
Typescript를 다루면서 개인적으로 가장(?) 중요한 개념 중 하나는 바로 구조적 타이핑이라고 생각한다.
어디로 튈지 모르는 Typescript만의 기본적인 동작원리를 이해하는 가장 큰 기반이 되며,
구조적 타이핑을 이해 한다면 (썸네일에 보이듯이) 헷갈릴 수 있는 유니온 타입(|)과 인터섹션 타입(&)도 어느정도 예측 할 수 있기 때문이다.
그러므로 여기서는 구조적 타이핑의 기본적인 개념과
이를 기반으로 집합의 관점에서 유니온 타입(|)과 인터섹션 타입(&)의 기본적인 동작 원리를 알아볼 것이다.
구조적 타이핑이란?
TypeScript는 타입의 이름이 아닌, 타입의 구조(프로퍼티와 메소드의 형태)를 기준으로 타입의 호환성을 판단한다.
이것을 구조적 타이핑(Structural type system) 이라고 한다.
-
구조적 타이핑으로 인해 객체의 프로퍼티가 같고 타입이 같으면, 두 객체는 서로 같은 타입으로 취급될 수 있다.
-
즉, 이름이 다른 객체라도 가진 속성이 동일하다면 타입스크립트는 서로 호환이 가능한 동일한 타입으로 여기는 것이다.
간단한 예시를 한번 보자.
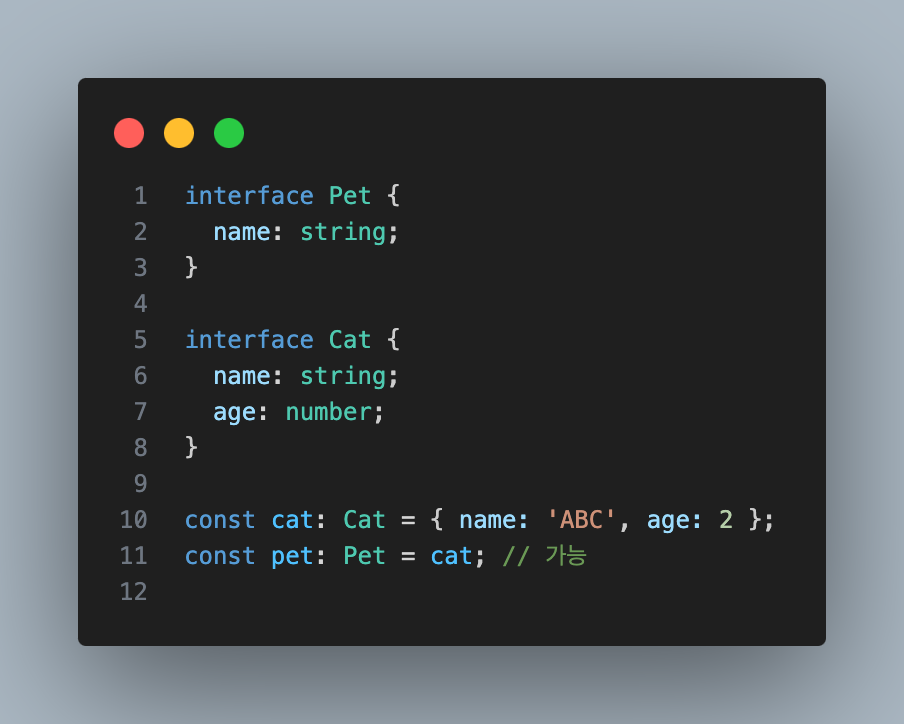
Cat은 Pet과 다른 타입으로 선언됐지만, Pet이 갖고 있는 name이라는 속성을 가지고 있다.
따라서 Cat 타입으로 선언한 cat을 Pet타입으로 선언한 pet에 할당할 수 있다.
상위타입과 하위 타입
TypeScript는 구조적 타이핑을 기반으로, ‘하위 타입을 상위 타입에’ 할당 가능하다고 간주한다.
그러므로 상위 타입이 요구하는 속성을 모두 갖춘다면 하위 타입은 상위 타입에 포함된다.
