논문 링크 : ImageNet classification with deep convolutional neural networks
Abstract
1.2 million개의 고해상도 이미지를 1000개의 클래스로 분류하는 deep convolutional neural network를 훈련시켰다. 훈련 속도를 증가시키기 위해 non-saturating neurons를 사용하고, convolution 연산에는 GPU를 사용하였다. fully-connected layer에서 overfitting을 방지하기 위해 regularization 방법으로 dropout을 사용하였다.
- saturating : 기울기가 0이 되는 현상 (가중치 업데이트가 되지 않는다.)
- dropout : 연결망에서 뉴런을 제거하는 기법
Introduction
Object Detection
현실의 Object는 변동성이 매우 크다. 따라서 Object detection을 하기 위해서는 large training set과 large learning capacity가 필요하다. Object detection은 복잡하기 때문에 data set에 없는 모든 데이터에 대해 prior knowledge가 필요하다.
learning capacity : 모델이 학습할 수 있는 parameter 개수
CNNs (Convolutional neural networks)
CNN은 capacity를 depth와 breadth을 통해 조정할 수 있고, 이미지의 특징(stationarity of statistics and locality of pixel dependencies)에 대해 대부분 정확한 가정을 한다.
- stationarity of statistics(정상성) : 통계적 특성이 시간에 따라 변하지 않는다. (stationarity를 가지는 이미지는 위치 관계없이 동일한 패턴 반복)
- locality of pixel dependecies(지역성) : 주변 점들만 의미있게 연결된다.
참고 링크 : https://kau-deeperent.tistory.com/143
CNN은 비슷한 크기의 standard feedforward neural networks(순방향 신경망, 다층 퍼셉트론)보다 파라미터 개수가 적어 학습하기 쉽고, 이론적으로 best-performance는 아주 약간만 나쁘다. CNN의 장점에도 불구하고 고화질의 큰 이미지에 사용하기는 매우 많은 비용이 필요했다. 하지만 최근 2D Convolution 연산에 최적화된 강력한 GPU와 mageNet과 같이 라벨링된 충분한 dataset은 CNN을 가능하게 만들었다.
결과
dataset에 이전보다 좋은 결과를 보이는 매우 큰 CNN 모델을 학습시켰다. 최종적으로 모델은 5개의 Convolutional layers와 3개의 fully-connected layers로 이루어진다. 각 layer는 전체 파라미터의 1%를 가지지만 한 layer라도 제거시 성능이 떨어지는 것으로 보아 모델의 depth가 중요한 것으로 보인다.
The Dataset
사용한 dataset
ImageNet은 15 million개의 라벨링 된 고해상도 이미지 집합이다. 대략 22000개의 카테고리가 있다. ILSVRC는 Large-scale visual recognition 대회로 ImageNet의 부분 dataset을 사용한다. ILSVRC-2010 버전이 실험에 사용한 dataset이다.
error rate
ImageNet은 일반적으로 top-1, top-5 error를 사용한다.
top-1 error: 가장 확률이 높다고 생각한 카테고리가 정답이 아닌 경우.
top-5 error : 가장 확률이 높다고 생각한 5가지 카테고리에 정답이 없는 경우.
이미지 사전처리
ImageNet의 data는 해상도가 고정되어있지 않다. 필요한 데이터는 256*256의 해상도를 가지는 data이다. 따라서 직사각형의 짧은 쪽을 256에 맞춘(rescaled) 후 가운데 256*256을 잘라 사용하였다.
subtracting the mean activity over the training set from each pixel.
so we trained our network on the (centered) raw RGB values of the pixels.학습 데이터의 평균 픽셀값을 각 픽셀에서 빼는 전처리만 해주었다.
