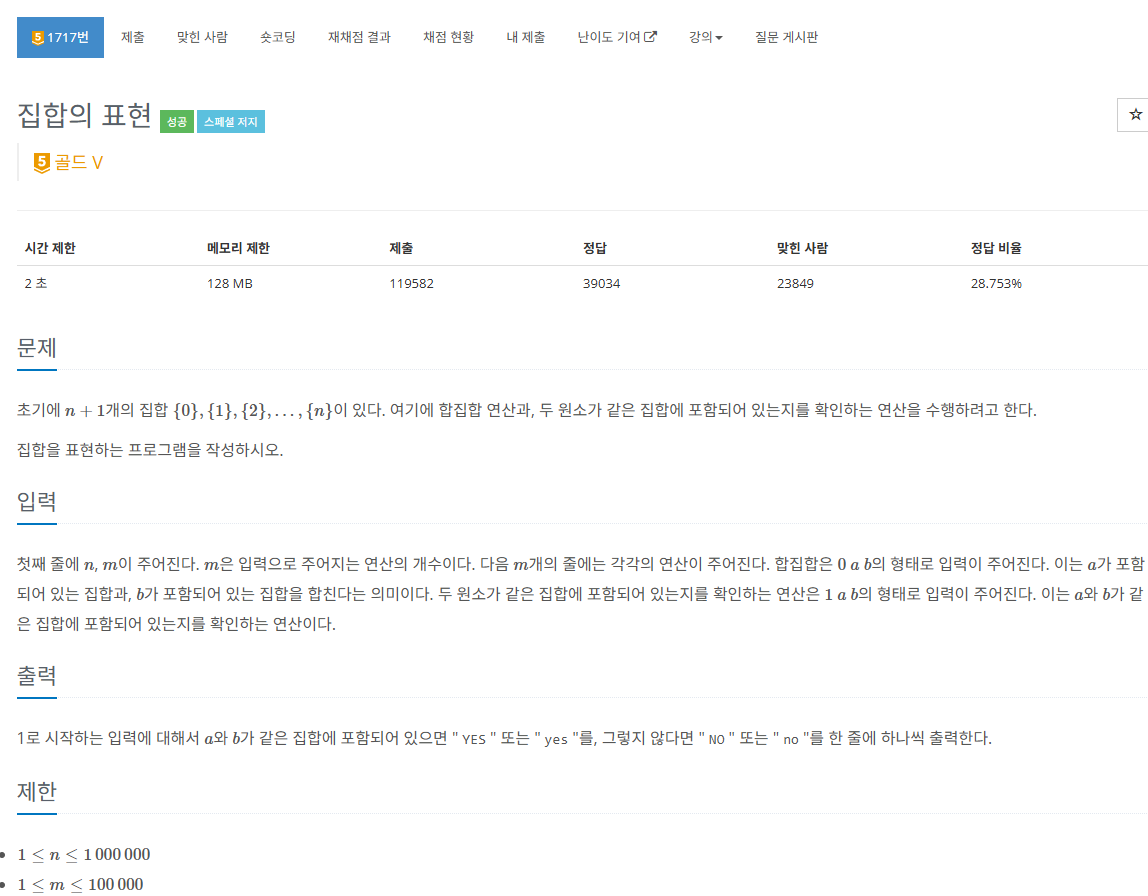
📌 문제 탐색하기
🌝 입력
- 첫째 줄에 N, M이 주어진다. M은 입력으로 주어지는 연산의 개수이다. (1 <= N <= 1,000,000, 1 <= M <= 100,000)
- 다음 M개의 줄에 각각의 연산이 주어진다. 합집합은 0 a b의 형태로 두 원소가 같은 집합에 포함되어 있는 지를 확인하는 연산은 1 a b의 형태로 입력이 주어진다.
🌑 출력
1로 시작하는 입력에 대해 a와 b가 같은 집합에 포함되어 있으면 "YES" 그렇지 않으면 "NO"를 한 줄에 하나씩 출력한다.
🕔 시간제한
2초
🚨 접근
Union-Find 알고리즘을 활용해보자.
- 0 a b의 형태로 나오면 union 작업을 수행하고 1 a b의 형태로 나오면 find 작업을 수행하여 답을 구해보자.
- Union-Find를 알기 전엔 이 문제를 Set을 이용해 집합을 합쳐 중복 수를 없애 find 작업이 나오면 해당 Set에 값이 있는 지 판단하였었는데 이는 메모리 초과를 피할 수 없었다.
🙆♂️ 가능한 시간복잡도
이중 반복 수행 불가능
- N이 1,000,000개이고 M이 100,000이기 때문에 이중으로 반복 수행하는 경우 시간 초과가 발생한다.
📌 정답 코드
import java.util.*;
import java.io.*;
public class Main {
static int[] arr;
static int find(int a) {
if(arr[a] == a) {
return a;
} else {
return find(arr[a]); // 부모 노드 탐색
}
}
static void union(int a, int b) {
int x = find(a);
int y = find(b);
arr[y] = x; // x를 y의 부모로 지정하여 두 집합을 합치는 작업
}
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
arr = new int[n+1];
for(int i = 0; i <= n; i++) {
arr[i] = i;
}
StringBuilder sb = new StringBuilder();
for(int i = 0; i < m; i++) {
st = new StringTokenizer(br.readLine());
int digits = Integer.parseInt(st.nextToken());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
if(digits == 1) {
if(find(a) == find(b)) sb.append("YES").append("\n"); // 두 부모가 같으면 같은 트리에 속해있다.
else sb.append("NO").append("\n");
} else {
union(a,b);
}
}
System.out.println(sb);
}
}Reference