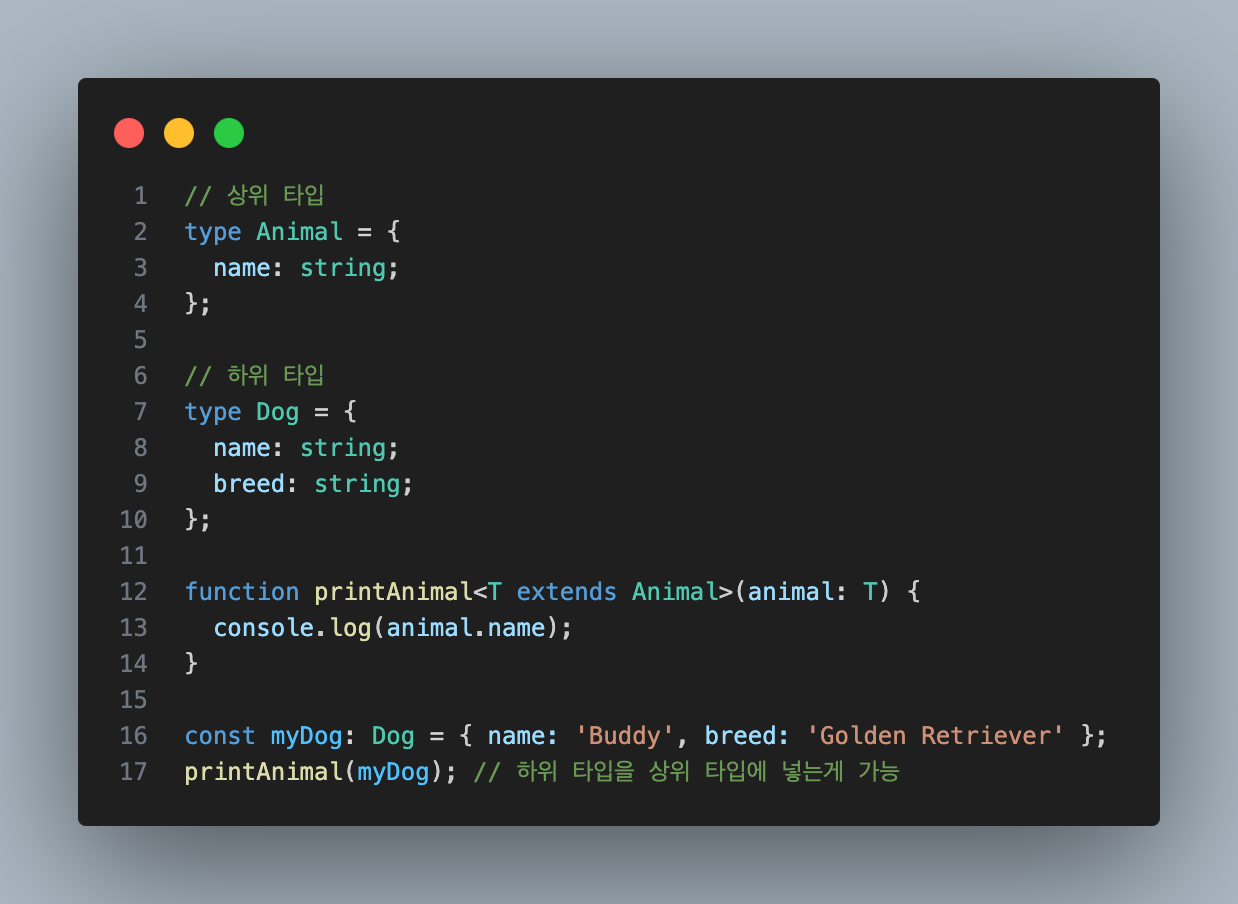
위의 경우 Dog는 Animal을 확장(extend)한 타입이 된다.
그러므로 Dog는 Animal에 할당 가능하고 T extends Animal 조건을 만족하게 된다.
'JS의 값 공간'과, 'TS의 타입 공간' 모두에서 사용될 수 있는 것으로 class가 있는데,
class의 상속구조 역시 구조적 타이핑을 기반으로 하고 있다.
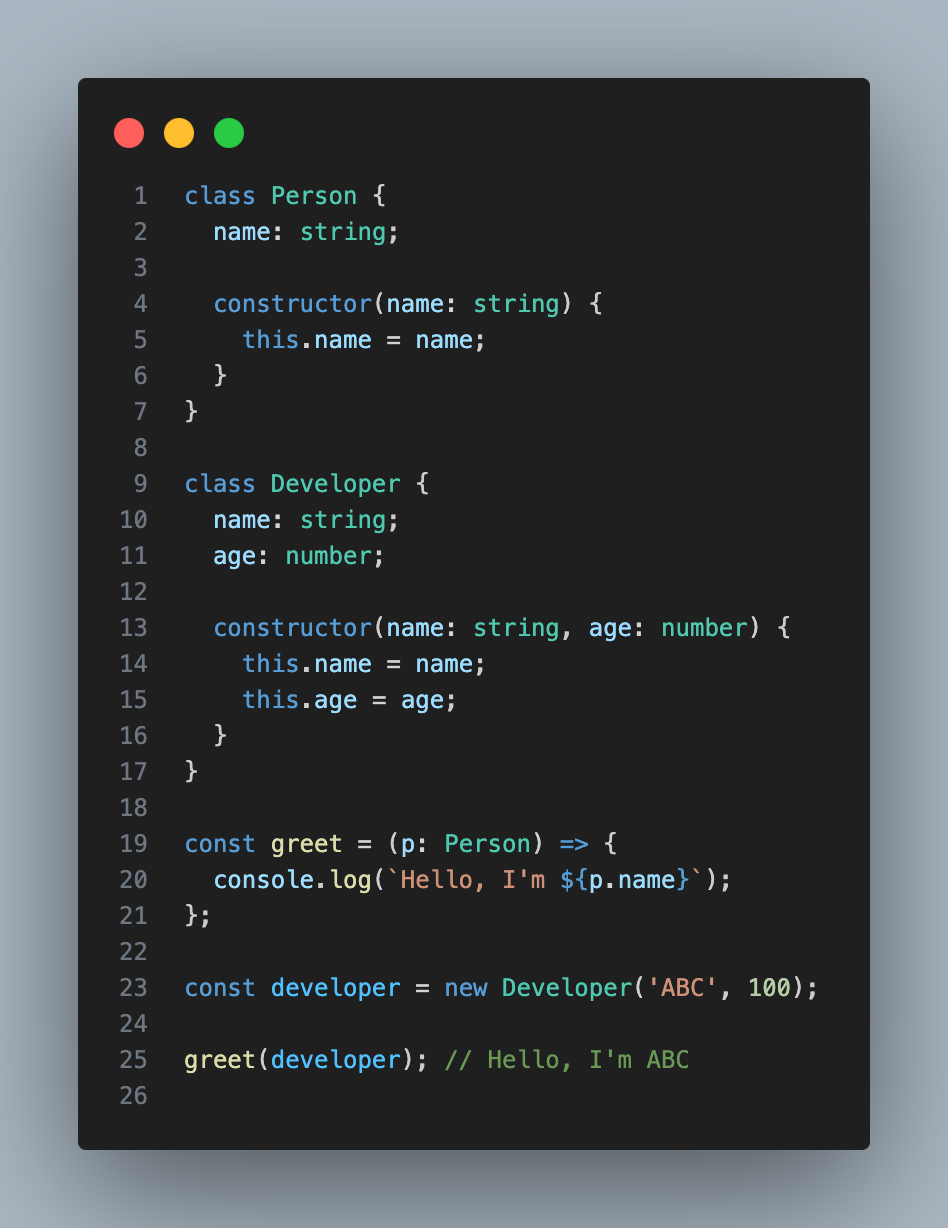
Developer가 Person을 상속받지 않았는데도 greet(developer)는 정상적으로 동작한다.