The Architecture
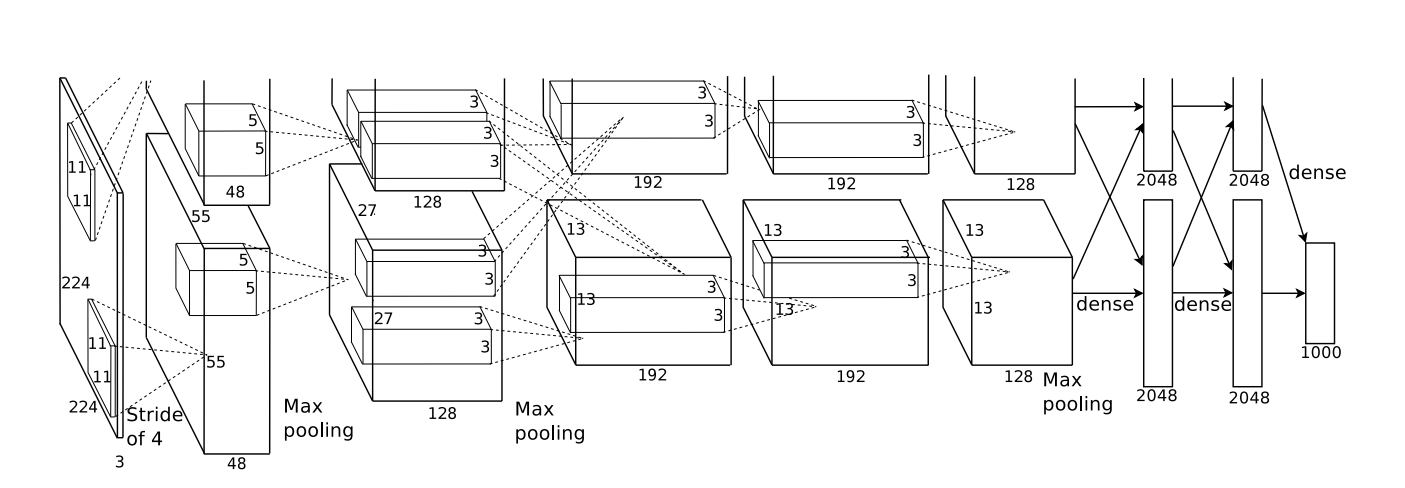
network구조를 요약하면 총 8개의 학습 layer라고 할 수 있다. 5개의 layer가 convolutional layer이고 3개의 layer가 fully-connected layer이다. 네트워크의 다른 특징은 다음과 같다.
ReLU Nonlinearity
뉴런의 결과를 모델링하는 일반적인 는 탄젠트 함수, 시그모이드 함수이다. 그러나 경사하강법을 사용해 훈련할 때 이러한 satrating nonlinear함수는 ReLU 같은 non-saturating nonlinear 함수를 사용할 때 보다 학습 시간이 더 걸린다. 일반적인 saturating neuron 모델을 사용해서는 연구가 불가능했을 것이다.
non-saturating 함수를 제안한 것은 처음이 아니다. 이전의 연구는 overfitting 을 방지하는 것이 주 목적이었다. 하지만 AlexNet은 학습 속도를 가속하기 위해 ReLU를 사용한다. 빠른 학습 속도는 큰 데이터를 학습한 큰 모델의 성능에 영향을 미친다.
- ReLU는
max연산 하나만 수행하면 되므로 속도가 빠르다.- ReLU의
최대 기울기는 1로 최대 기울기가 0.25인 시그모이드 함수에 비해 학습 속도가 더 빠르다.
Multiple GPUs
GTX 580 GPU의 메모리는 3GB로 네트워크 학습 크기를 제한한다. 120 만장의 학습 데이터는 네트워크를 학습하기에 충분하지만, GPU에는 너무 크다. 따라서 GPU 2개를 병렬적으로 사용하였다. 각 GPU에 절반의 뉴런을 할당하고 GPU간 소통은 특정 층에서만 일어난다. 예를 들어 layer 3에서는 layer 2의 모든 결과를 받아오지만, layer 4에서는 같은 GPU 내부의 layer3에서만 결과를 받아온다. GPU를 병렬적으로 사용하여 top-1, top-5 오류를 줄이고 학습 시간을 줄일 수 있었다.
Local Response Normalization
ReLU는 saturating 방지를 위해 입력을 normalization 할 필요가 없다. 하지만 값이 커지는 경우 해당 픽셀이 주변 픽셀에 미치는 영향을 방지하기 위해 normalization이 필요하다.
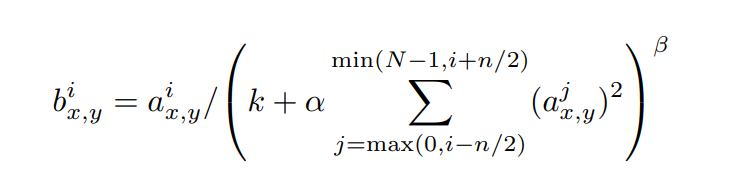
위의 식을 사용하여 normalization을 한다. N은 현재 layer에 존재하는 커널의 개수이다. k, n, , 는 하이퍼 파라미터이다. k = 2, n = 5, = 10-4, = 0.75를 사용했다. 모든 층에 normalization을 적용한 것은 아니고, 특정 층에만 적용했다. 이를 통해 top-1, top-5 오류를 줄일 수 있었다.
