알고리즘
1.[알고리즘] 선택 정렬(Selection Sort)이란 ?

📁선택정렬 1️⃣ 선택 정렬의 과정 데이터에서 최솟(최댓)값을 찾는다. 남은 데이터에서 가장 앞에 있는 데이터와 선택된 데이터를 swap한다. 정렬되지 않은 가장 앞에 있는 데이터의 위치를 변경한다. 전체 데이터 크기만큼 index가 커질 때까지, 즉 남은 정렬
2.[알고리즘] 삽입 정렬(Insertion Sort)이란 ?
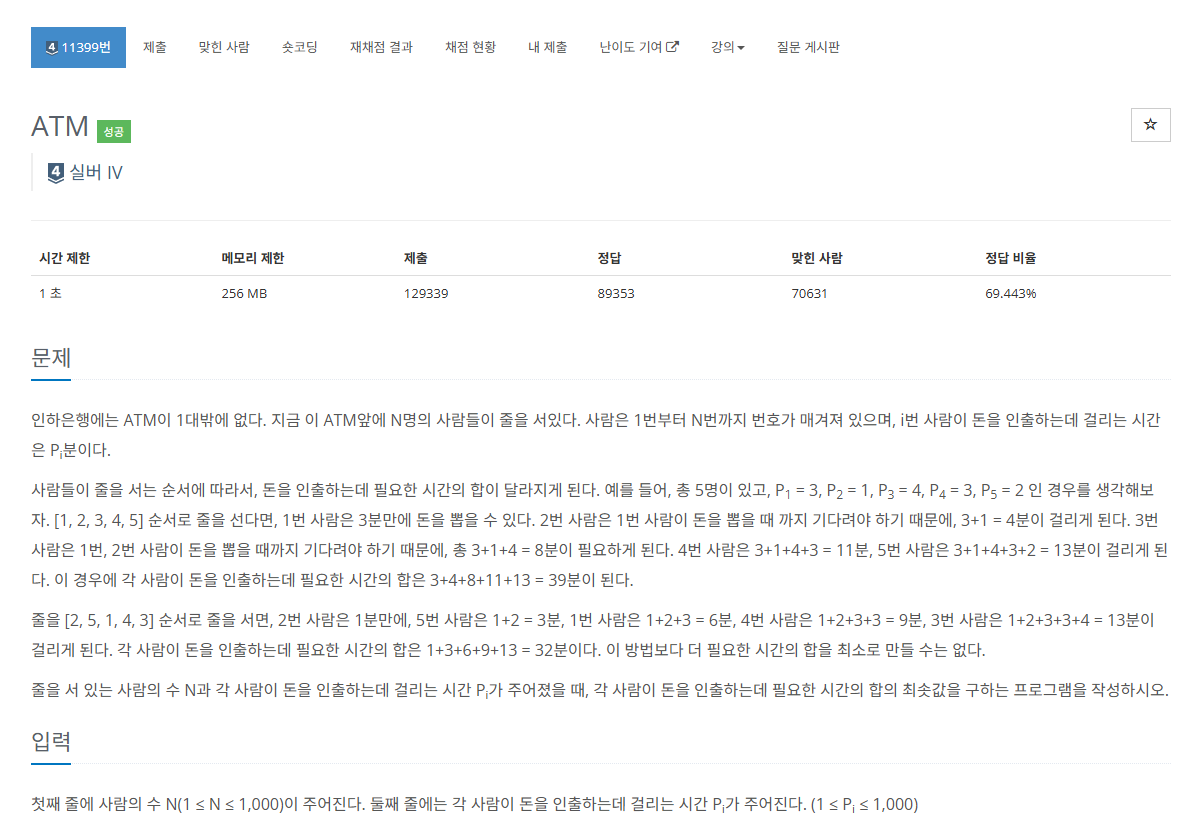
선택 인덱스(=index 1)의 데이터를 선택한다.선택 인덱스의 데이터보다 인덱스 값이 작은 위치에 선택 데이터보다 큰 값이 존재하지 않을 때까지 위치를 변경한다.마지막 변경 인덱스와 선택 인덱스와 위치 변경삽입 정렬은 안정 정렬(Stable Sort)이다.같은 값을
3.[알고리즘] 퀵 정렬(Quick Sort)이란 ?