이는 Developer가 Person의 속성을 모두 가지고 있기 때문이다.
타입 A가 타입 B의 서브타입이라면 A 타입의 인스턴스는 B 타입이 필요한 곳에 언제든지 위치할 수 있다.
즉, 타입이 계층 구조로부터 자유로운 것이다.
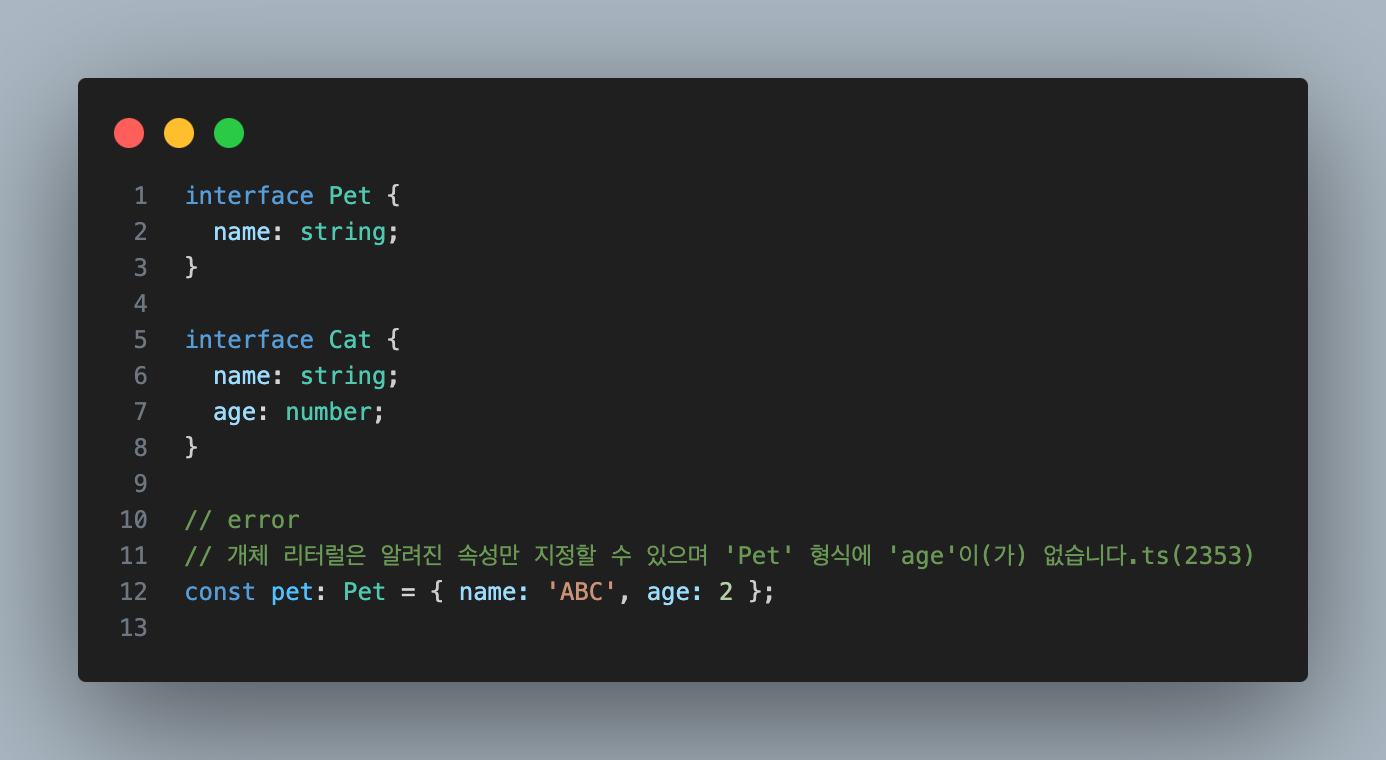
구조적 타이핑 역시 예외는 존재한다.
객체 리터럴을 직접 할당하게 되면 '초과 속성 검사'를 진행한다.
변수를 통해 객체를 전달할 경우, Typescript는 구조적 타입 검사(Structural Typing)를 수행한다.
그러나, 변수를 통하지 않고 객체 리터럴을 직접 할당할 때, 선언된 타입에 없는 초과 속성이 있는지 엄격히 검사한다.
이때는 객체 리터럴의 속성이 인터페이스에 선언된 구조와 정확히 일치해야 한다.