LRN 설명 예제
LRN에서 주변 픽셀은 다른 채널의 같은 위치를 의미한다. 즉 현재 채널 앞뒤의 n개의 채널의 같은 위치 픽셀을 사용하여 nomarlization을 하는 것이다. (같은 위치의 앞뒤 채널을 사용해 avg normalization 하는 것처럼 동작한다.)
Overlapping Pooling
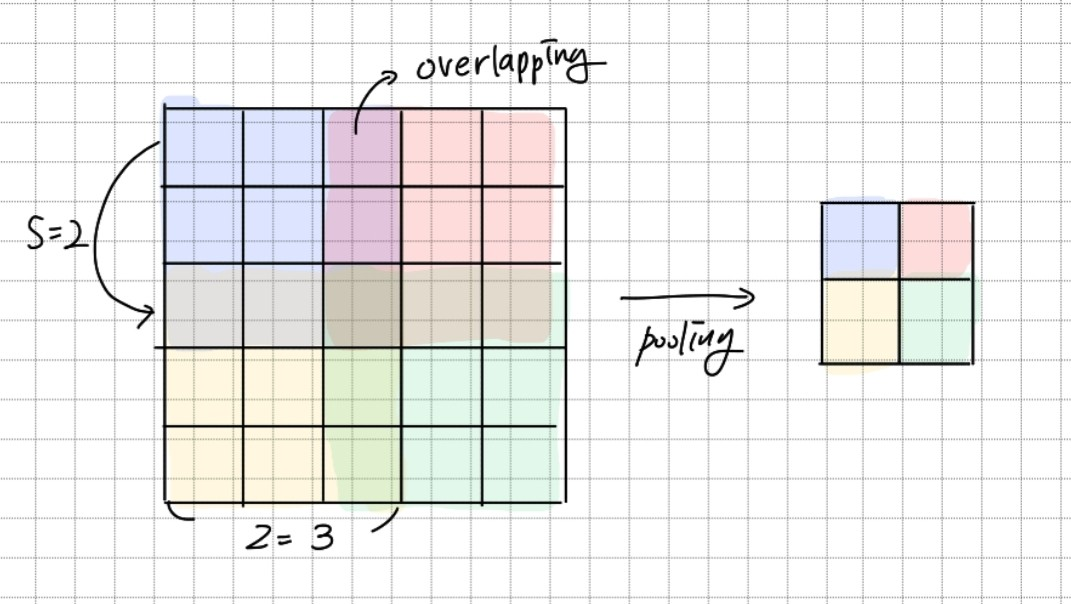
Pooling layer는 같은 커널의 주변 그룹을 요약한다. 일반적으로 pooling unit은 겹치지 않는다. pooling unit의 크기를 z*z라고 하고, stride를 s라고 하면 s = z인 경우 겹치는 부분이 생기지 않는다. 만약 s < z 라면 겹치는 같이 겹치는 부분이 생긴다. s = 2, z = 3 을 사용하여 ovelapping pooling을 사용하였다. 그 결과 top-1, top-5 오류가 줄고 overlapping을 사용하지 않을 때보다 overfit이 조금 줄었다.
s = 2, z = 3인 Overlapping MAX Pooling을 사용한다.