📁퀵 정렬 1️⃣ 퀵 정렬의 과정 pivot 값을 선정한다. image.png 분할(Divide) : 입력 배열을 pivot을 기준으로 비균등하게 2개의 서브 리스트로 분할한다. (1차 Swap) : 35는 Pivot보다 크고, 26은 Pivo
4.[알고리즘] 버블 정렬(Bubble Sort)이란 ?

두 인접한 데이터의 크기를 비교해 정렬하는 방법으로 시간복잡도는 O(n²)이지만, 간단하게 구현할 수 있어 자주 사용한다.앞에서부터 인접한 데이터 값을 비교한다.현재 데이터와 다음 데이터를 비교한다.만약 다음 데이터가 더 작다면 위치를 바꾸고 아니라면 그대로 둔다.다음
5.[알고리즘] 병합 정렬(Merge Sort)이란 ?

배열을 앞부분과 뒷부분으로 나누어 각각 정렬한 다음 합병하는 작업을 반복하는 정렬로 효율적이고 안정적인 알고리즘 중 하나로, 분할 정복(Divide and Conquer) 알고리즘을 따른다.배열 요소 개수가 2개 이상인 경우(길이가 1 이하이면 이미 정렬된 내용)분할(
6.[알고리즘] 기수 정렬(Radix Sort)이란 ?

📁기수 정렬 > 낮은 자리수부터 비교하여 정렬해간다는 것을 기본 개념으로 하는 알고리즘으로 비교 연산을 하지 않으며 정렬 속도가 빠르지만 데이터 전체 크기에 기수 테이블의 크기만한 메모리가 더 필요하다는 단점이 있다. 1️⃣ 기수 정렬의 과정 이미지 출처: m
7.[알고리즘] BFS(Breadth-First Search)이란 ?
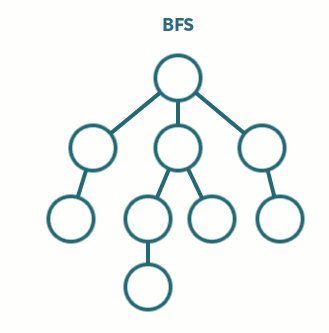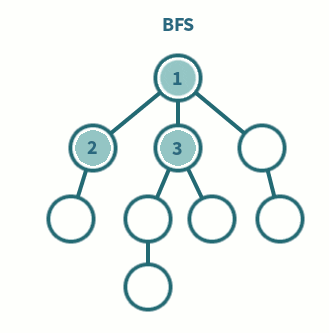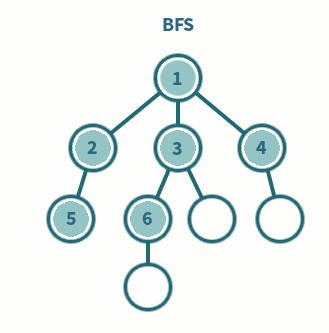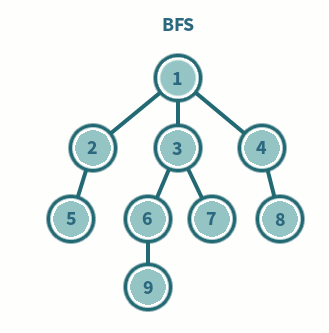
트리나 그래프를 탐색하는 기법 중 하나로, 루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법으로 깊게 탐색하기 전에 넓게 탐색하는 것이다.두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 사용한다.미로 찾기 등 최단 거리를 구
8.[알고리즘] 브루트포스(Brute Force Search)이란 ?