즉, 구조적 타이핑이 적용되지 않는 것이다.
집합의 관점에서 바라보는 인터섹션, 유니온 타입
이제 구조적 타이핑에 대해 간략히 알아보았으므로, 이를 기반으로 유니온 타입(|)과 인터섹션 타입(&)의 기본적인 동작 원리에 대해 알아보자
in 프리미티브 타입
프리미티브 타입을 대상으로 유니온 타입과 인터섹션 타입을 사용하게 될 경우
우리가 평소 알던 수학적인 집합의 개념으로 곧바로 이해할 수 있다.


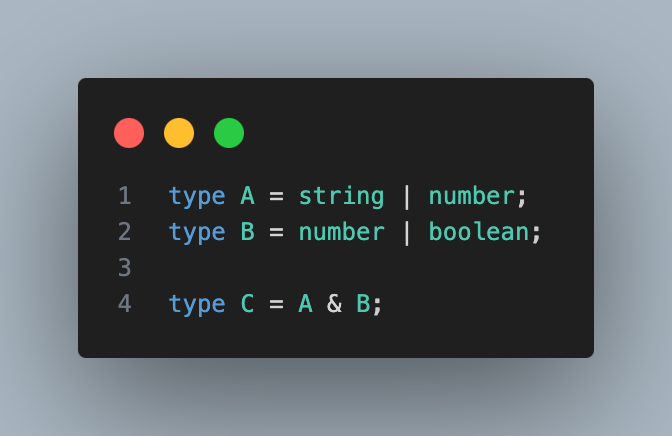 C는 A와 B의 교차 타입이므로 두 타입을 모두 만족하는 교집합을 의미한다.
C는 A와 B의 교차 타입이므로 두 타입을 모두 만족하는 교집합을 의미한다.
그러므로 실제 C의 타입은 number가 된다
in 객체 타입 {key:value}
{key:value} 형태의 객체에 유니온과 인터섹션 타입을 적용하게 되면
집합의 개념과 더불어, TS의 구조적 타이핑 개념이 적용된다.
이러한 특성 때문에 우리가 평소에 알던 수학적인 직관과 다르게 느껴질 수 있다.
1. ‘구조적 타입에서의’ 교집합(인터섹션, &)
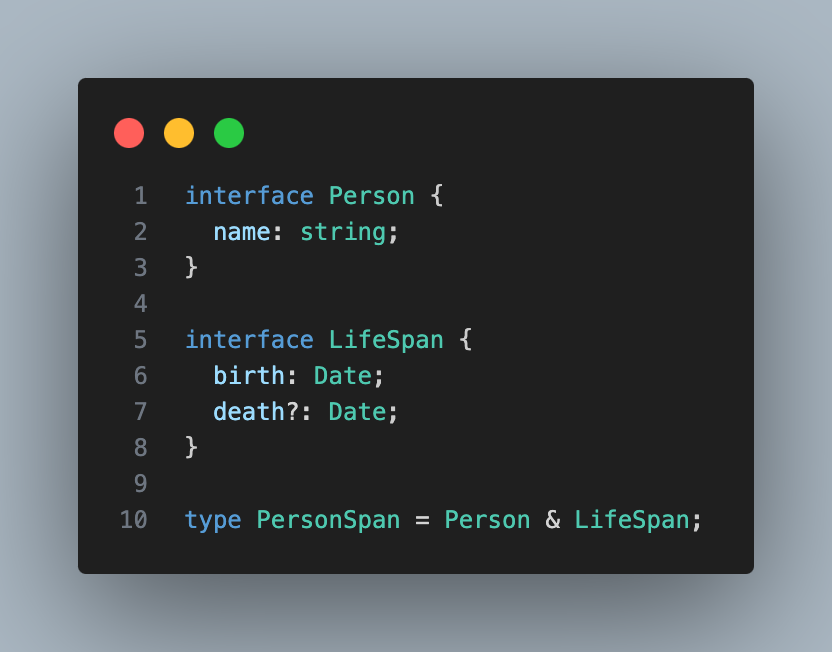
& 연산자는 두 타입의 인터섹션(intersection, 교집합)을 계산한다.
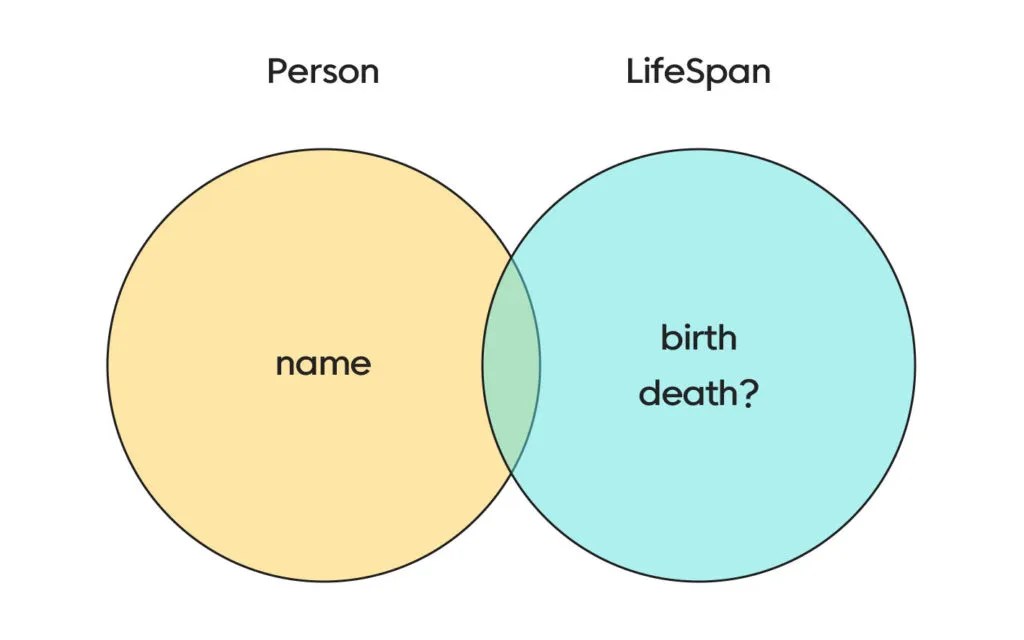
우리가 일반적으로 배워온 관점에 따르면 Person과 LifeSpan은 교집합이 없어 보인다.