Overall Architecture
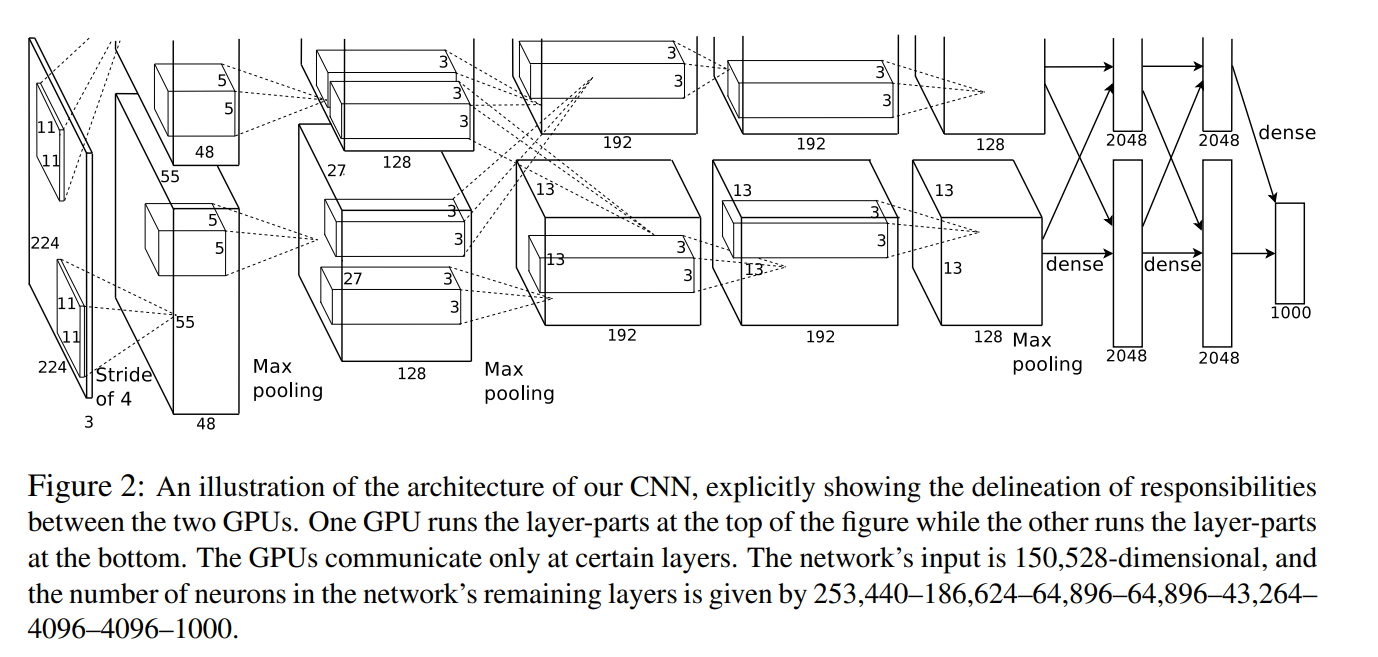
총 8 layer로 앞의 5 layer는 convolutional layer이고 뒤의 3 layer는 fully-connected layer이다. 마지막 fully-connected layer의 결과는 1000-way softmax 함수로 들어가 이미지를 1000개의 카테고리로 분류한다.
2,4,5번째 convolution layer는 같은 GPU내의 이전 layer 값만 입력받는다. 3번째 convolution layer와 fully-connected layer는 GPU와 상관없이 이전 layer의 전체 값을 입력받는다.
LRN은 1, 2번째 convolution layer 뒤에 적용되고, max-pooling layer는 LRN 뒤와 5번째 convolution layer 뒤에 적용된다. ReLU는 모든 층의 결과에 적용된다.
Reducing Overfitting
Data Augmentation
Overfitting을 방지하는 가장 쉬운 방법은 데이터를 증가시키는 것이다. 아래와 같이 원본 데이터의 특성을 유지하는 2가지 변형 방법을 사용하여 학습 데이터를 늘렸다. GPU가 이전 batch를 학습하는 동안 CPU가 이미지를 변형하기 때문에 효율적이다.
-
translation + horizontal reflection
첫번째 방법은translation과horizontal reflection을 이용한다. 먼저 256*256 크기의 이미지에서224*224 사이즈의 patch를 잘라낸다. 하나의 이미지에서 총 1024개의 patch를 만들 수 있다. 이후 patch를horizontal reflaction시킨 새로운 patch를 만들어 데이터에 추가한다. 이 방법을 통해 데이터를 2048배로 늘릴 수 있다.
테스트에서는 원본 이미지의 상하좌우, 중앙에서 224*224 사이즈의 patch를 만든다. 이렇게 만든 5개의 horizontal reflaction까지 총 10개의 patch를 테스트에 사용한다. 10개의 patch의softmax 함수값의 평균으로 어떤 카테고리에 속하는지 예측한다. -
using PCA (color jittering)
PCA는 주성분 분석으로 이를 사용하여 이미지 전체 픽셀에 대해 주성분을 분석한다. 찾은 주성분에random variable을 곱해 원래 픽셀에 더하는 방식으로 새로운 데이터를 만든다.