Brute : 무식한Force : 힘직역하면 무식한 힘을 갖는 알고리즘이라는 뜻으로 가능한 모든 경우의 수를 모두 탐색하면서 결과를 도출하여 완전 탐색 알고리즘의 한 종류이지만 완전 탐색의 또 다른 이름으로 불리기도 한다.브루트포스 알고리즘은 대부분 반복문과 조건문을
9.[알고리즘] 그리디 알고리즘(Greedy Algorithm)이란 ?
그리디 알고리즘 그리디 알고리즘(탐욕법, Greedy Algorithm) 💡 최적의 값을 구해야 하는 상황에서 사용되는 근시안적인 방법론으로 ‘각 단계에서 최적이라고 생각되는 것을 선택’해 나가는 방식으로 진행하여 최종적인 해답에 도달하는 알고리즘 이 때, 항
10.[알고리즘] Union-Find 알고리즘이란 ?
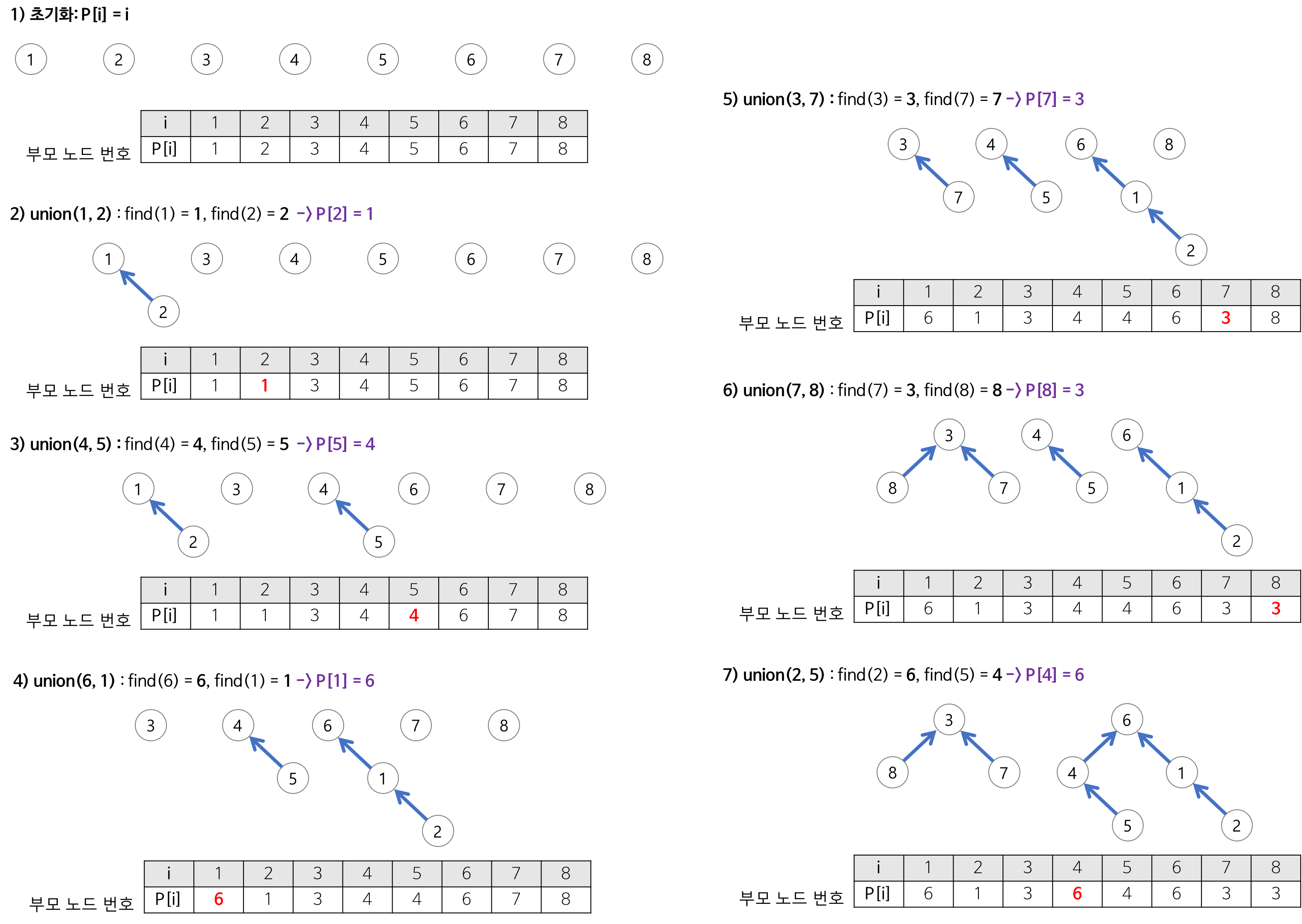
make-set(x)초기화 시키는 단계로 x를 유일한 원소로 하는 새로운 집합을 만든다.union(x, y)합집합의 연산으로 x가 속한 집합과 y가 속한 집합을 합친다.find(x)x가 속한 집합의 대표 값(부모)를 반환한다.1717\. 집합의 표현첫째 줄에 N, M이