서로 겹치는 속성이 없으니까 당연히 PersonSpan 의 타입은 never가 될 것이라고 예상하겠지만
실제로 Person과 Lifespan을 둘 다 가지는 값은 인터섹션 타입에 속하게 된다
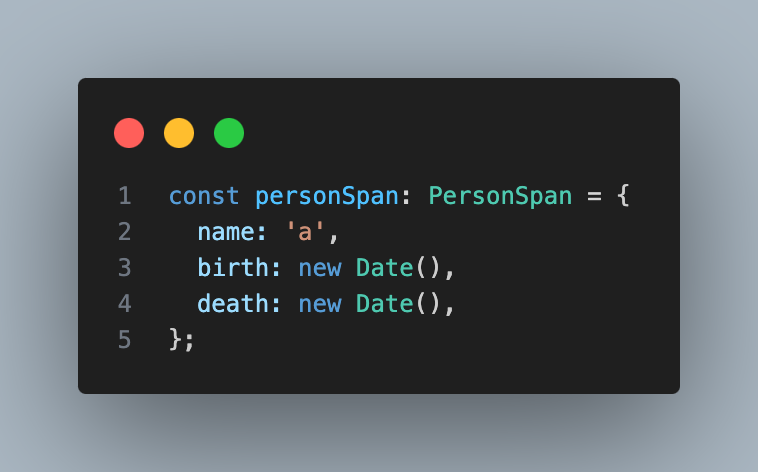
❗❗ 그 이유를 파악하는데 바로 구조적 타이핑의 개념이 필요하다
-
교집합이 되려면 그 교집합을 Person이나 LifeSpan으로 간주해도 둘 다 무리가 없어야 한다.
즉, Person에도 속하고, Life에도 속하는 타입이 교집합이 되는 것이다.
-
이를 가능케 하는 것이 TS의 구조적 타이핑의 특성으로 인해,
'Person과 Lifespan을 둘 다 가지는 값'이 되는 것이다.
즉,Person의 name속성+Lifespan의 birth, death속성을 가진 객체가 된다.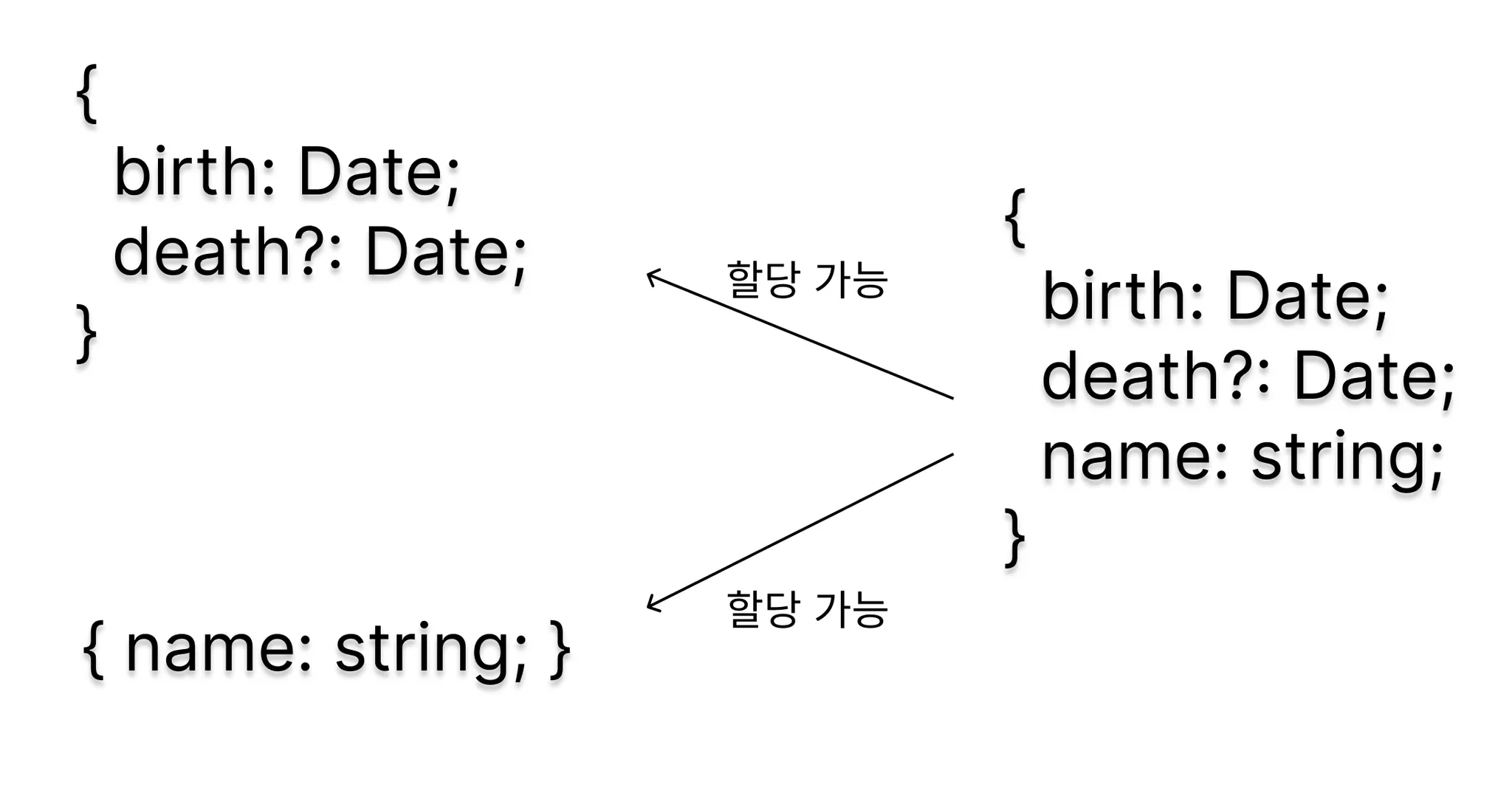
예를 들어, 타입 C가 타입 A와 B의 교차 타입인 A & B 라면 C는 A타입과 B타입의 모든 멤버를 가지고 있는 타입이 되는 것이다.