a는 평균값이 0이고 표준편차가 0.1인Gaussian 분포를 따르는random value로 고정된 값이 아니라 학습 단계에서 변화하는 값이다. 이 방법은 조명의 세기와 색이 변화해도 변하지 않는 객체의identity를 잡아낼 수 있고,top-1 error rate를 1% 감소시켰다.
Dropout
여러 다른 모델을 학습시켜 그 결과를 종합하여 예측하는 것은 테스트 오류를 줄이는 성공적인 방법이다. 하지만 모델의 크기가 큰 경우 너무 많은 비용이 필요하다. Dropout은 이를 효과적으로 할 수 있게 한다.
dropout은 hidden neuron의 값을 0.5 확률로 0으로 만든다. dropout에 의해 0이 된 뉴런은 forward pass, backward propagation에 참여하지 않는다. 즉, 모델은 매번 다른 Architecture를 가지면서 weights를 공유하게 되는 것이다. 이 방법은 뉴런간 상호의존성을 없애 robust(이상값에 영향을 적게 받음)한 특징을 가진다.
테스트에서는 모든 뉴런을 사용하지만, 각 뉴런에 0.5를 곱하여 사용한다. AlexNet에서는 앞 2개의 fully-connected layer에 dropout이 사용되었다. Dropout은 overfitting을 방지하였지만, 수렴까지 반복 횟수는 2배로 늘었다.
dropout 참고 자료
각 뉴런은 학습 중에 0.5 확률로 비활성화 된다. 따라서 테스트에서는 이를 고려하여 모든 뉴런에 0.5를 곱한 값을 사용한다.
Details of learning
2개의 NVIDIA GTX 580 3GB를 사용하여 1.2M개의 이미지를 90번 학습하였고, 5~6일이 걸렸다. 학습이 끝나기까지 learning rate는 3번 업데이트 되어 최종 learning rate는 0.00001이었다.
최적화 방법
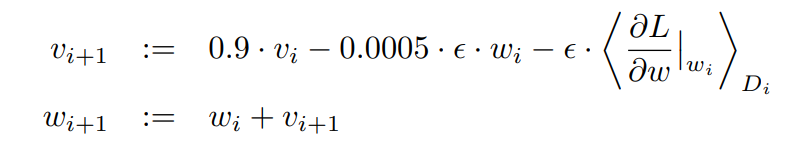
모델을 훈련시키는데 확률적 경사 하강법을 사용하였다. batch 사이즈는 128이고 momentum은 0.9, weight decay는 0.0005이다. 위의 수식을 사용하여 weight를 업데이트 한다. 는 momentum 변수이고 ε는 learning rate, D는 batch의 평균을 의미한다.
- momentum : weight 업데이트 시 이전 업데이트 방향을 반영한다.
- weight decay : weight 값이 너무 커지지 않도록 하기 위해 Loss function에 weight 값에 대한 패널티를 추가한다.
weights 초기화
모든 weights는 N(0, 0.12)를 따르는 값으로 초기화 한다.
2, 4, 5번째 Convolution layer와 Fully-connected layer의 bias는 1로 초기화 한다. 이는 ReLU 함수의 입력을 양수로 만들어 초기 학습을 가속화하는 역할을 한다. 나머지 bias는 0으로 초기화한다.
learning rate
learning rate는 모든 층에 같은 값을 적용한다. learning rate는 처음에 0.001에서 시작하여 validation error rate가 더 감소하지 않을 때마다 10으로 나누어 사용한다.
Results
ILSVRC 결과
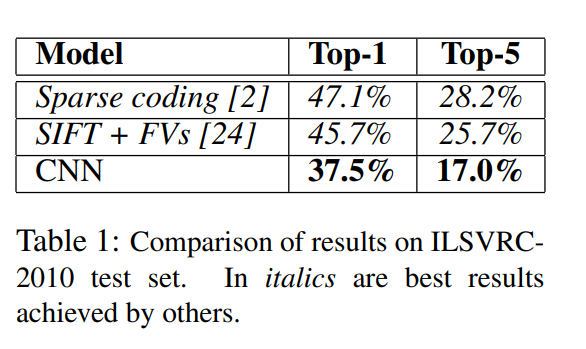
ILSVRC-2010에서는 Top-1 오류율은 37.5%, Top-5 오류율은 17.0%로 가장 좋은 성능을 보였다.