2. 유니온 타입
유니온 타입은 조금 특이하게도 ‘값’과 ‘속성’으로 사용될 때 각각 차이가 존재한다.
💡 값의 관점
유니온 타입의 ‘값’이 실제로 어떤 구조를 가져야 유효한지를 의미한다.
A | B의 타입에 할당되는 ‘값’은 A 혹은 B 중, 최소한 하나의 구조를 만족하면 되는 것이다.

이는 집합 관점으로 볼 때 유니온 타입은 '합집합'이 되기 때문이다.
따라서 name 속성 or birth,death 속성 중 하나씩만 할당되거나 두 속성이 모두 포함되어도 합집합의 범주에 들어가기 때문에 타입 에러가 발생하지 않는다.
💡 속성의 관점
"속성의 관점"은 유니온 타입에 ’접근’할 때 어떤 속성을 사용할 수 있는지를 의미한다
A | B의 타입에 ‘접근’ 할 때는 A, B 타입 공통으로 존재하는 속성에만 접근할 수 있는 것이다.
이는 유니온 타입에서 안전성을 보장하기 위해 공통 속성만 접근을 허용하기 때문이다.
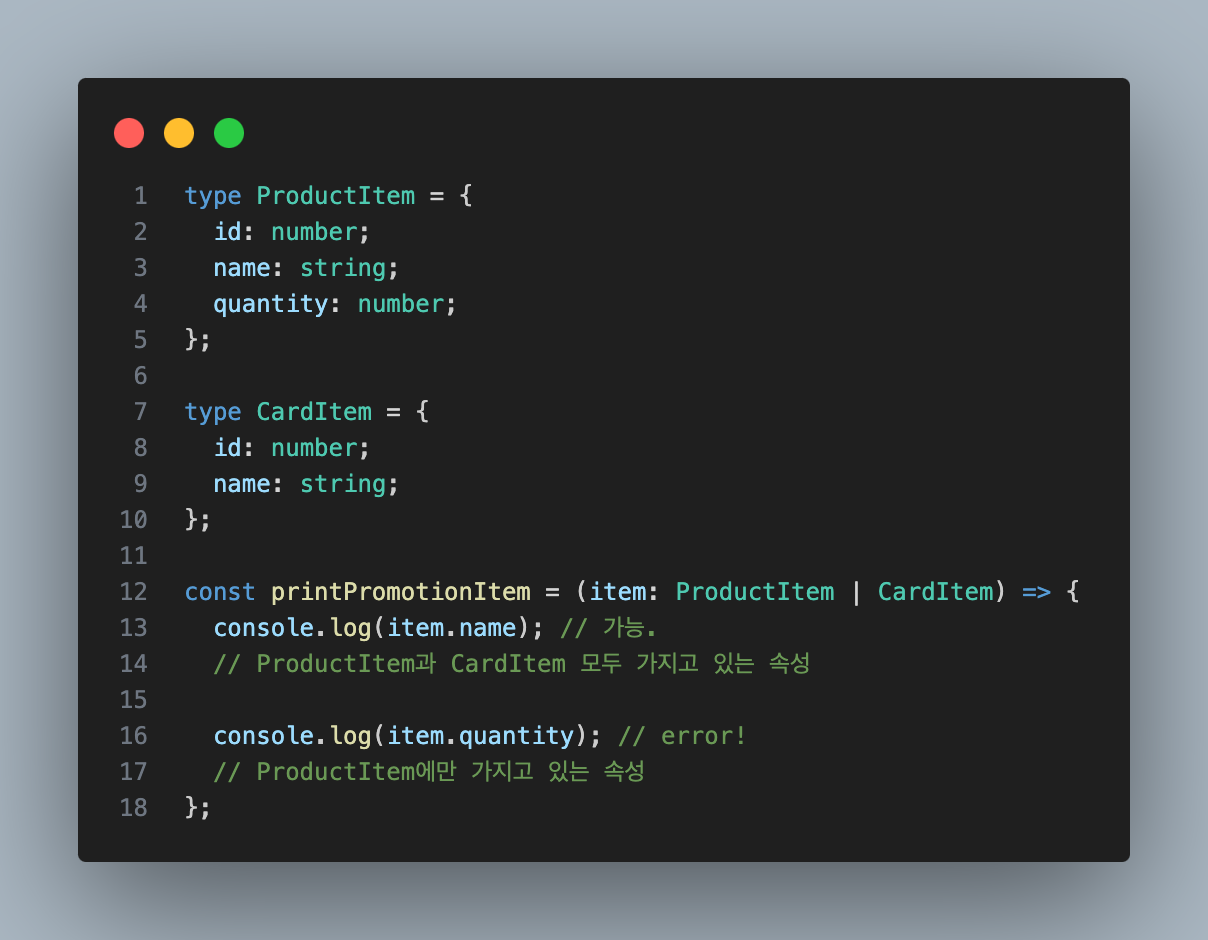
아래 예시는 함수의 인자 item 타입이 ProductItem | CardItem 타입이다
그러므로 printPromotionItem 함수 내부에서 .quantity에 접근하면 컴파일에러가 발생한다.