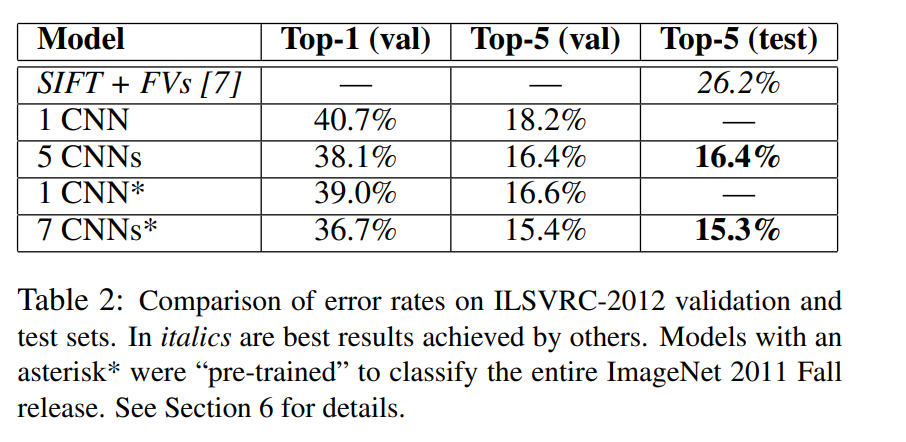
ILSVRC-2012에서 AlexNet(CNN)은 Top-5 오류율 18.2%를 보였다. CNNs는 5개의 CNN의 결과를 평균내는 모델이다. CNNs*는 ImageNet Fall 2011을 위해 만든 CNN 뒤에 6개의 Convolutional layer를 추가하고 fine-tunning한 모델이다. 마지막으로 CNNs*는 CNNs와 CNN*의 결과를 평균내는 모델이다. 각 모델의 성능은 위 표와 같다.
ILSVRC-2012의 테스트 데이터는 label이 모두 공개되지 않아 test error를 모두 표시할 수 없다. 실험 결과 validation error와 test error의 차이가 거의 없으므로, 둘을 같은 결과로 사용한다.
Qualitative Evaluations

위의 이미지는 첫번재 convolutional kernels이 학습한 내용이다. 위의 3줄은 GPU1에서, 밑의 3줄은 GPU2에서 학습한 결과다. GPU1은 색 정보가 거의 없고 GPU2는 색 정보가 많은 것을 확인할 수 있다. weight의 초기화와 상관없이 매번 이런 현상이 발생하였다.

AlexNet이 추론한 결과이다. 위의 4개는 맞게 추론한 것으로 객체가 중앙에 있지 않아도 추론할 수 있고, 5개가 모두 그럴 듯한 카테고리가 나온다. 반면 아래의 4개는 잘못추론한 것이지만 이미지에서 어느 것이 검출하고자 하는 것인지 모호함이 있다.

가장 왼쪽의 이미지는 훈련 데이터에서 가져온 이미지이고 나머지 여섯개의 이미지는 왼쪽 이미지와 가장 비슷한 이미지를 가져온 것이다. 이때 비슷하다는 것은 마지막 Hidden layer의 값을 클리드 거리를 사용해 거리 계산했을 때 가까움을 의미한다. 찾은 이미지를 단순 픽셀값으로 L2 norm을 계산하면 가깝지 않다. 이는 AlexNet이 단순 픽셀로 분류를 하는 것이 아님을 보여준다.
Discussion
AlexNet은 중간에 layer를 한 층만 없애도 top-1 에러가 2% 증가하는 것으로 보아 모델의 depth가 매우 중요함을 알 수 있다. AlexNet이 매우 놀라운 결과를 보여줬지만, 인간의 시각에 비하면 많은 노력이 필요하다. 궁극적으로는 비디오에 크고 깊은 모델을 적용하고 싶다고 한다.
참고
- dropout : https://heytech.tistory.com/127
- 정상성과 지역성 : https://kau-deeperent.tistory.com/143
- Local Response Normalization : https://towardsdatascience.com
- color jittering : https://nmhkahn.github.io/CNN-Practice
- PCA : https://angeloyeo.github.io/2019/07/27/PCA.html
- Dropout : https://heytech.tistory.com/127
- weight decay : https://light-tree.tistory.com/216