이는 .quantity가 CardItem에만 존재하기 때문이다.
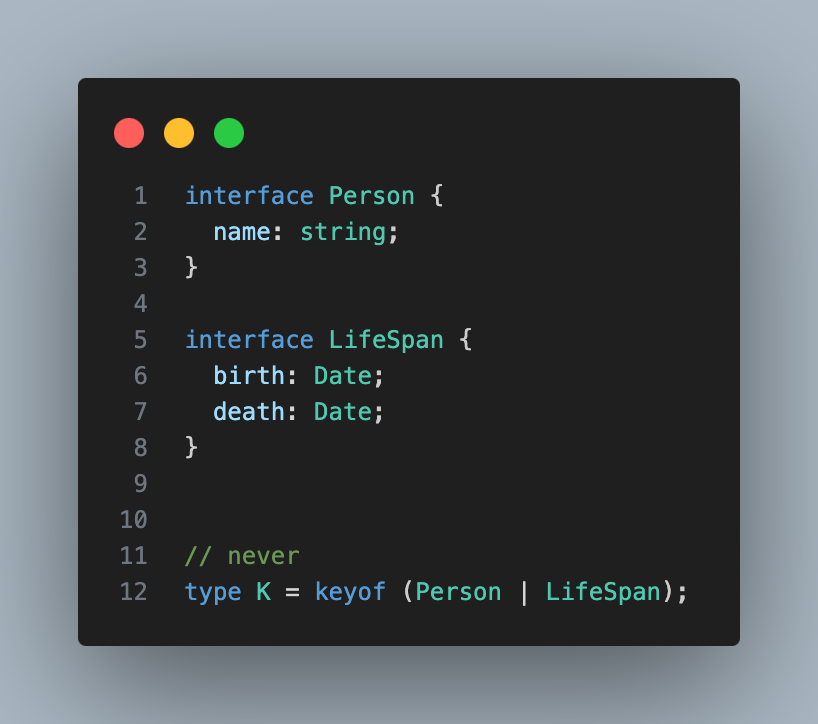
아래 K의 타입은 never가 된다
-
keyof는 객체의 키값들을 유니온 타입으로 추론한다.
-
여기서 keyof의 대상이 되는 객체는
Person | LifeSpan타입이다. -
그러므로
Person | LifeSpan타입에 ‘접근’하면 공통된 속성에만 접근이 가능하다 -
그러나 공통된 속성이 없으므로 K는 never타입이 되는 것이다.
+번외) 구조적 타이핑 관점에서 부분집합 바라보기
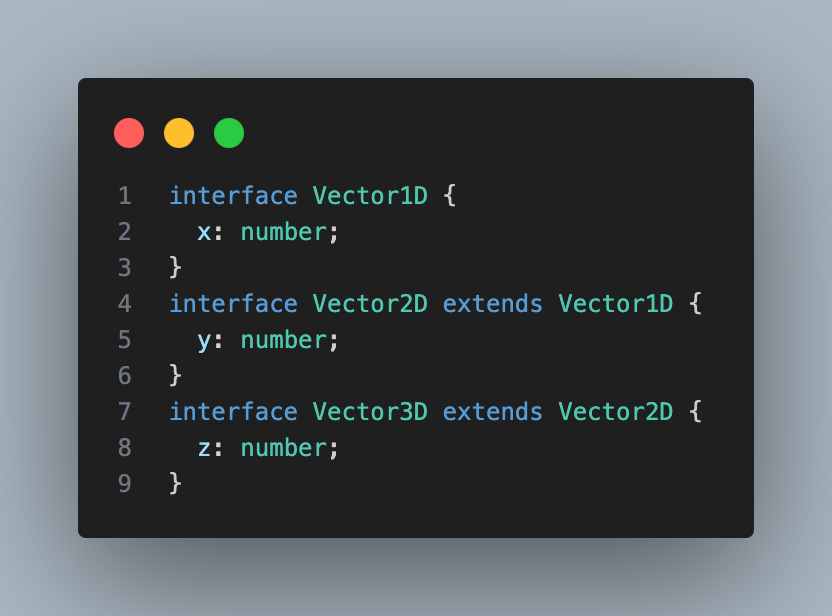
위의 구조를 시각화 해보면 다음과 같다
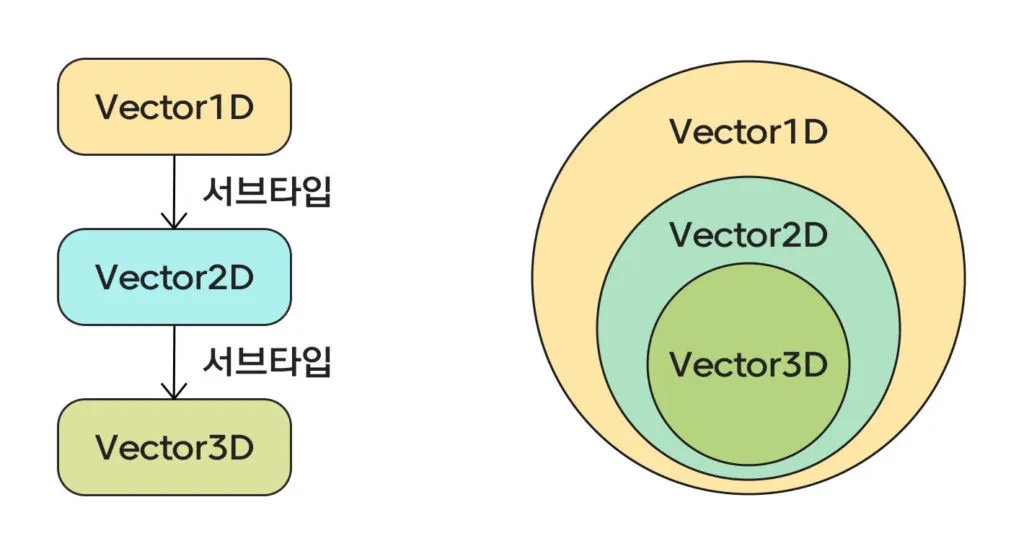
왜 Vector1D가 Vector2D를 포함하고, Vector2D가 Vector3D를 포함하는 걸까?
구조적 타이핑 관점에서 바라보면
-
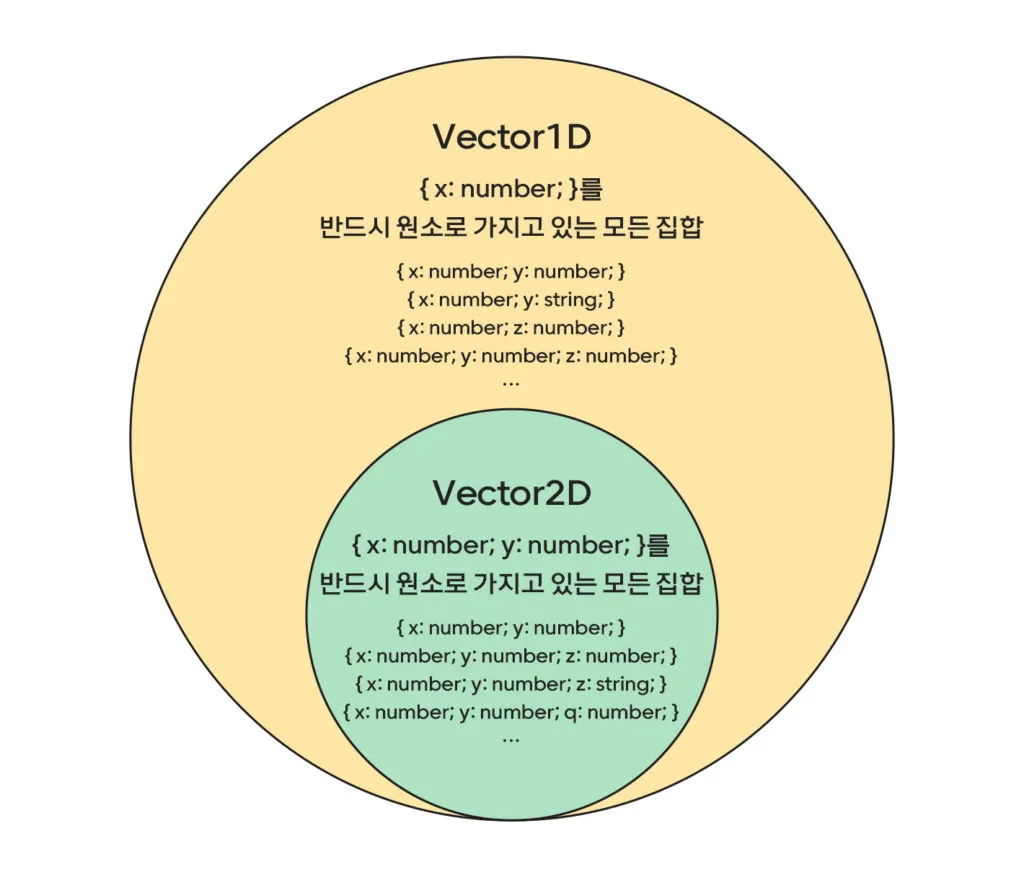
Vector1D에 해당하는 타입은
{ x: number; }만 만족 시킨다면, 그 외에 추가적인 속성을 가져도 무방하다. -
이는 곧 Vector1D라는 타입 정의를 통해 만든 모든 타입에는, Vector2D로 만들 수 있는 모든 타입또한 포함되는 것이다.


너무 깔끔하고 좋은 글이네요... 👍 잘 읽고 갑니다 ✌️✌️